基础内容
Swift 是一门全新的用于开发 iOS, OS X 以及 watchOS 应用的编程语言。不过,如果你有 C 或者Objective-C 语言开发经验的话,Swift 的许多地方都会让你感到熟悉。
Swift 为所有 C 和 Objective-C 的类型提供了自己的版本,包括整型值的 Int ,浮点数值的 Double 和 Float ,布尔量值的 Bool ,字符串值的 String 。如同集合类型中描述的那样, Swift 同样也为三个主要的集合类型提供了更高效的版本, Array , Set 和 Dictionary 。
和 C 一样,Swift 用变量存储和调用值,通过变量名来做区分。Swift 中也大量采用了值不可变的变量,它们就是所谓的常量,但是它们比 C 中的常量更加给力。当你所处理的值不需要更改时,使用常量会让你的代码更加安全、简洁地表达你的意图。
除了我们熟悉的类型以外,Swift 还增加了 Objective-C 中没有的类型,比如元组。元组允许你来创建和传递一组数据。你可以利用元组在一个函数中以单个复合值的形式返回多个值。
Swift 还增加了可选项,用来处理没有值的情况。可选项意味着要么“这里有一个值,它等于 x”要么“这里根本没有值”。可选项类似于 Objective-C 中的 nil 指针,但是不只是类,可选项也可以用在所有的类型上。可选项比 Objective-C 中的 nil 指针更安全、更易读,他也是 Swift 语言中许多重要功能的核心。
可选项充分证明了 Swift 是一门类型安全的语言。Swift 帮助你明确代码可以操作值的类型。如果你的一段代码预期得到一个 String ,类型会安全地阻止你不小心传入 Int 。在开发过程中,这个限制能帮助你在开发过程中更早地发现并修复错误。
1 常量和变量
常量和变量把名字(例如 maximumNumberOfLoginAttempts 或者 welcomeMessage )和一个特定类型的值(例如数字 10 或者字符串 “Hello”)关联起来。常量的值一旦设置好便不能再被更改,然而变量可以在将来被设置为不同的值。
1.1 声明常量和变量
常量和变量必须在使用前被声明,使用关键字 let 来声明常量,使用关键字 var 来声明变量。这里有一个如何利用常量和变量记录用户登录次数的栗子:
let maximumNumberOfLoginAttempts = 10
var currentLoginAttempt = 0
这段代码可以读作:
“声明一个叫做 maximumNumberOfLoginAttempts 的新常量,并设置值为 10 。然后声明一个叫做 currentLoginAttempt 的新变量, 并且给他一个初始值 0。”
在这个栗子中,登录次数允许的最大值被声明为一个常量,因为最大值永远不会更改。当前尝试登录的次数被声明为一个变量,因为这个值在每次登录尝试失败之后会递增。
你可以在一行中声明多个变量或常量,用逗号分隔:
var x = 0.0, y = 0.0, z = 0.0
var a = 0, b = "0", c = true
在你的代码中,如果存储的值不会改变,请用 let 关键字将之声明为一个常量。只有储存会改变的值时才使用变量。
1.2 类型标注
你可以在声明一个变量或常量的时候提供类型标注,来明确变量或常量能够储存值的类型。添加类型标注的方法是在变量或常量的名字后边加一个冒号,再跟一个空格,最后加上要使用的类型名称。
下面这个栗子给一个叫做 welcomeMessage 的变量添加了类型标注,明确这个变量可以存储 String 类型的值。
var welcomeMessage: String
声明中的冒号的意思是“是…类型”,所以上面的代码可以读作:
“声明一个叫做 welcomMessage 的变量,他的类型是 String ”
我们说“类型是 String ”就意味着“可以存储任何 String 值”。也可以理解为“这类东西”(或者“这种东西”)可以被存储进去。
现在这个 welcomeMessage 变量就可以被设置到任何字符串中而不会报错了:
welcomeMessage = "Hello"
你可以在一行中定义多个相关的变量为相同的类型,用逗号分隔,只要在最后的变量名字后边加上类型标注。
var red, green, blue: Double
实际上,你并不需要经常使用类型标注。如果你在定义一个常量或者变量的时候就给他设定一个初始值,那么 Swift 就像类型安全和类型推断中描述的那样,几乎都可以推断出这个常量或变量的类型。在上面 welcomeMessage 的栗子中,没有提供初始值,所以 welcomeMessage 这个变量使用了类型标注来明确它的类型而不是通过初始值的类型推断出来的。
1.3 命名常量和变量
常量和变量的名字几乎可以使用任何字符,甚至包括 Unicode 字符:
let π = 3.14159
let 你好 = "你好世界"
let 🐶🐮 = "dogcow"
常量和变量的名字不能包含空白字符、数学符号、箭头、保留的(或者无效的)Unicode 码位、连线和制表符。也不能以数字开头,尽管数字几乎可以使用在名字其他的任何地方。
一旦你声明了一个确定类型的常量或者变量,就不能使用相同的名字再次进行声明,也不能让它改存其他类型的值。常量和变量之间也不能互换。
如果你需要使用 Swift 保留的关键字来给常量或变量命名,可以使用反引号( ` )包围它来作为名称。总之,除非别无选择,避免使用关键字作为名字除非你确实别无选择。
你可以把现有变量的值更改为其他相同类型的值。在这个栗子中 friendlyWelcome 的值从 “Hello!” 改变为 “Bonjour!”
var friendlyWelcome = "Hello!"
friendlyWelcome = "Bonjour!"
// friendlyWelcome 现在是 "Bonjour!"
不同于变量,常量的值一旦设定则不能再被改变。尝试这么做将会在你代码编译时导致报错:
let languageName = "Swift"
languageName = "Swift++"
// this is a compile-time error - languageName cannot be changed
1.4 输出常量和变量
你可以使用 print(_:separator:terminator:) 函数来打印当前常量和变量中的值。
print(friendlyWelcome)
// 输出 "Bonjour!"
print(_:separator:terminator:) 是一个用来把一个或者多个值用合适的方式输出的全局函数。比如说,在 Xcode 中 print(_:separator:terminator:) 函数输出的内容会显示在Xcode的 “console” 面板上。 separator(多个输出中间的分隔符) 和 terminator(输出值末尾的字符) 形式参数有默认值,所以你可以在调用这个函数的时候忽略它们。默认来说,函数通过在行末尾添加换行符来结束输出。要想输出不带换行符的值,那就传一个空的换行符作为结束——比如说, print(someValue, terminator: "") 。更多关于带有默认值的形式参数信息,见默认形式参数值。
Swift 使用字符串插值 的方式来把常量名或者变量名当做占位符加入到更长的字符串中,然后让 Swift 用常量或变量的当前值替换这些占位符。将常量或变量名放入圆括号中并在括号前使用反斜杠将其转义:
print("The current value of friendlyWelcome is \(friendlyWelcome)")
// 输出 "The current value of friendlyWelcome is Bonjour!"
2 注释
使用注释来将不需要执行的文本放入的代码当中,作为标记或者你自己的提醒。当 Swift 编译器在编译代码的时候会忽略掉你的注释。
Swift 中的注释和 C 的注释基本相同。单行注释用两个斜杠开头( // ): 多行的注释以一个斜杠加一个星号开头( /* ),以一个星号加斜杠结尾( */ )。 和 C 中的多行注释不同的是, Swift 语言中的多行的注释可以内嵌在其它的多行注释之中,你可以在多行注释中先开启一个注释块,接着再开启另一个注释块。然后关闭第二个注释块,再关闭第一个注释块。
/* 这是第一个多行注释的开头
/* 这是第二个嵌套在内的注释块 */
这是第一个注释块的结尾*/
内嵌多行注释,可以便捷地注释掉一大段代码块,即使这段代码块中已经有了多行注释。
3 分号
和许多其他的语言不同,Swift 并不要求你在每一句代码结尾写分号( ; ),当然如果你想写的话也没问题。总之,如果你想在一行里写多句代码,分号还是需要的。
let cat = "🐱"; print(cat)
// 输出 "🐱"
4 整数
整数就是没有小数部分的数字,比如 42 和 -23 。整数可以是有符号(正,零或者负),或者无符号(正数或零)。
Swift 提供了 8,16,32 和 64 位编码的有符号和无符号整数,这些整数类型的命名方式和 C 相似,例如 8 位无符号整数的类型是 UInt8 ,32 位有符号整数的类型是 Int32 。与 Swift 中的其他类型相同,这些整数类型也用开头大写命名法。
4.1 整数范围
你可以通过 min 和 max 属性来访问每个整数类型的最小值和最大值:
let minValue = UInt8.min // 最小值是 0, 值的类型是 UInt8
let maxValue = UInt8.max // 最大值是 255, 值得类型是 UInt8
这些属性的值都是自适应大小的数字类型(比如说上边栗子里的 UInt8 )并且因此可以在表达式中与在其他相同类型值同用。
4.2 Int
在大多数情况下,你不需要在你的代码中为整数设置一个特定的长度。Swift 提供了一个额外的整数类型: Int ,它拥有与当前平台的原生字相同的长度。
- 在32位平台上, Int 的长度和 Int32 相同。
- 在64位平台上, Int 的长度和 Int64 相同。
除非你需操作特定长度的整数,否则请尽量在代码中使用 Int 作为你的整数的值类型。这样能提高代码的统一性和兼容性,即使在 32 位的平台上, Int 也可以存 -2,147,483,648 到 2,147,483,647 之间的任意值,对于大多数整数区间来说完全够用了。
4.3 UInt
Swift 也提供了一种无符号的整数类型, UInt ,它和当前平台的原生字长度相同。
- 在32位平台上, UInt 长度和 UInt32 长度相同。
- 在64位平台上, UInt 长度和 UInt64 长度相同。
只在的确需要存储一个和当前平台原生字长度相同的无符号整数的时候才使用 UInt 。其他情况下,推荐使用 Int ,即使已经知道存储的值都是非负的。如同类型安全和类型推断中描述的那样,统一使用 Int 会提高代码的兼容性,同时可以避免不同数字类型之间的转换问题,也符合整数的类型推断。
5 浮点数
浮点数是有小数的数字,比如 3.14159 , 0.1 , 和 -273.15 。 浮点类型相比整数类型来说能表示更大范围的值,可以存储比 Int 类型更大或者更小的数字。Swift 提供了两种有符号的浮点数类型。
- Double代表 64 位的浮点数。
- Float 代表 32 位的浮点数。
Double 有至少 15 位数字的精度,而 Float 的精度只有 6 位。具体使用哪种浮点类型取决于你代码需要处理的值范围。在两种类型都可以的情况下,推荐使用 Double 类型。
6 类型安全和类型推断
Swift 是一门类型安全的语言。类型安全的语言可以让你清楚地知道代码可以处理的值的类型。如果你的一部分代码期望获得 String ,你就不能错误的传给它一个 Int 。
因为 Swift 是类型安全的,他在编译代码的时候会进行类型检查,任何不匹配的类型都会被标记为错误。这会帮助你在开发阶段更早的发现并修复错误。
当你操作不同类型的值时,类型检查能帮助你避免错误。当然,这并不意味着你得为每一个常量或变量声明一个特定的类型。如果你没有为所需要的值进行类型声明,Swift 会使用类型推断的功能推断出合适的类型。通过检查你给变量赋的值,类型推断能够在编译阶段自动的推断出值的类型。
因为有了类型推断,Swift 和 C 以及 Objective-C 相比,只需要少量的类型声明。其实常量和变量仍然需要明确的类型,但是大部分的声明工作 Swift 会帮你做。
在你为一个变量或常量设定一个初始值的时候,类型推断就显得更加有用。它通常在你声明一个变量或常量同时设置一个初始的字面量(文本)时就已经完成。(字面量就是会直接出现在你代码中的值,比如下边代码中的 42 和 3.14159 。)
举个栗子,如果你给一个新的常量设定一个 42 的字面量,而且没有说它的类型是什么,Swift 会推断这个常量的类型是 Int ,因为你给这个常量初始化为一个看起来像是一个整数的数字。
let meaningOfLife = 42
// meaningOfLife is inferred to be of type Int
同样,如果你没有为一个浮点值的字面量设定类型,Swift 会推断你想创建一个 Double 。
let pi = 3.14159
// pi is inferred to be of type Double
Swift 在推断浮点值的时候始终会选择 Double (而不是 Float )。
如果你在一个表达式中将整数和浮点数结合起来, Double 会从内容中被推断出来。
let anotherPi = 3 + 0.14159
// anotherPi is also inferred to be of type Double
这字面量 3 没有显式的声明它的类型,但因为后边有一个浮点类型的字面量,所以这个类型就被推断为 Double 。
7 数值型字面量
整数型字面量可以写作:
- 一个十进制数,没有前缀
- 一个二进制数,前缀是
0b - 一个八进制数,前缀是
0o - 一个十六进制数,前缀是
0x
下面的这些所有整数字面量的十进制值都是 17 :
let decimalInteger = 17
let binaryInteger = 0b10001 // 17 in binary notation
let octalInteger = 0o21 // 17 in octal notation
let hexadecimalInteger = 0x11 // 17 in hexadecimal notation
浮点字面量可以是十进制(没有前缀)或者是十六进制(前缀是 0x )。小数点两边必须有至少一个十进制数字(或者是十六进制的数字)。十进制的浮点字面量还有一个可选的指数,用大写或小写的 e 表示;十六进制的浮点字面量必须有指数,用大写或小写的 p 来表示。
十进制数与 exp 的指数,结果就等于基数乘以 10exp:
- 1.25e2 意味着 1.25 x 102, 或者 125.0 .
- 1.25e-2 意味着 1.25 x 10-2, 或者 0.0125 .
十六进制数与 exp 指数,结果就等于基数乘以2exp:
- 0xFp2 意味着 15 x 22, 或者 60.0 .
- 0xFp-2 意味着 15 x 2-2, 或者 3.75 .
下面的这些浮点字面量的值都是十进制的 12.1875 :
let decimalDouble = 12.1875
let exponentDouble = 1.21875e1
let hexadecimalDouble = 0xC.3p0
数值型字面量也可以增加额外的格式使代码更加易读。整数和浮点数都可以添加额外的零或者添加下划线来增加代码的可读性。下面的这些格式都不会影响字面量的值。
let paddedDouble = 000123.456
let oneMillion = 1_000_000
let justOverOneMillion = 1_000_000.000_000_1
8 数值类型转换
通常来讲,即使我们知道代码中的整数变量和常量是非负的,我们也会使用 Int 类型。经常使用默认的整数类型可以确保你的整数常量和变量可以直接被复用并且符合整数字面量的类型推测。
只有在特殊情况下才会使用整数的其他类型,例如需要处理外部长度明确的数据或者为了优化性能、内存占用等其他必要情况。在这些情况下,使用指定长度的类型可以帮助你及时发现意外的值溢出和隐式记录正在使用数据的本质。
8.1 整数转换
不同整数的类型在变量和常量中存储的数字范围是不同的。 Int8 类型的常量或变量可以存储的数字范围是 -128~127,而 UInt8 类型的常量或者变量能存储的数字范围是 0~255 。如果数字超出了常量或者变量可存储的范围,编译的时候就会报错:
let cannotBeNegative: UInt8 = -1
// UInt8 cannot store negative numbers, and so this will report an error
let tooBig: Int8 = Int8.max + 1
// Int8 cannot store a number larger than its maximum value,
// and so this will also report an error
因为每个数值类型可存储的值的范围不同,你必须根据不同的情况进行数值类型的转换。这种选择性使用的方式可以避免隐式转换的错误并使你代码中的类型转换意图更加清晰。
要将一种数字类型转换成另外一种类型,你需要用当前值来初始化一个期望的类型。在下面的栗子中,常量 twoThousand 的类型是 UInt16 ,而常量 one 的类型是 UInt8 。他们不能直接被相加在一起,因为他们的类型不同。所以,这里让 UInt16 (one ) 创建一个新的 UInt16 类型并用 one 的值初始化,这样就可以在原来的地方使用了。
let twoThousand: UInt16 = 2_000
let one: UInt8 = 1
let twoThousandAndOne = twoThousand + UInt16(one)
因为加号两边的类型现在都是 UInt16 ,所以现在是可以相加的。输出的常量( twoThousandAndOne )被推断为 UInt16 类型,因为他是两个 UInt16 类型的和。
SomeType(ofInitialValue) 是调用 Swift 类型初始化器并传入一个初始值的默认方法。在语言的内部, UInt16 有一个初始化器,可以接受一个 UInt8 类型的值,所以这个初始化器可以用现有的 UInt8来创建一个新的 UInt16 。这里需要注意的是并不能传入任意类型的值,只能传入 UInt16 内部有对应初始化器的值。不过你可以扩展现有的类型来让它可以接收其他类型的值(包括自定义类型),请参考扩展 。
8.2 整数和浮点数转换
整数和浮点数类型的转换必须显式地指定类型:
let three = 3
let pointOneFourOneFiveNine = 0.14159
let pi = Double(three) + pointOneFourOneFiveNine
// pi equals 3.14159, and is inferred to be of type Double
在这里,常量 three 的值被用来创建一个类型为 Double 的新的值,所以加号两边的值的类型是相同的。没有这个转换,加法就无法进行。
浮点转换为整数也必须显式地指定类型。一个整数类型可以用一个 Double 或者 Float 值初始化。
let integerPi = Int(pi)
// integerPi equals 3, and is inferred to be of type Int
在用浮点数初始化一个新的整数类型的时候,数值会被截断。也就是说 4.75 会变成 4 , -3.9 会变为 -3 。
结合数字常量和变量的规则与结合数字字面量的规则不同,字面量 3 可以直接和字面量 0.14159 相加,因为数字字面量本身没有明确的类型。它们的类型只有在编译器需要计算的时候才会被推测出来。
9 类型别名
类型别名可以为已经存在的类型定义了一个新的可选名字。用 typealias 关键字定义类型别名。
当你根据上下文的语境想要给类型一个更有意义的名字的时候,类型别名会非常高效,例如处理外部资源中特定长度的数据时:
typealias AudioSample = UInt16
一旦为类型创建了一个别名,你就可以在任何使用原始名字的地方使用这个别名。
var maxAmplitudeFound = AudioSample.min
// maxAmplitudeFound is now 0
在这个栗子中, AudioSample 就是 UInt16 的别名,因为这个别名的存在,我们调用 AudioSample.min 其实就是在调用 Int16.min ,在这里变量 maxAmplitudeFound 被提供了一个初始值 0 。
10 布尔值
Swift 有一个基础的布尔量类型,就是 Bool ,布尔量被作为逻辑值来引用,因为他的值只能是真或者假。Swift为布尔量提供了两个常量值, true 和 false 。
let orangesAreOrange = true
let turnipsAreDelicious = false
上面的两个类型 orangesAreOrange 和 turnipsAreDelicious ,被推断为 Bool ,因为它们使用布尔量来初始化。对于上文中的 Int 和 Double ,当你在创建的他们的时候设置为 true 或 false ,那么就不必给这个常量或者变量声明为 Bool 类型。初始化常量或者变量的时候,如果值的类型已知,类型推断会把 Swift 代码变的更加整洁和易读。
当你处理条件语句的时候例如 if 语句时,布尔值就会变得非常有用:
if turnipsAreDelicious {
print("Mmm, tasty turnips!")
} else {
print("Eww, turnips are horrible.")
}
// prints "Eww, turnips are horrible."
Swift 的类型安全机制会阻止你用一个非布尔量的值替换掉 Bool 。下面的栗子中报告了一个发生在编译时的错误:
let i = 1
if i {
// this example will not compile, and will report an error
}
然而,下边的这个例子就是可行的:
let i = 1
if i == 1 {
// this example will compile successfully
}
这里 i == 1 的比较结果是一个 Bool 类型,所以第二个栗子可以通过类型检查。类似 i == 1 这样的比较请参考基本运算符。
与 Swift 中其他的类型安全示例一样,这个方法可以避免错误的发生并确保这块代码的意图清晰。
11 元组
元组把多个值合并成单一的复合型的值。元组内的值可以是任何类型,而且可以不必是同一类型。
在下面的示例中, (404, “Not Found”) 是一个描述了 HTTP 状态代码 的元组。HTTP 状态代码是当你请求网页的时候 web 服务器返回的一个特殊值。当你请求不存在的网页时,就会返回 404 Not Found
let http404Error = (404, "Not Found")
// http404Error is of type (Int, String), and equals (404, "Not Found")
(404, “Not Found”) 元组把一个 Int 和一个 String 组合起来表示 HTTP 状态代码的两种不同的值:数字和人类可读的描述。他可以被描述为“一个类型为 (Int, String) 的元组”
任何类型的排列都可以被用来创建一个元组,他可以包含任意多的类型。例如 (Int, Int, Int) 或者 (String, Bool) ,实际上,任何类型的组合都是可以的。
你也可以将一个元组的内容分解成单独的常量或变量,这样你就可以正常的使用它们了:
let (statusCode, statusMessage) = http404Error
print("The status code is \(statusCode)")
// prints "The status code is 404"
print("The status message is \(statusMessage)")
// prints "The status message is Not Found"
当你分解元组的时候,如果只需要使用其中的一部分数据,不需要的数据可以用下滑线( _ )代替:
let (justTheStatusCode, _) = http404Error
print("The status code is \(justTheStatusCode)")
// prints "The status code is 404"
另外一种方法就是利用从零开始的索引数字访问元组中的单独元素:
print("The status code is \(http404Error.0)")
// prints "The status code is 404"
print("The status message is \(http404Error.1)")
// prints "The status message is Not Found"
你可以在定义元组的时候给其中的单个元素命名:
let http200Status = (statusCode: 200, description: "OK")
在命名之后,你就可以通过访问名字来获取元素的值了:
print("The status code is \(http200Status.statusCode)")
// prints "The status code is 200"
print("The status message is \(http200Status.description)")
// prints "The status message is OK"
作为函数返回值时,元组非常有用。一个用来获取网页的函数可能会返回一个 (Int, String) 元组来描述是否获取成功。相比只能返回一个类型的值,元组能包含两个不同类型值,他可以让函数的返回信息更有用。更多内容请参考多返回值的函数。
元组在临时的值组合中很有用,但是它们不适合创建复杂的数据结构。如果你的数据结构超出了临时使用的范围,那么请建立一个类或结构体来代替元组。更多信息请参考类和结构体。
12 可选项
在 C 和 Objective-C 中,没有可选项的概念。在 Objective-C 中有一个近似的特性,一个方法可以返回一个对象或者返回 nil 。 nil 的意思是“缺少一个可用对象”。然而,他只能用在对象上,却不能作用在结构体,基础的 C 类型和枚举值上。对于这些类型,Objective-C 会返回一个特殊的值(例如 NSNotFound )来表示值的缺失。这种方法是建立在假设调用者知道这个特殊的值并记得去检查他。然而,Swift 中的可选项就可以让你知道任何类型的值的缺失,他并不需要一个特殊的值。
下面的栗子演示了可选项如何作用于值的缺失,Swift 的 Int 类型中有一个初始化器,可以将 String 值转换为一个 Int 值。然而并不是所有的字符串都可以转换成整数。字符串 “123” 可以被转换为数字值 123 ,但是字符串 “hello, world” 就显然不能转换为一个数字值。
在下面的栗子中,试图利用初始化器将一个 String 转换为 Int :
let possibleNumber = "123"
let convertedNumber = Int(possibleNumber)
// convertedNumber is inferred to be of type "Int?", or "optional Int"
因为这个初始化器可能会失败,所以他会返回一个可选的 Int ,而不是 Int 。可选的 Int 写做 Int? ,而不是 Int 。问号明确了它储存的值是一个可选项,意思就是说它可能包含某些 Int 值,或者可能根本不包含值。(他不能包含其他的值,例如 Bool 值或者 String 值。它要么是 Int 要么什么都没有。)
12.1 nil
你可以通过给可选变量赋值一个 nil 来将之设置为没有值:
var serverResponseCode: Int? = 404
// serverResponseCode contains an actual Int value of 404
serverResponseCode = nil
// serverResponseCode now contains no value
nil 不能用于非可选的常量或者变量,如果你的代码中变量或常量需要作用于特定条件下的值缺失,可以给他声明为相应类型的可选项。
如果你定义的可选变量没有提供一个默认值,变量会被自动设置成 nil 。
var surveyAnswer: String?
// surveyAnswer is automatically set to nil
Swift 中的 nil 和Objective-C 中的 nil 不同,在 Objective-C 中 nil 是一个指向不存在对象的指针。在 Swift中, nil 不是指针,他是值缺失的一种特殊类型,任何类型的可选项都可以设置成 nil 而不仅仅是对象类型。
12.2 If 语句以及强制展开
你可以利用 if 语句通过比较 nil 来判断一个可选中是否包含值。利用相等运算符 ( == )和不等运算符( != )。
如果一个可选有值,他就“不等于” nil :
if convertedNumber != nil {
print("convertedNumber contains some integer value.")
}
// prints "convertedNumber contains some integer value."
一旦你确定可选中包含值,你可以在可选的名字后面加一个感叹号 ( ! ) 来获取值,感叹号的意思就是说“我知道这个可选项里边有值,展开吧。”这就是所谓的可选值的强制展开。
if convertedNumber != nil {
print("convertedNumber has an integer value of \(convertedNumber!).")
}
// prints "convertedNumber has an integer value of 123."
12.3 可选项绑定
可以使用可选项绑定来判断可选项是否包含值,如果包含就把值赋给一个临时的常量或者变量。可选绑定可以与 if 和 while 的语句使用来检查可选项内部的值,并赋值给一个变量或常量。 if 和 while 语句的更多详细描述,请参考控制流。
在 if 语句中,这样书写可选绑定:
if let constantName = someOptional {
statements
}
你可以像上面这样使用可选绑定而不是强制展开来重写 possibleNumber 这个例子:
if let actualNumber = Int(possibleNumber) {
print("\'\(possibleNumber)\' has an integer value of \(actualNumber)")
} else {
print("\'\(possibleNumber)\' could not be converted to an integer")
}
// prints "'123' has an integer value of 123"
代码可以读作:
“如果 Int(possibleNumber) 返回的可选 Int 包含一个值,将这个可选项中的值赋予一个叫做 actualNumber 的新常量。”
如果转换成功,常量 actualNumber 就可以用在 if 语句的第一个分支中,他早已被可选内部的值进行了初始化,所以这时就没有必要用 ! 后缀来获取里边的值。在这个栗子中 actualNumber 被用来输出转换后的值。
常量和变量都可以使用可选项绑定,如果你想操作 if 语句中第一个分支的 actualNumber 的值,你可以写 if var actualNumber 来代替,可选项内部包含的值就会被设置为一个变量而不是常量。
你可以在同一个 if 语句中包含多可选项绑定,用逗号分隔即可。如果任一可选绑定结果是 nil 或者布尔值为 false ,那么整个 if 判断会被看作 false 。下面的两个 if 语句是等价的:
if let firstNumber = Int("4"), let secondNumber = Int("42"), firstNumber < secondNumber && secondNumber < 100 {
print("\(firstNumber) < \(secondNumber) < 100")
}
// Prints "4 < 42 < 100"
if let firstNumber = Int("4") {
if let secondNumber = Int("42") {
if firstNumber < secondNumber && secondNumber < 100 {
print("\(firstNumber) < \(secondNumber) < 100")
}
}
}
// Prints "4 < 42 < 100"
如同提前退出中描述的那样,使用 if 语句创建的常量和变量只在if语句的函数体内有效。相反,在 guard 语句中创建的常量和变量在 guard 语句后的代码中也可用。
12.4 隐式展开可选项
如上所述,可选项明确了常量或者变量可以“没有值”。可选项可以通过 if 语句来判断是否有值,如果有值的话可以通过可选项绑定来获取里边的值。
有时在一些程序结构中可选项一旦被设定值之后,就会一直拥有值。在这种情况下,就可以去掉检查的需求,也不必每次访问的时候都进行展开,因为它可以安全的确认每次访问的时候都有一个值。
这种类型的可选项被定义为隐式展开可选项。通过在声明的类型后边添加一个叹号( String! )而非问号( String? ) 来书写隐式展开可选项。
在可选项被定义的时候就能立即确认其中有值的情况下,隐式展开可选项非常有用。如同无主引用和隐式展开的可选属性中描述的那样,隐式展开可选项主要被用在 Swift 类的初始化过程中。
隐式展开可选项是后台场景中通用的可选项,但是同样可以像非可选值那样来使用,每次访问的时候都不需要展开。下面的栗子展示了在访问被明确为 String 的可选项展开值时,可选字符串和隐式展开可选字符串的行为区别:
let possibleString: String? = "An optional string."
let forcedString: String = possibleString! // requires an exclamation mark
let assumedString: String! = "An implicitly unwrapped optional string."
let implicitString: String = assumedString // no need for an exclamation mark
你可以把隐式展开可选项当做在每次访问它的时候被给予了自动进行展开的权限,你可以在声明可选项的时候添加一个叹号而不是每次调用的时候在可选项后边添加一个叹号。
如果你在隐式展开可选项没有值的时候还尝试获取值,会导致运行错误。结果和在没有值的普通可选项后面加一个叹号一样。
你可以像对待普通可选一样对待隐式展开可选项来检查里边是否包含一个值:
if assumedString != nil {
print(assumedString)
}
// prints "An implicitly unwrapped optional string."
你也可以使用隐式展开可选项通过可选项绑定在一句话中检查和展开值:
if let definiteString = assumedString {
print(definiteString)
}
// prints "An implicitly unwrapped optional string."
不要在一个变量将来会变为 nil 的情况下使用隐式展开可选项。如果你需要检查一个变量在生存期内是否会变为 nil ,就使用普通的可选项。
13 错误处理
在程序执行阶段,你可以使用错误处理机制来为错误状况负责。
相比于可选项的通过值是否缺失来判断程序的执行正确与否,而错误处理机制能允许你判断错误的形成原因,在必要的情况下,还能将你的代码中的错误传递到程序的其他地方。
当一个函数遇到错误情况,他会抛出一个错误,这个函数的访问者会捕捉到这个错误,并作出合适的反应。
func canThrowAnError() throws {
// this function may or may not throw an error
}
通过在函数声明过程当中加入 throws 关键字来表明这个函数会抛出一个错误。当你调用了一个可以抛出错误的函数时,需要在表达式前预置 try 关键字。
Swift 会自动将错误传递到它们的生效范围之外,直到它们被 catch 分句处理。
do {
try canThrowAnError()
// no error was thrown
} catch {
// an error was thrown
}
do 语句创建了一个新的容器范围,可以让错误被传递到到不止一个的 catch 分句里。
下面的栗子演示了如何利用错误处理机制处理不同的错误情况:
func makeASandwich() throws {
// ...
}
do {
try makeASandwich()
eatASandwich()
} catch Error.OutOfCleanDishes {
washDishes()
} catch Error.MissingIngredients(let ingredients) {
buyGroceries(ingredients)
}
在上面的栗子中,在没有干净的盘子或者缺少原料的情况下,方法 makeASandwich() 就会抛出一个错误。由于 makeASandwich() 的抛出,方法的调用被包裹在了一个 try 的表达式中。通过将方法的调用包裹在 do 语句中,任何抛出来的错误都会被传递到预先提供的 catch 分句中。
如果没有错误抛出,方法 eatASandwich() 就会被调用,如果有错误抛出且满足 Error.OutOfCleanDishes 这个条件,方法 washDishes() 就会被执行。如果一个错误被抛出,而它又满足 Error.MissingIngredients 的条件,那么 buyGroceries(_:) 就会协同被 catch 模式捕获的 [String] 值一起调用。
有关抛出,捕获和错误传递的更详细信息请参考错误处理。
14 断言和先决条件
断言和先决条件用来检测运行时发生的事情。你可以使用它们来保证在执行后续代码前某必要条件是满足的。如果布尔条件在断言或先决条件中计算为 true ,代码就正常继续执行。如果条件计算为 false ,那么程序当前的状态就是非法的;代码执行结束,然后你的 app 终止。
你可以使用断言和先决条件来验证那些你在写代码时候的期望和假定,所以你可以包含它们作为你代码的一部分。断言能够帮助你在开发的过程中找到错误和不正确的假定,先决条件帮助你探测产品的问题。在运行时帮助你额外验证你的期望,断言和先决条件同样是代码中好用的证明形式。不同于在上文错误处理中讨论的,断言和先决条件并不用于可回复或者期望的错误。由于错误断言或先决条件显示非法的程序状态,所以没办法来抓取错误断言。
使用断言和先决条件不能代替你代码中小概率非法情况的处理设计。总之,使用他们来强制数据和状态正确会让你的 app 在有非法状态时终止的更可预料,并帮助你更好的 debug。在检测到异常状态时尽可能快地停止执行同样能够帮助你减小由于异常状态造成的损失。
断言和先决条件的不同之处在于他们什么时候做检查:断言只在 debug 构建的时候检查,但先决条件则在 debug 和生产构建中生效。在生产构建中,断言中的条件不会被计算。这就是说你可以在开发的过程当中随便使用断言而无需担心影响生产性能。
14.1 使用断言进行调试
断言会在运行的时候检查一个逻辑条件是否为 true 。顾名思义,断言可以“断言”一个条件是否为真。你可以使用断言确保在运行其他代码之前必要的条件已经被满足。如果条件判断为 true,代码运行会继续进行;如果条件判断为 false,代码运行结束,你的应用也就中止了。
如果你的代码在调试环境下触发了一个断言,例如你在 Xcode 中创建并运行一个应用,你可以明确的知道不可用的状态发生在什么地方,还能检查断言被触发时你的应用的状态。另外,断言还允许你附加一条调试的信息。
你可以使用全局函数 assert(_:_:) 函数来写断言。向 assert(_:_:) 函数传入一个结果为 true 或者 false 的表达式以及一条会在结果为 false 的时候显式的信息:
let age = -3
assert(age >= 0, "A person's age cannot be less than zero")
// this causes the assertion to trigger, because age is not >= 0
在这个例子当中,代码执行只要在 if age >= 0 评定为 true 时才会继续,就是说,如果 age 的值非负。如果 age 的值是负数,在上文的代码当中, age >= 0 评定为 false ,断言就会被触发,终止应用。
断言信息可以删掉如果你想的话,就像下边的栗子:
assert(age >= 0)
如果代码已经检查了条件,你可以使用 assertionFailure(_:file:line:) 函数来标明断言失败,比如:
if age > 10 {
print("You can ride the roller-coaster or the ferris wheel.")
} else if age > 0 {
print("You can ride the ferris wheel.")
} else {
assertionFailure("A person's age can't be less than zero.")
}
14.2 强制先决条件
在你代码中任何条件可能潜在为假但必须肯定为真才能继续执行的地方使用先决条件。比如说,使用先决条件来检测下标没有越界,或者检测函数是否收到了一个合法的值。
你可以通过调用 precondition(_:_:file:line:) 函数来写先决条件。给这个函数传入表达式计算为 true 或 false ,如果条件的结果是 false 信息就会显示出来。比如说:
// In the implementation of a subscript...
precondition(index > 0, "Index must be greater than zero.")
你可以调用 preconditionFailure(_:file:line:) 函数来标明错误发生了——比如说,如果 switch 的默认情况被选中,但所有的合法输入数据应该被其他 switch 的情况处理。
如果你在不检查模式编译( -Ounchecked ),先决条件不会检查。编译器假定先决条件永远为真,并且它根据你的代码进行优化。总之, fatalError(_:file:line:) 函数一定会终止执行,无论你优化设定如何。
你可以在草拟和早期开发过程中使用 fatalError(_:file:line:) 函数标记那些还没实现的功能,通过使用 fatalError(“Unimplemented”) 来作为代替。由于致命错误永远不会被优化,不同于断言和先决条件,你可以确定执行遇到这些临时占位永远会停止。
基本运算符
运算符是一种用来检查、改变或者合并值的特殊符号或组合符号。举例来说,加运算符( + )能够把两个数字相加(比如 let i = 1 + 2 )。更复杂的栗子包括逻辑与运算 && 比如 if enteredDoorCode && passedRetinaScan 。
Swift 在支持 C 中的大多数标准运算符的同时也增加了一些排除常见代码错误的能力。赋值符号( = )不会返回值,以防它被误用于等于符号( == )的意图上。算数符号( + , - , * , / , % 以及其他)可以检测并阻止值溢出,以避免你在操作比储存类型允许的范围更大或者更小的数字时得到各种奇奇怪怪的结果。如同 溢出操作符 中描述的那样,你可以通过使用 Swift 的溢出操作符来选择进入值溢出行为模式。
Swift 提供了两种 C 中没有的区间运算符( a..<b 和 a…b ),来让你便捷表达某个范围的值。
这个章节叙述了 Swift 语言当中常见的运算符。高级运算符 则涵盖了 Swift 中的高级运算符,同时描述了如何定义你自己的运算符以及在你自己的类当中实现标准运算符。
1 专门用语
运算符包括一元、二元、三元:
- 一元运算符对一个目标进行操作(比如 -a )。一元前缀运算符在目标之前直接添加(比如 !b ),同时一元后缀运算符直接在目标末尾添加(比如 c! )。
- 二元运算符对两个目标进行操作(比如 2 + 3 )同时因为它们出现在两个目标之间,所以是中缀。
- 三元运算符操作三个目标。如同 C,Swift语言也仅有一个三元运算符,三元条件运算符( a ? b : c )。
受到运算符影响的值叫做操作数。在表达式 1 + 2 中, + 符号是一个二元运算符,其中的两个值 1 和 2 就是操作数。
2 赋值运算符
赋值运算符( a = b )可以初始化或者更新 a 为 b 的值:
let b = 10
var a = 5
a = b
// a 的值现在是 10
如果赋值符号右侧是拥有多个值的元组,它的元素将会一次性地拆分成常量或者变量:
let (x, y) = (1, 2)
// x 等于 1, 同时 y 等于 2
与 Objective-C 和 C 不同,Swift 的赋值符号自身不会返回值。下面的语句是不合法的:
if x = y {
// 这是不合法的, 因为 x = y 并不会返回任何值。
}
这个特性避免了赋值符号 (=) 被意外地用于等于符号 (==) 的实际意图上。Swift 通过让 if x = y 非法来帮助你避免这类的错误在你的代码中出现。
3 算术运算符
Swift 对所有的数字类型支持四种标准算术运算符:
- 加 ( + )
- 减 ( - )
- 乘 ( * )
- 除 ( / )
1 + 2 // equals 3
5 - 3 // equals 2
2 * 3 // equals 6
10.0 / 2.5 // equals 4.0
与 C 和 Objective-C 中的算术运算符不同,Swift 算术运算符默认不允许值溢出。你可以选择使用 Swift 的溢出操作符(比如 a &+ b )来行使溢出行为。参见 溢出操作符 加法运算符同时也支持 String 的拼接:
"hello, " + "world" // equals "hello, world"
3.1 余数运算符
余数运算符( a % b )可以求出多少个 b 的倍数能够刚好放进 a 中并且返回剩下的值(就是我们所谓的余数)。
余数运算符( % )同样会在别的语言中称作取模运算符。总之,严格来讲的话这个行为对应着 Swift 中对负数的操作,所以余数要比模取更合适。
3.2 一元减号运算符
数字值的正负号可以用前缀 – 来切换,我们称之为 一元减号运算符:
let three = 3
let minusThree = -three // minusThree equals -3
let plusThree = -minusThree // plusThree equals 3, or "minus minus three"
一元减号运算符( - )直接在要进行操作的值前边放置,不加任何空格。
3.3 一元加号运算符
一元加号运算符 ( + )直接返回它操作的值,不会对其进行任何的修改:
let minusSix = -6
let alsoMinusSix = +minusSix // alsoMinusSix equals -6
尽管一元加号运算符实际上什么也不做,你还是可以对正数使用它来让你的代码对一元减号运算符来说显得更加对称。
4 组合赋值符号
如同 C ,Swift 提供了由赋值符号( = )和其他符号组成的 组合赋值符号 。一个加赋值符号的栗子 ( += ):
var a = 1
a += 2
// a is now equal to 3
表达式 a += 2 其实就是 a = a + 2 的简写。效率上来讲,加号和赋值符号组合成的一个运算符能够同时进行这两个操作。
组合运算符不会返回任何值。举例来说,你不能写成这样 let b = a += 2 。这个与前边提到的增量和减量符号的行为不同。
5 比较运算符
Swift 支持所有 C 的标准比较运算符:
- 相等 ( a == b )
- 不相等 ( a != b )
- 大于 ( a > b )
- 小于 ( a < b )
- 大于等于 ( a >= b )
- 小于等于 ( a <= b )
Swift 同时也提供两个等价运算符( === 和 !== ),你可以使用它们来判断两个对象的引用是否相同。参考 类和结构体 章节来了解更多。
每个比较运算符都会返回一个 Bool 值来表示语句是否为真:
1 == 1 // true, because 1 is equal to 1
2 != 1 // true, because 2 is not equal to 1
2 > 1 // true, because 2 is greater than 1
1 < 2 // true, because 1 is less than 2
1 >= 1 // true, because 1 is greater than or equal to 1
2 <= 1 // false, because 2 is not less than or equal to 1
比较运算符通常被用在条件语句当中,比如说 if 语句:
let name = "world"
if name == "world" {
print("hello, world")
} else {
print("I'm sorry \(name), but I don't recognize you")
}
// prints "hello, world", because name is indeed equal to "world"
你同样可以比较拥有同样数量值的元组,只要元组中的每个值都是可比较的。比如说, Int 和 String 都可以用来比较大小,也就是说 (Int,String) 类型的元组就可以比较。一般来说, Bool 不能比较,这意味着包含布尔值的元组不能用来比较大小。
元组以从左到右的顺序比较大小,一次一个值,直到找到两个不相等的值为止。如果所有的值都是相等的,那么就认为元组本身是相等的。比如说:
(1, "zebra") < (2, "apple") // true because 1 is less than 2
(3, "apple") < (3, "bird") // true because 3 is equal to 3, and "apple" is less than "bird"
(4, "dog") == (4, "dog") // true because 4 is equal to 4, and "dog" is equal to "dog"
Swift 标准库包含的元组比较运算符仅支持小于七个元素的元组。要比较拥有七个或者更多元素的元组,你必须自己实现比较运算符。
6 三元条件运算符
三元条件运算符是一种有三部分的特殊运算,它看起来是这样的: question ? answer1 : answer2 。这是一种基于 question 是真还是假来选择两个表达式之一的便捷写法。如果 question 是真,则会判断为 answer1 并且返回它的值;否则,它判断为 answer2 并且返回它的值。
三元条件运算符就是下边代码的简写:
if question {
answer1
} else {
answer2
}
这里有一个栗子,它计算一个表格的行高。行高应该是比内容的高度高50点,如果行有标题的话。要是没有标题,就比内容高20点:
let contentHeight = 40
let hasHeader = true
let rowHeight = contentHeight + (hasHeader ? 50 : 20)
// rowHeight is equal to 90
三元条件运算符提供了一个非常有效的简写来决策要两个表达式之间选哪个。总之,使用三元条件运算符要小心。它的简洁性会导致你代码重用的时候失去易读的特性。避免把多个三元条件运算符组合到一句代码当中。
7 合并空值运算符
合并空值运算符 ( a ?? b )如果可选项 a 有值则展开,如果没有值,是 nil ,则返回默认值 b 。表达式 a 必须是一个可选类型。表达式 b 必须与 a 的储存类型相同。
合并空值运算符是下边代码的缩写:
a != nil ? a! : b
上边的代码中,三元条件运算符强制展开( a! )储存在 a 中的值,如果 a 不是 nil 的话,否则就返回 b 的值。合并空值运算符提供了更加优雅的方式来封装这个条件选择和展开操作,让它更加简洁易读。
如果 a 的值是非空的, b 的值将不会被考虑。这就是所谓的 短路计算 。
下边的栗子使用了合并空值运算符来在默认颜色名和可选的用户定义颜色名之间做选择:
let defaultColorName = "red"
var userDefinedColorName: String? // defaults to nil
var colorNameToUse = userDefinedColorName ?? defaultColorName
// userDefinedColorName is nil, so colorNameToUse is set to the default of "red"
userDefinedColorName 变量被定义为可选的 String ,默认为 nil 。由于 userDefinedColorName 是一个可选类型,你可以使用合并空值运算符来控制它的值。在上边的栗子当中,这个运算符被用来决定 String 类型的变量 colorNameToUse 的初始值。因为 userDefinedColorName 是 nil ,表达式 userDefinedColorName ?? defaultColorName 返回了 defaultColorName 的值, “red” 。
如果你给 userDefinedColorName 指定一个非空的值然后让合并空值运算符在检查一次,那么 userDefinedColorName 中封装的值将会替换掉默认值:
userDefinedColorName = "green"
colorNameToUse = userDefinedColorName ?? defaultColorName
// userDefinedColorName is not nil, so colorNameToUse is set to "green"
8 区间运算符
Swift 包含了两个 区间运算符 ,他们是表示一个范围的值的便捷方式。
8.1 闭区间运算符
闭区间运算符( a…b )定义了从 a 到 b 的一组范围,并且包含 a 和 b 。 a 的值不能大于 b 。
在遍历你需要用到的所有数字时,使用闭区间运算符是个不错的选择,比如说在 for-in 循环当中:
for index in 1...5 {
print("\(index) times 5 is \(index * 5)")
}
// 1 times 5 is 5
// 2 times 5 is 10
// 3 times 5 is 15
// 4 times 5 is 20
// 5 times 5 is 25
8.2 半开区间运算符
半开区间运算符( a..<b )定义了从 a 到 b 但不包括 b 的区间,即 半开 ,因为它只包含起始值但并不包含结束值。(十奶注:其实就是左闭右开区间。)如同闭区间运算符, a 的值也不能大于 b ,如果 a 与 b 的值相等,那返回的区间将会是空的。
半开区间在遍历基于零开始序列比如说数组的时候非常有用,它从零开始遍历到数组长度(但是不包含):
let names = ["Anna", "Alex", "Brian", "Jack"]
let count = names.count
for i in 0..<count {
print("Person \(i + 1) is called \(names[i])")
}
// Person 1 is called Anna
// Person 2 is called Alex
// Person 3 is called Brian
// Person 4 is called Jack
注意数组包含四个元素,但是 0..<count 只遍历到 3(元素序号的最大值),因为这是一个半开区间。
8.3 单侧区间
闭区间有另外一种形式来让区间朝一个方向尽可能的远——比如说,一个包含数组所有元素的区间,从索引 2 到数组的结束。在这种情况下,你可以省略区间运算符一侧的值。因为运算符只有一侧有值,所以这种区间叫做单侧区间。比如说:
for name in names[2...] {
print(name)
}
// Brian
// Jack
for name in names[...2] {
print(name)
}
// Anna
// Alex
// Brian
半开区间运算符同样可以有单侧形式,只需要写它最终的值。和你两侧都包含值一样,最终的值不是区间的一部分。举例来说
for name in names[..<2] {
print(name)
}
// Anna
// Alex
单侧区间可以在其他上下文中使用,不仅仅是下标。你不能遍历省略了第一个值的单侧区间,因为遍历根本不知道该从哪里开始。你可以遍历省略了最终值的单侧区间;总之,由于区间无限连续,你要确保给循环添加一个显式的条件。你同样可以检测单侧区间是否包含特定的值,就如下面的代码所述。
let range = ...5
range.contains(7) // false
range.contains(4) // true
range.contains(-1) // true
9 逻辑运算符
逻辑运算符可以修改或者合并布尔逻辑值 true 和 false 。Swift 支持三种其他基于 C 的语言也包含的标准逻辑运算符
- 逻辑 非 ( !a )
- 逻辑 与 ( a && b )
-
逻辑 或 ( a b )
9.1 逻辑非运算符
逻辑非运算符( !a )会转换布尔值,把 true 变成 false , 把 false 变成 true 。
逻辑非运算符是一个前缀运算符,它直接写在要进行运算的值前边,不加空格。读作“非 a ”,如同下边的栗子:
let allowedEntry = false
if !allowedEntry {
print("ACCESS DENIED")
}
// prints "ACCESS DENIED"
这句 if !allowedEntry 可以读作“如果不允进入。”后边的代码只有 “不允许进入” 为真才会执行; 比如说现在 allowedEntry 为 false 。
在这个栗子当中,要注意布尔量的常量和变量名能够帮助你保持代码的可读和简洁,同时也要避免双重否定或者其他奇奇怪怪的逻辑语句。
9.2 逻辑与运算符
逻辑与运算符( a && b )需要逻辑表达式的两个值都为 true ,整个表达式的值才为 true 。
如果任意一个值是 false ,那么整个表达式的结果会是 false 。事实上,如果第一个值是 false ,那么第二个值就会被忽略掉了,因为它已经无法让整个表达式再成为 true 。这就是所谓的 短路计算 。
这个栗子依据两个 Bool 值判断只有它们都为 true 时才允许访问:
let enteredDoorCode = true
let passedRetinaScan = false
if enteredDoorCode && passedRetinaScan {
print("Welcome!")
} else {
print("ACCESS DENIED")
}
// prints "ACCESS DENIED"
9.3 逻辑或运算符
| 逻辑或运算符( a | b )是一个中缀运算符,它由两个相邻的管道字符组成。你可以使用它来创建两个值之间只要有一个为 true 那么整个表达式就是 true 的逻辑表达式。 |
如同上文中的逻辑与运算符,逻辑或运算符也使用短路计算来判断表达式。如果逻辑或运算符左侧的表达式为 true ,那么右侧则不予考虑了,因为它不会影响到整个逻辑表达式的结果。
在下边的栗子当中,第一个 Bool 值( hasDoorKey )是 false ,但是第二个值 ( knowsOverridePassword ) 是 true 。由于有一个值是 true ,这整个逻辑表达式的值同样被判断为 true , 所以访问被允许:
let hasDoorKey = false
let knowsOverridePassword = true
if hasDoorKey || knowsOverridePassword {
print("Welcome!")
} else {
print("ACCESS DENIED")
}
// prints "Welcome!"
9.4 混合逻辑运算
你可以组合多个逻辑运算符来创建一个更长的组合表达式:
if enteredDoorCode && passedRetinaScan || hasDoorKey || knowsOverridePassword {
print("Welcome!")
} else {
print("ACCESS DENIED")
}
// prints "Welcome!"
| 这个栗子使用了多个 && 和 | 运算符来创建组合表达式。不过, && 和 | 仍旧只能够操作两个值,它实际上是三个更小的表达式链接而成。这个栗子可以读作: |
如果我们输入了正确的密码并通过了视网膜扫描,或者如果我们有合法的钥匙或者我们知道紧急超驰密码,就允许进入。
基于 enteredDoorCode , passedRetinaScan ,和 hasDoorKey 的值,前两个子表达式都是 false 。总之,紧急超驰密码是知道的,所以整个组合的表达式仍然被评定为 true 。
Swift 语言中逻辑运算符 && 和 是左相关的,这意味着多个逻辑运算符组合的表达式会首先计算最左边的子表达式。
9.5 显式括号
很多时候虽然不被要求,但使用括号还是很有用的,这能让复杂的表达式更容易阅读。在上文当中的门禁栗子里,把前边部分的表达式用圆括号括起来就会让整个组合表达式的意图更加明显:
if (enteredDoorCode && passedRetinaScan) || hasDoorKey || knowsOverridePassword {
print("Welcome!")
} else {
print("ACCESS DENIED")
}
// prints "Welcome!"
圆括号把前边的两个值单独作为一部分来考虑,这样使整个表达式的意图清晰明显。组合表达式的输出并没有改变,但是整个意图变得清晰易读。可读性永远是第一位的;当需要的时候,使用圆括号让你的意图更加明确。
字符和字符串
字符串是例如”hello, world”,”albatross”这样的有序的Character(字符)类型的值的集合。通过String类型来表示。 一个String的内容可以用许多方式读取,包括作为一个Character值的集合。
Swift 的String和Character类型提供了快速和兼容 Unicode 的方式供你的代码使用。创建和操作字符串的语法与 C 语言中字符串操作相似,轻量并且易读。 字符串连接操作只需要简单地通过+符号将两个字符串相连即可。与 Swift 中其他值一样,能否更改字符串的值,取决于其被定义为常量还是变量。你也可以在字符串内插过程中使用字符串插入常量、变量、字面量表达成更长的字符串,这样可以很容易的创建自定义的字符串值,进行展示、存储以及打印。
尽管语法简易,但String类型是一种快速、现代化的字符串实现。 每一个字符串都是由编码无关的 Unicode 字符组成,并支持访问字符的多种 Unicode 表示形式(representations)。
注意: Swift 的String类型与 Foundation NSString类进行了无缝桥接。Foundation 也可以对String进行扩展,暴露在NSString中定义的方法。 这意味着,如果你在String中调用这些NSString的方法,将不用进行转换。 更多关于在 Foundation 和 Cocoa 中使用String的信息请查看 Using Swift with Cocoa and Objective-C (Swift 4)。
1 字符串字面量
你可以在代码里使用一段预定义的字符串值作为字符串字面量。字符串字面量是由一对双引号包裹着的具有固定顺序的字符集。
字符串字面量可以用于为常量和变量提供初始值:
let someString = "Some string literal value"
注意someString常量通过字符串字面量进行初始化,Swift 会推断该常量为String类型。
1.1 多行字符串字面量
如果你需要一个字符串是跨越多行的,那就使用多行字符串字面量 —— 由一对三个双引号包裹着的具有固定顺序的文本字符集:
let quotation = """
The White Rabbit put on his spectacles. "Where shall I begin,
please your Majesty?" he asked.
"Begin at the beginning," the King said gravely, "and go on
till you come to the end; then stop."
"""
一个多行字符串字面量包含了所有的在开启和关闭引号(””“)中的行。这个字符从开启引号(“”“)之后的第一行开始,到关闭引号(“”“)之前为止。这就意味着字符串开启引号之后(“”“)或者结束引号(“”“)之前都没有换行符号。(译者:下面两个字符串其实是一样的,虽然第二个使用了多行字符串的形式)
let singleLineString = "These are the same."
let multilineString = """
These are the same.
"""
如果你的代码中,多行字符串字面量包含换行符的话,则多行字符串字面量中也会包含换行符。如果你想换行,以便加强代码的可读性,但是你又不想在你的多行字符串字面量中出现换行符的话,你可以用在行尾写一个反斜杠()作为续行符。
let softWrappedQuotation = """
The White Rabbit put on his spectacles. "Where shall I begin, \
please your Majesty?" he asked.
"Begin at the beginning," the King said gravely, "and go on \
till you come to the end; then stop."
"""
为了让一个多行字符串字面量开始和结束于换行符,请将换行写在第一行和最后一行,例如:
let lineBreaks = """
This string starts with a line break.
It also ends with a line break.
"""
一个多行字符串字面量能够缩进来匹配周围的代码。关闭引号(“”“)之前的空白字符串告诉Swift编译器其他各行多少空白字符串需要忽略。然而,如果你在某行的前面写的空白字符串超出了关闭引号(“”“)之前的空白字符串,则超出部分将被包含在多行字符串字面量中。
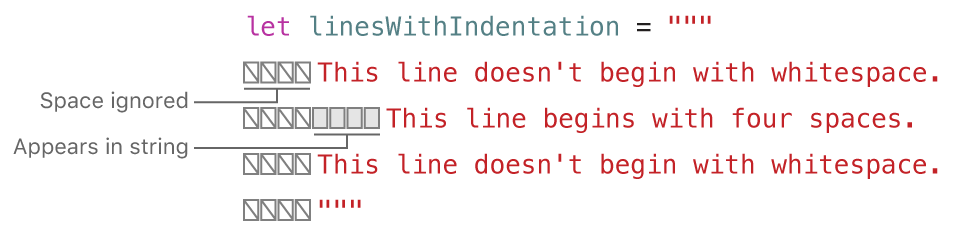
在上面的例子中,尽管整个多行字符串字面量都是缩进的(源代码缩进),第一行和最后一行没有以空白字符串开始(实际的变量值)。中间一行的缩进用空白字符串(源代码缩进)比关闭引号(“”“)之前的空白字符串多,所以,它的行首将有4个空格。
2 字面量中的特殊字符
字符串字面量可以包含以下特殊字符:
- 转义字符\0(空字符)、\(反斜线)、\t(水平制表符)、\n(换行符)、\r(回车符)、"(双引号)、'(单引号)。
- Unicode 标量,写成\u{n}(u为小写),其中n为任意一到八位十六进制数且可用的 Unicode 位码。
下面的代码为各种特殊字符的使用示例。 wiseWords常量包含了两个双引号。 dollarSign、blackHeart和sparklingHeart常量演示了三种不同格式的 Unicode 标量:
let wiseWords = "\"Imagination is more important than knowledge\" - Einstein"
// "Imageination is more important than knowledge" - Enistein
let dollarSign = "\u{24}" // $,Unicode 标量 U+0024
let blackHeart = "\u{2665}" // ♥,Unicode 标量 U+2665
let sparklingHeart = "\u{1F496}" // 💖,Unicode 标量 U+1F496
由于多行字符串字面量使用了三个双引号,而不是一个,所以你可以在多行字符串字面量里直接使用双引号(”)而不必加上转义符(\)。要在多行字符串字面量中使用 “”” 的话,就需要使用至少一个转义符(\):
let threeDoubleQuotes = """
Escaping the first quote \"""
Escaping all three quotes \"\"\"
"""
3 初始化空字符串
要创建一个空字符串作为初始值,可以将空的字符串字面量赋值给变量,也可以初始化一个新的String实例:
var emptyString = "" // 空字符串字面量
var anotherEmptyString = String() // 初始化方法
// 两个字符串均为空并等价。
您可以通过检查其Bool类型的isEmpty属性来判断该字符串是否为空:
if emptyString.isEmpty {
print("Nothing to see here")
}
// 打印输出:"Nothing to see here"
4 字符串可变性
您可以通过将一个特定字符串分配给一个变量来对其进行修改,或者分配给一个常量来保证其不会被修改:
var variableString = "Horse"
variableString += " and carriage"
// variableString 现在为 "Horse and carriage"
let constantString = "Highlander"
constantString += " and another Highlander"
// 这会报告一个编译错误 (compile-time error) - 常量字符串不可以被修改。
在 Objective-C 和 Cocoa 中,您需要通过选择两个不同的类(NSString和NSMutableString)来指定字符串是否可以被修改。
5 字符串是值类型
Swift 的String类型是值类型。 如果您创建了一个新的字符串,那么当其进行常量、变量赋值操作,或在函数/方法中传递时,会进行值拷贝。 任何情况下,都会对已有字符串值创建新副本,并对该新副本进行传递或赋值操作。 值类型在 结构体和枚举是值类型 中进行了详细描述。
Swift 默认字符串拷贝的方式保证了在函数/方法中传递的是字符串的值。 很明显无论该值来自于哪里,都是您独自拥有的。 您可以确信传递的字符串不会被修改,除非你自己去修改它。
在实际编译时,Swift 编译器会优化字符串的使用,使实际的复制只发生在绝对必要的情况下,这意味着您将字符串作为值类型的同时可以获得极高的性能。
6 使用字符
您可通过for-in循环来遍历字符串,获取字符串中每一个字符的值:
for character in "Dog!🐶" {
print(character)
}
// D
// o
// g
// !
// 🐶
for-in循环在 For 循环 中进行了详细描述。
另外,通过标明一个Character类型并用字符字面量进行赋值,可以建立一个独立的字符常量或变量:
let exclamationMark: Character = "!"
字符串可以通过传递一个值类型为Character的数组作为自变量来初始化:
let catCharacters: [Character] = ["C", "a", "t", "!", "🐱"]
let catString = String(catCharacters)
print(catString)
// 打印输出:"Cat!🐱"
7 连接字符串和字符
字符串可以通过加法运算符(+)相加在一起(或称“连接”)创建一个新的字符串:
let string1 = "hello"
let string2 = " there"
var welcome = string1 + string2
// welcome 现在等于 "hello there"
您也可以通过加法赋值运算符 (+=) 将一个字符串添加到一个已经存在字符串变量上:
var instruction = "look over"
instruction += string2
// instruction 现在等于 "look over there"
您可以用append()方法将一个字符附加到一个字符串变量的尾部:
let exclamationMark: Character = "!"
welcome.append(exclamationMark)
// welcome 现在等于 "hello there!"
您不能将一个字符串或者字符添加到一个已经存在的字符变量上,因为字符变量只能包含一个字符。
如果你需要使用多行字符串字面量来拼接字符串,并且你需要字符串每一行都以换行符结尾,包括最后一行:
let badStart = """
one
two
"""
let end = """
three
"""
print(badStart + end)
// 打印两行:
// one
// twothree
let goodStart = """
one
two
"""
print(goodStart + end)
// 打印三行:
// one
// two
// three
上面的代码,把 badStart 和 end 拼接起来的字符串非我们想要的结果。因为 badStart 最后一行没有换行符,它与 end 的第一行结合到了一起。相反的,goodStart 的每一行都以换行符结尾,所以它与 end 拼接的字符串总共有三行,正如我们期望的那样。
8 字符串插值
字符串插值是一种构建新字符串的方式,可以在其中包含常量、变量、字面量和表达式。字符串字面量和多行字符串字面量都可以使用字符串插值。 您插入的字符串字面量的每一项都在以反斜线为前缀的圆括号中:
let multiplier = 3
let message = "\(multiplier) times 2.5 is \(Double(multiplier) * 2.5)"
// message 是 "3 times 2.5 is 7.5"
在上面的例子中,multiplier作为(multiplier)被插入到一个字符串常量量中。 当创建字符串执行插值计算时此占位符会被替换为multiplier实际的值。
multiplier的值也作为字符串中后面表达式的一部分。 该表达式计算Double(multiplier) * 2.5的值并将结果 (7.5) 插入到字符串中。 在这个例子中,表达式写为(Double(multiplier) * 2.5)并包含在字符串字面量中。
插值字符串中写在括号中的表达式不能包含非转义反斜杠 (),并且不能包含回车或换行符。不过,插值字符串可以包含其他字面量。
9 Unicode
Unicode是一个国际标准,用于文本的编码和表示。 它使您可以用标准格式表示来自任意语言几乎所有的字符,并能够对文本文件或网页这样的外部资源中的字符进行读写操作。 Swift 的String和Character类型是完全兼容 Unicode 标准的。
9.1 Unicode 标量
Swift 的String类型是基于 Unicode 标量 建立的。 Unicode 标量是对应字符或者修饰符的唯一的21位数字,例如U+0061表示小写的拉丁字母(LATIN SMALL LETTER A)(“a”),U+1F425表示小鸡表情(FRONT-FACING BABY CHICK) (“🐥”)。
注意: Unicode 码位(code poing) 的范围是U+0000到U+D7FF或者U+E000到U+10FFFF。Unicode 标量不包括 Unicode 代理项(surrogate pair) 码位,其码位范围是U+D800到U+DFFF。
注意不是所有的21位 Unicode 标量都代表一个字符,因为有一些标量是留作未来分配的。已经代表一个典型字符的标量都有自己的名字,例如上面例子中的LATIN SMALL LETTER A和FRONT-FACING BABY CHICK。
9.2 可扩展的字形群集
每一个 Swift 的Character类型代表一个可扩展的字形群。 一个可扩展的字形群是一个或多个可生成人类可读的字符 Unicode 标量的有序排列。 举个例子,字母é可以用单一的 Unicode 标量é(LATIN SMALL LETTER E WITH ACUTE, 或者U+00E9)来表示。然而一个标准的字母e(LATIN SMALL LETTER E或者U+0065) 加上一个急促重音(COMBINING ACTUE ACCENT)的标量(U+0301),这样一对标量就表示了同样的字母é。 这个急促重音的标量形象的将e转换成了é。
在这两种情况中,字母é代表了一个单一的 Swift 的Character值,同时代表了一个可扩展的字形群。 在第一种情况,这个字形群包含一个单一标量;而在第二种情况,它是包含两个标量的字形群:
let eAcute: Character = "\u{E9}" // é
let combinedEAcute: Character = "\u{65}\u{301}" // e 后面加上 ́
// eAcute 是 é, combinedEAcute 是 é
可扩展的字符群集是一个灵活的方法,用许多复杂的脚本字符表示单一的Character值。 例如,来自朝鲜语字母表的韩语音节能表示为组合或分解的有序排列。 在 Swift 都会表示为同一个单一的Character值:
let precomposed: Character = "\u{D55C}" // 한
let decomposed: Character = "\u{1112}\u{1161}\u{11AB}" // ᄒ, ᅡ, ᆫ
// precomposed 是 한, decomposed 是 한
可拓展的字符群集可以使包围记号(例如COMBINING ENCLOSING CIRCLE或者U+20DD)的标量包围其他 Unicode 标量,作为一个单一的Character值:
let enclosedEAcute: Character = "\u{E9}\u{20DD}"
// enclosedEAcute 是 é⃝
地域性指示符号的 Unicode 标量可以组合成一个单一的Character值,例如REGIONAL INDICATOR SYMBOL LETTER U(U+1F1FA)和REGIONAL INDICATOR SYMBOL LETTER S(U+1F1F8):
let regionalIndicatorForUS: Character = "\u{1F1FA}\u{1F1F8}"
// regionalIndicatorForUS 是 🇺🇸
10 计算字符数量
如果想要获得一个字符串中Character值的数量,可以使用count属性:
let unusualMenagerie = "Koala 🐨, Snail 🐌, Penguin 🐧, Dromedary 🐪"
print("unusualMenagerie has \(unusualMenagerie.count) characters")
// 打印输出 "unusualMenagerie has 40 characters"
注意在 Swift 中,使用可拓展的字符群集作为Character值来连接或改变字符串时,并不一定会更改字符串的字符数量。
例如,如果你用四个字符的单词cafe初始化一个新的字符串,然后添加一个COMBINING ACTUE ACCENT(U+0301)作为字符串的结尾。最终这个字符串的字符数量仍然是4,因为第四个字符是é,而不是e:
var word = "cafe"
print("the number of characters in \(word) is \(word.count)")
// 打印输出 "the number of characters in cafe is 4"
word += "\u{301}" // 拼接一个重音,U+0301
print("the number of characters in \(word) is \(word.count)")
// 打印输出 "the number of characters in café is 4"
注意: 可扩展的字符群集可以组成一个或者多个 Unicode 标量。这意味着不同的字符以及相同字符的不同表示方式可能需要不同数量的内存空间来存储。所以 Swift 中的字符在一个字符串中并不一定占用相同的内存空间数量。因此在没有获取字符串的可扩展的字符群的范围时候,就不能计算出字符串的字符数量。如果您正在处理一个长字符串,需要注意count属性必须遍历全部的 Unicode 标量,来确定字符串的字符数量。
另外需要注意的是通过count属性返回的字符数量并不总是与包含相同字符的NSString的length属性相同。NSString的length属性是利用 UTF-16 表示的十六位代码单元数字,而不是 Unicode 可扩展的字符群集。
11 访问和修改字符串
你可以通过字符串的属性和方法来访问和修改它,当然也可以用下标语法完成。
11.1 字符串索引
每一个String值都有一个关联的索引(index)类型,String.Index,它对应着字符串中的每一个Character的位置。
前面提到,不同的字符可能会占用不同数量的内存空间,所以要知道Character的确定位置,就必须从String开头遍历每一个 Unicode 标量直到结尾。因此,Swift 的字符串不能用整数(integer)做索引。
使用startIndex属性可以获取一个String的第一个Character的索引。使用endIndex属性可以获取最后一个Character的后一个位置的索引。因此,endIndex属性不能作为一个字符串的有效下标。如果String是空串,startIndex和endIndex是相等的。
通过调用 String 的 index(before:) 或 index(after:) 方法,可以立即得到前面或后面的一个索引。您还可以通过调用 index(_:offsetBy:) 方法来获取对应偏移量的索引,这种方式可以避免多次调用 index(before:) 或 index(after:) 方法。
你可以使用下标语法来访问 String 特定索引的 Character。
let greeting = "Guten Tag!"
greeting[greeting.startIndex]
// G
greeting[greeting.index(before: greeting.endIndex)]
// !
greeting[greeting.index(after: greeting.startIndex)]
// u
let index = greeting.index(greeting.startIndex, offsetBy: 7)
greeting[index]
// a
试图获取越界索引对应的 Character,将引发一个运行时错误。
greeting[greeting.endIndex] // error
greeting.index(after: endIndex) // error
使用 indices 属性会创建一个包含全部索引的范围(Range),用来在一个字符串中访问单个字符。
for index in greeting.indices {
print("\(greeting[index]) ", terminator: "")
}
// 打印输出 "G u t e n T a g ! "
注意: 您可以使用 startIndex 和 endIndex 属性或者 index(before:) 、index(after:) 和 index(_:offsetBy:) 方法在任意一个确认的并遵循 Collection 协议的类型里面,如上文所示是使用在 String 中,您也可以使用在 Array、Dictionary 和 Set中。
11.2 插入和删除
调用 insert(_:at:) 方法可以在一个字符串的指定索引插入一个字符,调用 insert(contentsOf:at:) 方法可以在一个字符串的指定索引插入一个段字符串。
var welcome = "hello"
welcome.insert("!", at: welcome.endIndex)
// welcome 变量现在等于 "hello!"
welcome.insert(contentsOf:" there", at: welcome.index(before: welcome.endIndex))
// welcome 变量现在等于 "hello there!"
调用 remove(at:) 方法可以在一个字符串的指定索引删除一个字符,调用 removeSubrange(_:) 方法可以在一个字符串的指定索引删除一个子字符串。
welcome.remove(at: welcome.index(before: welcome.endIndex))
// welcome 现在等于 "hello there"
let range = welcome.index(welcome.endIndex, offsetBy: -6)..<welcome.endIndex
welcome.removeSubrange(range)
// welcome 现在等于 "hello"
注意: 您可以使用
insert(_:at:)、insert(contentsOf:at:)、remove(at:) 和 removeSubrange(_:)方法在任意一个确认的并遵循 RangeReplaceableCollection 协议的类型里面,如上文所示是使用在 String 中,您也可以使用在 Array、Dictionary 和 Set 中。
12 子字符串
当你从字符串中获取一个子字符串 —— 例如,使用下标或者 prefix(_:) 之类的方法 —— 就可以得到一个 SubString 的实例,而非另外一个 String。Swift 里的 SubString 绝大部分函数都跟 String 一样,意味着你可以使用同样的方式去操作 SubString 和 String。然而,跟 String 不同的是,你只有在短时间内需要操作字符串时,才会使用 SubString。当你需要长时间保存结果时,就把 SubString 转化为 String 的实例:
et greeting = "Hello, world!"
let index = greeting.index(of: ",") ?? greeting.endIndex
let beginning = greeting[..<index]
// beginning 的值为 "Hello"
// 把结果转化为 String 以便长期存储。
let newString = String(beginning)
就像 String,每一个 SubString 都会在内存里保存字符集。而 String 和 SubString 的区别在于性能优化上,SubString 可以重用原 String 的内存空间,或者另一个 SubString 的内存空间(String 也有同样的优化,但如果两个 String 共享内存的话,它们就会相等)。这一优化意味着你在修改 String 和 SubString 之前都不需要消耗性能去复制内存。就像前面说的那样,SubString 不适合长期存储 —— 因为它重用了原 String 的内存空间,原 String 的内存空间必须保留直到它的 SubString 不再被使用为止。
上面的例子,greeting 是一个 String,意味着它在内存里有一片空间保存字符集。而由于 beginning 是 greeting 的 SubString,它重用了 greeting 的内存空间。相反,newString 是一个 String —— 它是使用 SubString 创建的,拥有一片自己的内存空间。
注意 String 和 SubString 都遵循 StringProtocol<//apple_ref/swift/intf/s:s14StringProtocolP> 协议,这意味着操作字符串的函数使用 StringProtocol 会更加方便。你可以传入 String 或 SubString 去调用函数。
13 比较字符串
Swift 提供了三种方式来比较文本值:字符串字符相等、前缀相等和后缀相等。
13.1 字符串/字符相等
字符串/字符可以用等于操作符(==)和不等于操作符(!=),详细描述在比较运算符:
let quotation = "We're a lot alike, you and I."
let sameQuotation = "We're a lot alike, you and I."
if quotation == sameQuotation {
print("These two strings are considered equal")
}
// 打印输出 "These two strings are considered equal"
如果两个字符串(或者两个字符)的可扩展的字形群集是标准相等的,那就认为它们是相等的。在这个情况下,即使可扩展的字形群集是有不同的 Unicode 标量构成的,只要它们有同样的语言意义和外观,就认为它们标准相等。
例如,LATIN SMALL LETTER E WITH ACUTE(U+00E9)就是标准相等于LATIN SMALL LETTER E(U+0065)后面加上COMBINING ACUTE ACCENT(U+0301)。这两个字符群集都是表示字符é的有效方式,所以它们被认为是标准相等的:
// "Voulez-vous un café?" 使用 LATIN SMALL LETTER E WITH ACUTE
let eAcuteQuestion = "Voulez-vous un caf\u{E9}?"
// "Voulez-vous un café?" 使用 LATIN SMALL LETTER E and COMBINING ACUTE ACCENT
let combinedEAcuteQuestion = "Voulez-vous un caf\u{65}\u{301}?"
if eAcuteQuestion == combinedEAcuteQuestion {
print("These two strings are considered equal")
}
// 打印输出 "These two strings are considered equal"
相反,英语中的LATIN CAPITAL LETTER A(U+0041,或者A)不等于俄语中的CYRILLIC CAPITAL LETTER A(U+0410,或者A)。两个字符看着是一样的,但却有不同的语言意义:
let latinCapitalLetterA: Character = "\u{41}"
let cyrillicCapitalLetterA: Character = "\u{0410}"
if latinCapitalLetterA != cyrillicCapitalLetterA {
print("These two characters are not equivalent")
}
// 打印 "These two characters are not equivalent"
注意: 在 Swift 中,字符串和字符并不区分地域(not locale-sensitive)。
13.2 前缀/后缀相等
通过调用字符串的hasPrefix(_:)/hasSuffix(_:)方法来检查字符串是否拥有特定前缀/后缀,两个方法均接收一个String类型的参数,并返回一个布尔值。
下面的例子以一个字符串数组表示莎士比亚话剧《罗密欧与朱丽叶》中前两场的场景位置:
let romeoAndJuliet = [
"Act 1 Scene 1: Verona, A public place",
"Act 1 Scene 2: Capulet's mansion",
"Act 1 Scene 3: A room in Capulet's mansion",
"Act 1 Scene 4: A street outside Capulet's mansion",
"Act 1 Scene 5: The Great Hall in Capulet's mansion",
"Act 2 Scene 1: Outside Capulet's mansion",
"Act 2 Scene 2: Capulet's orchard",
"Act 2 Scene 3: Outside Friar Lawrence's cell",
"Act 2 Scene 4: A street in Verona",
"Act 2 Scene 5: Capulet's mansion",
"Act 2 Scene 6: Friar Lawrence's cell"
]
您可以调用hasPrefix(_:)方法来计算话剧中第一幕的场景数:
var act1SceneCount = 0
for scene in romeoAndJuliet {
if scene.hasPrefix("Act 1 ") {
act1SceneCount += 1
}
}
print("There are \(act1SceneCount) scenes in Act 1")
// 打印输出 "There are 5 scenes in Act 1"
相似地,您可以用hasSuffix(_:)方法来计算发生在不同地方的场景数:
var mansionCount = 0
var cellCount = 0
for scene in romeoAndJuliet {
if scene.hasSuffix("Capulet's mansion") {
mansionCount += 1
} else if scene.hasSuffix("Friar Lawrence's cell") {
cellCount += 1
}
}
print("\(mansionCount) mansion scenes; \(cellCount) cell scenes")
// 打印输出 "6 mansion scenes; 2 cell scenes"
注意: hasPrefix(_:)和hasSuffix(_:)方法都是在每个字符串中逐字符比较其可扩展的字符群集是否标准相等,详细描述在字符串/字符相等。
集合类型
1 集合的可变性
Swift 语言提供Arrays、Sets和Dictionaries三种基本的集合类型用来存储集合数据。数组(Arrays)是有序数据的集。集合(Sets)是无序无重复数据的集。字典(Dictionaries)是无序的键值对的集。
Swift 语言中的Arrays、Sets和Dictionaries中存储的数据值类型必须明确。这意味着我们不能把不正确的数据类型插入其中。同时这也说明我们完全可以对取回值的类型非常自信。
注意: Swift 的Arrays、Sets和Dictionaries类型被实现为泛型集合。更多关于泛型类型和集合,参见 泛型章节。
如果创建一个Arrays、Sets或Dictionaries并且把它分配成一个变量,这个集合将会是可变的。这意味着我们可以在创建之后添加更多或移除已存在的数据项,或者改变集合中的数据项。如果我们把Arrays、Sets或Dictionaries分配成常量,那么它就是不可变的,它的大小和内容都不能被改变。
注意: 在我们不需要改变集合的时候创建不可变集合是很好的实践。如此 Swift 编译器可以优化我们创建的集合。
2 数组
数组使用有序列表存储同一类型的多个值。相同的值可以多次出现在一个数组的不同位置中。
2.1 数组的简单语法
写 Swift 数组应该遵循像Array
2.2 创建一个空数组
我们可以使用构造语法来创建一个由特定数据类型构成的空数组:
var someInts = [Int]()
print("someInts is of type [Int] with \(someInts.count) items.")
// 打印 "someInts is of type [Int] with 0 items."
注意,通过构造函数的类型,someInts的值类型被推断为[Int]。
或者,如果代码上下文中已经提供了类型信息,例如一个函数参数或者一个已经定义好类型的常量或者变量,我们可以使用空数组语句创建一个空数组,它的写法很简单:[](一对空方括号):
someInts.append(3)
// someInts 现在包含一个 Int 值
someInts = []
// someInts 现在是空数组,但是仍然是 [Int] 类型的。
2.3 创建一个带有默认值的数组
Swift 中的Array类型还提供一个可以创建特定大小并且所有数据都被默认的构造方法。我们可以把准备加入新数组的数据项数量(count)和适当类型的初始值(repeating)传入数组构造函数:
var threeDoubles = Array(repeating: 0.0, count: 3)
// threeDoubles 是一种 [Double] 数组,等价于 [0.0, 0.0, 0.0]
2.4 通过两个数组相加创建一个数组
我们可以使用加法操作符(+)来组合两种已存在的相同类型数组。新数组的数据类型会被从两个数组的数据类型中推断出来:
var anotherThreeDoubles = Array(repeating: 2.5, count: 3)
// anotherThreeDoubles 被推断为 [Double],等价于 [2.5, 2.5, 2.5]
var sixDoubles = threeDoubles + anotherThreeDoubles
// sixDoubles 被推断为 [Double],等价于 [0.0, 0.0, 0.0, 2.5, 2.5, 2.5]
2.5 用数组字面量构造数组
我们可以使用数组字面量来进行数组构造,这是一种用一个或者多个数值构造数组的简单方法。数组字面量是一系列由逗号分割并由方括号包含的数值:[value 1, value 2, value 3]。
下面这个例子创建了一个叫做shoppingList并且存储String的数组:
var shoppingList: [String] = ["Eggs", "Milk"]
// shoppingList 已经被构造并且拥有两个初始项。
shoppingList变量被声明为“字符串值类型的数组“,记作[String]。 因为这个数组被规定只有String一种数据结构,所以只有String类型可以在其中被存取。 在这里,shoppingList数组由两个String值(”Eggs” 和”Milk”)构造,并且由数组字面量定义。
注意: shoppingList数组被声明为变量(var关键字创建)而不是常量(let创建)是因为以后可能会有更多的数据项被插入其中。
在这个例子中,字面量仅仅包含两个String值。匹配了该数组的变量声明(只能包含String的数组),所以这个字面量的分配过程可以作为用两个初始项来构造shoppingList的一种方式。
由于 Swift 的类型推断机制,当我们用字面量构造只拥有相同类型值数组的时候,我们不必把数组的类型定义清楚。 shoppingList的构造也可以这样写:
var shoppingList = ["Eggs", "Milk"]
因为所有数组字面量中的值都是相同的类型,Swift 可以推断出[String]是shoppingList中变量的正确类型。
2.6 访问和修改数组
我们可以通过数组的方法和属性来访问和修改数组,或者使用下标语法。
可以使用数组的只读属性count来获取数组中的数据项数量:
print("The shopping list contains \(shoppingList.count) items.")
// 输出 "The shopping list contains 2 items."(这个数组有2个项)
使用布尔属性isEmpty作为一个缩写形式去检查count属性是否为0:
if shoppingList.isEmpty {
print("The shopping list is empty.")
} else {
print("The shopping list is not empty.")
}
// 打印 "The shopping list is not empty."(shoppinglist 不是空的)
也可以使用append(_:)方法在数组后面添加新的数据项:
shoppingList.append("Flour")
// shoppingList 现在有3个数据项,有人在摊煎饼
除此之外,使用加法赋值运算符(+=)也可以直接在数组后面添加一个或多个拥有相同类型的数据项:
shoppingList += ["Baking Powder"]
// shoppingList 现在有四项了
shoppingList += ["Chocolate Spread", "Cheese", "Butter"]
// shoppingList 现在有七项了
可以直接使用下标语法来获取数组中的数据项,把我们需要的数据项的索引值放在直接放在数组名称的方括号中:
var firstItem = shoppingList[0]
// 第一项是 "Eggs"
注意: 第一项在数组中的索引值是0而不是1。 Swift 中的数组索引总是从零开始。
我们也可以用下标来改变某个已有索引值对应的数据值:
shoppingList[0] = "Six eggs"
// 其中的第一项现在是 "Six eggs" 而不是 "Eggs"
还可以利用下标来一次改变一系列数据值,即使新数据和原有数据的数量是不一样的。下面的例子把”Chocolate Spread”,”Cheese”,和”Butter”替换为”Bananas”和 “Apples”:
shoppingList[4...6] = ["Bananas", "Apples"]
// shoppingList 现在有6项
注意: 不可以用下标访问的形式去在数组尾部添加新项。
调用数组的insert(_:at:)方法来在某个具体索引值之前添加数据项:
shoppingList.insert("Maple Syrup", at: 0)
// shoppingList 现在有7项
// "Maple Syrup" 现在是这个列表中的第一项
这次insert(_:at:)方法调用把值为”Maple Syrup”的新数据项插入列表的最开始位置,并且使用0作为索引值。
类似的我们可以使用remove(at:)方法来移除数组中的某一项。这个方法把数组在特定索引值中存储的数据项移除并且返回这个被移除的数据项(我们不需要的时候就可以无视它):
let mapleSyrup = shoppingList.remove(at: 0)
// 索引值为0的数据项被移除
// shoppingList 现在只有6项,而且不包括 Maple Syrup
// mapleSyrup 常量的值等于被移除数据项的值 "Maple Syrup"
注意: 如果我们试着对索引越界的数据进行检索或者设置新值的操作,会引发一个运行期错误。我们可以使用索引值和数组的count属性进行比较来在使用某个索引之前先检验是否有效。除了当count等于 0 时(说明这是个空数组),最大索引值一直是count - 1,因为数组都是零起索引。
数据项被移除后数组中的空出项会被自动填补,所以现在索引值为0的数据项的值再次等于”Six eggs”:
firstItem = shoppingList[0]
// firstItem 现在等于 "Six eggs"
如果我们只想把数组中的最后一项移除,可以使用removeLast()方法而不是remove(at:)方法来避免我们需要获取数组的count属性。就像后者一样,前者也会返回被移除的数据项:
let apples = shoppingList.removeLast()
// 数组的最后一项被移除了
// shoppingList 现在只有5项,不包括 Apples
// apples 常量的值现在等于 "Apples" 字符串
2.7 数组的遍历
我们可以使用for-in循环来遍历所有数组中的数据项:
for item in shoppingList {
print(item)
}
// Six eggs
// Milk
// Flour
// Baking Powder
// Bananas
如果我们同时需要每个数据项的值和索引值,可以使用enumerated()方法来进行数组遍历。enumerated()返回一个由每一个数据项索引值和数据值组成的元组。我们可以把这个元组分解成临时常量或者变量来进行遍历:
for (index, value) in shoppingList. enumerated() {
print("Item \(String(index + 1)): \(value)")
}
// Item 1: Six eggs
// Item 2: Milk
// Item 3: Flour
// Item 4: Baking Powder
// Item 5: Bananas
3 集合(Sets)
集合(Set)用来存储相同类型并且没有确定顺序的值。当集合元素顺序不重要时或者希望确保每个元素只出现一次时可以使用集合而不是数组。
3.1 集合类型的哈希值
一个类型为了存储在集合中,该类型必须是可哈希化的–也就是说,该类型必须提供一个方法来计算它的哈希值。一个哈希值是Int类型的,相等的对象哈希值必须相同,比如a==b,因此必须a.hashValue == b.hashValue。
Swift 的所有基本类型(比如String,Int,Double和Bool)默认都是可哈希化的,可以作为集合的值的类型或者字典的键的类型。没有关联值的枚举成员值(在枚举有讲述)默认也是可哈希化的。
注意: 你可以使用你自定义的类型作为集合的值的类型或者是字典的键的类型,但你需要使你的自定义类型符合 Swift 标准库中的Hashable协议。符合Hashable协议的类型需要提供一个类型为Int的可读属性hashValue。由类型的hashValue属性返回的值不需要在同一程序的不同执行周期或者不同程序之间保持相同。
因为Hashable协议符合Equatable协议,所以遵循该协议的类型也必须提供一个”是否相等”运算符(==)的实现。这个Equatable协议要求任何符合==实现的实例间都是一种相等的关系。也就是说,对于a,b,c三个值来说,==的实现必须满足下面三种情况:
- a == a(自反性)
- a == b意味着b == a(对称性)
- a == b && b == c意味着a == c(传递性)
3.2 集合类型语法
Swift 中的Set类型被写为Set
3.3 创建和构造一个空的集合
你可以通过构造器语法创建一个特定类型的空集合:
var letters = Set<Character>()
print("letters is of type Set<Character> with \(letters.count) items.")
// 打印 "letters is of type Set<Character> with 0 items."
注意: 通过构造器,这里的letters变量的类型被推断为Set
。
此外,如果上下文提供了类型信息,比如作为函数的参数或者已知类型的变量或常量,我们可以通过一个空的数组字面量创建一个空的Set:
letters.insert("a")
// letters 现在含有1个 Character 类型的值
letters = []
// letters 现在是一个空的 Set, 但是它依然是 Set<Character> 类型
3.4 用数组字面量创建集合
你可以使用数组字面量来构造集合,并且可以使用简化形式写一个或者多个值作为集合元素。
下面的例子创建一个称之为favoriteGenres的集合来存储String类型的值:
var favoriteGenres: Set<String> = ["Rock", "Classical", "Hip hop"]
// favoriteGenres 被构造成含有三个初始值的集合
这个favoriteGenres变量被声明为“一个String值的集合”,写为Set
注意: favoriteGenres被声明为一个变量(拥有var标示符)而不是一个常量(拥有let标示符),因为它里面的元素将会在下面的例子中被增加或者移除。
一个Set类型不能从数组字面量中被单独推断出来,因此Set类型必须显式声明。然而,由于 Swift 的类型推断功能,如果你想使用一个数组字面量构造一个Set并且该数组字面量中的所有元素类型相同,那么你无须写出Set的具体类型。favoriteGenres的构造形式可以采用简化的方式代替:
var favoriteGenres: Set = ["Rock", "Classical", "Hip hop"]
由于数组字面量中的所有元素类型相同,Swift 可以推断出Set
3.5 访问和修改一个集合
你可以通过Set的属性和方法来访问和修改一个Set。 为了找出一个Set中元素的数量,可以使用其只读属性count:
print("I have \(favoriteGenres.count) favorite music genres.")
// 打印 "I have 3 favorite music genres."
使用布尔属性isEmpty作为一个缩写形式去检查count属性是否为0:
if favoriteGenres.isEmpty {
print("As far as music goes, I'm not picky.")
} else {
print("I have particular music preferences.")
}
// 打印 "I have particular music preferences."
你可以通过调用Set的insert(_:)方法来添加一个新元素:
favoriteGenres.insert("Jazz")
// favoriteGenres 现在包含4个元素
你可以通过调用Set的remove(_:)方法去删除一个元素,如果该值是该Set的一个元素则删除该元素并且返回被删除的元素值,否则如果该Set不包含该值,则返回nil。另外,Set中的所有元素可以通过它的removeAll()方法删除。
if let removedGenre = favoriteGenres.remove("Rock") {
print("\(removedGenre)? I'm over it.")
} else {
print("I never much cared for that.")
}
// 打印 "Rock? I'm over it."
使用contains(_:)方法去检查Set中是否包含一个特定的值:
if favoriteGenres.contains("Funk") {
print("I get up on the good foot.")
} else {
print("It's too funky in here.")
}
// 打印 "It's too funky in here."
3.6 遍历一个集合
你可以在一个for-in循环中遍历一个Set中的所有值。
for genre in favoriteGenres {
print("\(genre)")
}
// Classical
// Jazz
// Hip hop
Swift 的Set类型没有确定的顺序,为了按照特定顺序来遍历一个Set中的值可以使用sorted()方法,它将返回一个有序数组,这个数组的元素排列顺序由操作符’<’对元素进行比较的结果来确定。
for genre in favoriteGenres.sorted() {
print("\(genre)")
}
// prints "Classical"
// prints "Hip hop"
// prints "Jazz
3.7 集合操作
你可以高效地完成Set的一些基本操作,比如把两个集合组合到一起,判断两个集合共有元素,或者判断两个集合是否全包含,部分包含或者不相交。
下面的插图描述了两个集合a和b以及通过阴影部分的区域显示集合各种操作的结果。
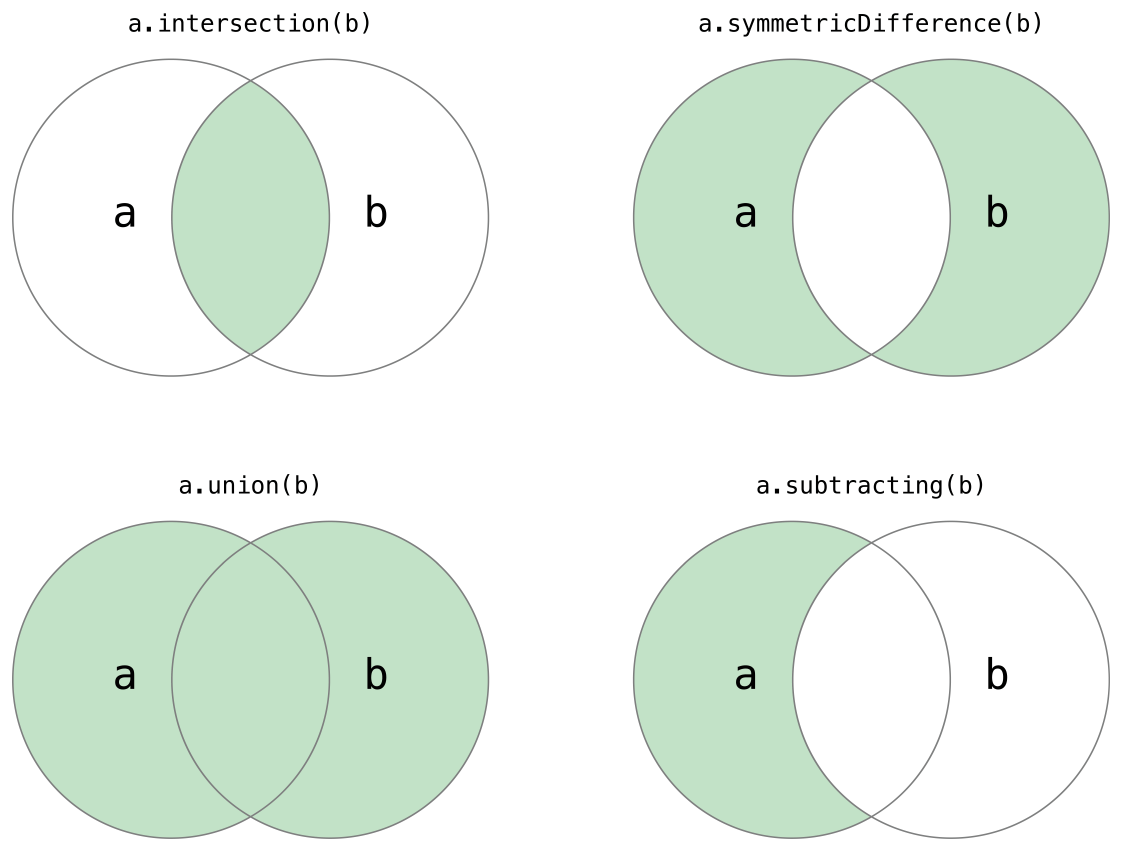
- 使用intersection(_:)方法根据两个集合中都包含的值创建的一个新的集合。
- 使用symmetricDifference(_:)方法根据在一个集合中但不在两个集合中的值创建一个新的集合。
- 使用union(_:)方法根据两个集合的值创建一个新的集合。
- 使用subtracting(_:)方法根据不在该集合中的值创建一个新的集合。
let oddDigits: Set = [1, 3, 5, 7, 9]
let evenDigits: Set = [0, 2, 4, 6, 8]
let singleDigitPrimeNumbers: Set = [2, 3, 5, 7]
oddDigits.union(evenDigits).sorted()
// [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
oddDigits. intersection(evenDigits).sorted()
// []
oddDigits.subtracting(singleDigitPrimeNumbers).sorted()
// [1, 9]
oddDigits. symmetricDifference(singleDigitPrimeNumbers).sorted()
// [1, 2, 9]
下面的插图描述了三个集合a,b和c,以及通过重叠区域表述集合间共享的元素。集合a是集合b的父集合,因为a包含了b中所有的元素,相反的,集合b是集合a的子集合,因为属于b的元素也被a包含。集合b和集合c彼此不关联,因为它们之间没有共同的元素。
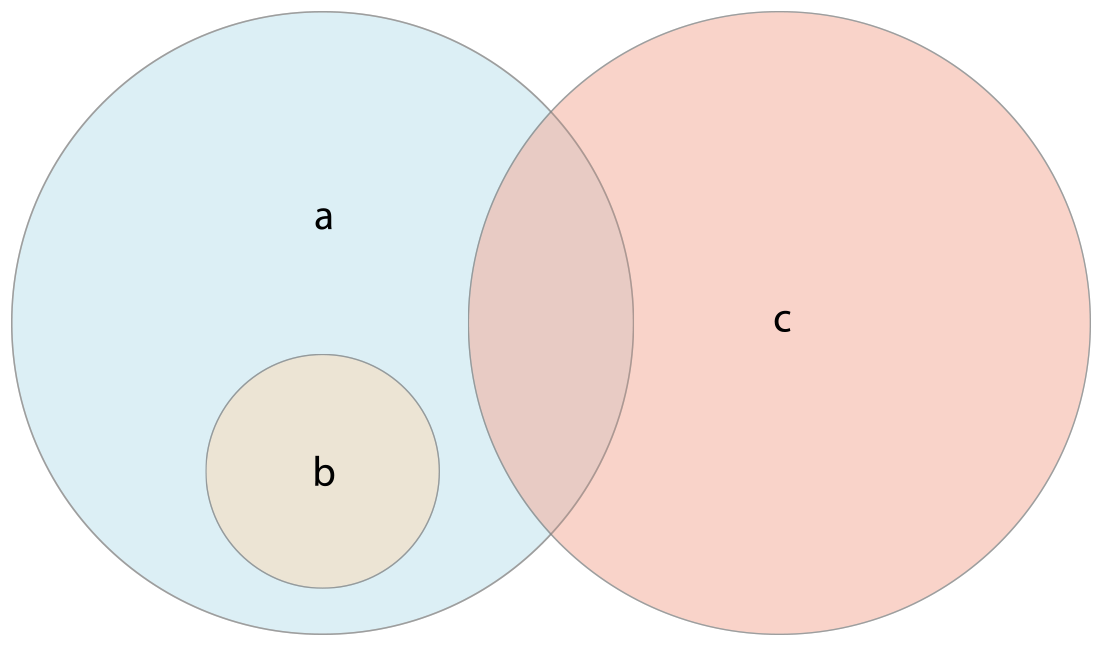
- 使用“是否相等”运算符(==)来判断两个集合是否包含全部相同的值。
- 使用isSubset(of:)方法来判断一个集合中的值是否也被包含在另外一个集合中。
- 使用isSuperset(of:)方法来判断一个集合中包含另一个集合中所有的值。
- 使用isStrictSubset(of:)或者isStrictSuperset(of:)方法来判断一个集合是否是另外一个集合的子集合或者父集合并且两个集合并不相等。
- 使用isDisjoint(with:)方法来判断两个集合是否不含有相同的值(是否没有交集)。
let houseAnimals: Set = ["🐶", "🐱"]
let farmAnimals: Set = ["🐮", "🐔", "🐑", "🐶", "🐱"]
let cityAnimals: Set = ["🐦", "🐭"]
houseAnimals.isSubset(of: farmAnimals)
// true
farmAnimals.isSuperset(of: houseAnimals)
// true
farmAnimals.isDisjoint(with: cityAnimals)
// true
4 字典
字典是一种存储多个相同类型的值的容器。每个值(value)都关联唯一的键(key),键作为字典中的这个值数据的标识符。和数组中的数据项不同,字典中的数据项并没有具体顺序。我们在需要通过标识符(键)访问数据的时候使用字典,这种方法很大程度上和我们在现实世界中使用字典查字义的方法一样。
4.1 字典类型简化语法
Swift 的字典使用Dictionary<Key, Value>定义,其中Key是字典中键的数据类型,Value是字典中对应于这些键所存储值的数据类型。
注意: 一个字典的Key类型必须遵循Hashable协议,就像Set的值类型。
我们也可以用[Key: Value]这样简化的形式去创建一个字典类型。虽然这两种形式功能上相同,但是后者是首选,并且这本指导书涉及到字典类型时通篇采用后者。
4.2 创建一个空字典
我们可以像数组一样使用构造语法创建一个拥有确定类型的空字典:
var namesOfIntegers = [Int: String]()
// namesOfIntegers 是一个空的 [Int: String] 字典
这个例子创建了一个[Int: String]类型的空字典来储存整数的英语命名。它的键是Int型,值是String型。
如果上下文已经提供了类型信息,我们可以使用空字典字面量来创建一个空字典,记作[:](中括号中放一个冒号):
namesOfIntegers[16] = "sixteen"
// namesOfIntegers 现在包含一个键值对
namesOfIntegers = [:]
// namesOfIntegers 又成为了一个 [Int: String] 类型的空字典
4.3 用字典字面量创建字典
我们可以使用字典字面量来构造字典,这和我们刚才介绍过的数组字面量拥有相似语法。字典字面量是一种将一个或多个键值对写作Dictionary集合的快捷途径。
一个键值对是一个key和一个value的结合体。在字典字面量中,每一个键值对的键和值都由冒号分割。这些键值对构成一个列表,其中这些键值对由方括号包含、由逗号分割:
[key 1: value 1, key 2: value 2, key 3: value 3]
下面的例子创建了一个存储国际机场名称的字典。在这个字典中键是三个字母的国际航空运输相关代码,值是机场名称:
var airports: [String: String] = ["YYZ": "Toronto Pearson", "DUB": "Dublin"]
airports字典被声明为一种[String: String]类型,这意味着这个字典的键和值都是String类型。
注意: airports字典被声明为变量(用var关键字)而不是常量(let关键字)因为后来更多的机场信息会被添加到这个示例字典中。
airports字典使用字典字面量初始化,包含两个键值对。第一对的键是YYZ,值是Toronto Pearson。第二对的键是DUB,值是Dublin。
这个字典语句包含了两个String: String类型的键值对。它们对应airports变量声明的类型(一个只有String键和String值的字典)所以这个字典字面量的任务是构造拥有两个初始数据项的airport字典。
和数组一样,我们在用字典字面量构造字典时,如果它的键和值都有各自一致的类型,那么就不必写出字典的类型。 airports字典也可以用这种简短方式定义:
var airports = ["YYZ": "Toronto Pearson", "DUB": "Dublin"]
因为这个语句中所有的键和值都各自拥有相同的数据类型,Swift 可以推断出Dictionary<String, String>是airports字典的正确类型。
4.4 访问和修改字典
我们可以通过字典的方法和属性来访问和修改字典,或者通过使用下标语法。
和数组一样,我们可以通过字典的只读属性count来获取某个字典的数据项数量:
print("The dictionary of airports contains \(airports.count) items.")
// 打印 "The dictionary of airports contains 2 items."(这个字典有两个数据项)
使用布尔属性isEmpty作为一个缩写形式去检查count属性是否为0:
if airports.isEmpty {
print("The airports dictionary is empty.")
} else {
print("The airports dictionary is not empty.")
}
// 打印 "The airports dictionary is not empty."
我们也可以在字典中使用下标语法来添加新的数据项。可以使用一个恰当类型的键作为下标索引,并且分配恰当类型的新值:
airports["LHR"] = "London"
// airports 字典现在有三个数据项
我们也可以使用下标语法来改变特定键对应的值:
airports["LHR"] = "London Heathrow"
// "LHR"对应的值 被改为 "London Heathrow
作为另一种下标方法,字典的updateValue(_:forKey:)方法可以设置或者更新特定键对应的值。就像上面所示的下标示例,updateValue(_:forKey:)方法在这个键不存在对应值的时候会设置新值或者在存在时更新已存在的值。和上面的下标方法不同的,updateValue(_:forKey:)这个方法返回更新值之前的原值。这样使得我们可以检查更新是否成功。
updateValue(_:forKey:)方法会返回对应值的类型的可选值。举例来说:对于存储String值的字典,这个函数会返回一个String?或者“可选 String”类型的值。
如果有值存在于更新前,则这个可选值包含了旧值,否则它将会是nil。
if let oldValue = airports.updateValue("Dublin Airport", forKey: "DUB") {
print("The old value for DUB was \(oldValue).")
}
// 输出 "The old value for DUB was Dublin."
我们也可以使用下标语法来在字典中检索特定键对应的值。因为有可能请求的键没有对应的值存在,字典的下标访问会返回对应值的类型的可选值。如果这个字典包含请求键所对应的值,下标会返回一个包含这个存在值的可选值,否则将返回nil:
if let airportName = airports["DUB"] {
print("The name of the airport is \(airportName).")
} else {
print("That airport is not in the airports dictionary.")
}
// 打印 "The name of the airport is Dublin Airport."
我们还可以使用下标语法来通过给某个键的对应值赋值为nil来从字典里移除一个键值对:
airports["APL"] = "Apple Internation"
// "Apple Internation" 不是真的 APL 机场,删除它
airports["APL"] = nil
// APL 现在被移除了
此外,removeValue(forKey:)方法也可以用来在字典中移除键值对。这个方法在键值对存在的情况下会移除该键值对并且返回被移除的值或者在没有值的情况下返回nil:
if let removedValue = airports. removeValue(forKey: "DUB") {
print("The removed airport's name is \(removedValue).")
} else {
print("The airports dictionary does not contain a value for DUB.")
}
// prints "The removed airport's name is Dublin Airport."
4.6 字典遍历
我们可以使用for-in循环来遍历某个字典中的键值对。每一个字典中的数据项都以(key, value)元组形式返回,并且我们可以使用临时常量或者变量来分解这些元组:
for (airportCode, airportName) in airports {
print("\(airportCode): \(airportName)")
}
// YYZ: Toronto Pearson
// LHR: London Heathrow
通过访问keys或者values属性,我们也可以遍历字典的键或者值:
for airportCode in airports.keys {
print("Airport code: \(airportCode)")
}
// Airport code: YYZ
// Airport code: LHR
for airportName in airports.values {
print("Airport name: \(airportName)")
}
// Airport name: Toronto Pearson
// Airport name: London Heathrow
如果我们只是需要使用某个字典的键集合或者值集合来作为某个接受Array实例的 API 的参数,可以直接使用keys或者values属性构造一个新数组:
let airportCodes = [String](airports.keys)
// airportCodes 是 ["YYZ", "LHR"]
let airportNames = [String](airports.values)
// airportNames 是 ["Toronto Pearson", "London Heathrow"]
Swift 的字典类型是无序集合类型。为了以特定的顺序遍历字典的键或值,可以对字典的keys或values属性使用sorted()方法。
控制流
Swift提供了多种流程控制结构,包括可以多次执行任务的while循环,基于特定条件选择执行不同代码分支的if、guard和switch语句,还有控制流程跳转到其他代码位置的break和continue语句。
Swift 还提供了for-in循环,用来更简单地遍历数组(Array),字典(Dictionary),区间(Range),字符串(String)和其他序列类型。
Swift 的switch语句比 C 语言中更加强大。case 还可以匹配很多不同的模式,包括范围匹配,元组(tuple)和特定类型匹配。switch语句的 case 中匹配的值可以声明为临时常量或变量,在 case 作用域内使用,也可以配合where来描述更复杂的匹配条件。
1 For-In 循环
你可以使用 for-in 循环来遍历一个集合中的所有元素,例如数组中的元素、范围内的数字或者字符串中的字符。
以下例子使用 for-in 遍历一个数组所有元素:
let names = ["Anna", "Alex", "Brian", "Jack"]
for name in names {
print("Hello, \(name)!")
}
// Hello, Anna!
// Hello, Alex!
// Hello, Brian!
// Hello, Jack!
你也可以通过遍历一个字典来访问它的键值对。遍历字典时,字典的每项元素会以 (key, value) 元组的形式返回,你可以在 for-in 循环中使用显式的常量名称来解读 (key, value) 元组。下面的例子中,字典的键声明会为 animalName 常量,字典的值会声明为 legCount 常量:
let numberOfLegs = ["spider": 8, "ant": 6, "cat": 4]
for (animalName, legCount) in numberOfLegs {
print("\(animalName)s have \(legCount) legs")
}
// ants have 6 legs
// spiders have 8 legs
// cats have 4 legs
字典的内容理论上是无序的,遍历元素时的顺序是无法确定的。将元素插入字典的顺序并不会决定它们被遍历的顺序。关于数组和字典的细节,参见集合类型。
for-in 循环还可以使用数字范围。下面的例子用来输出乘法表的一部分内容:
for index in 1...5 {
print("\(index) times 5 is \(index * 5)")
}
// 1 times 5 is 5
// 2 times 5 is 10
// 3 times 5 is 15
// 4 times 5 is 20
// 5 times 5 is 25
例子中用来进行遍历的元素是使用闭区间操作符(…)表示的从 1 到 5 的数字区间。index 被赋值为闭区间中的第一个数字(1),然后循环中的语句被执行一次。在本例中,这个循环只包含一个语句,用来输出当前 index 值所对应的乘 5 乘法表的结果。该语句执行后,index 的值被更新为闭区间中的第二个数字(2),之后 print(_:separator:terminator:) 函数会再执行一次。整个过程会进行到闭区间结尾为止。
上面的例子中,index 是一个每次循环遍历开始时被自动赋值的常量。这种情况下,index 在使用前不需要声明,只需要将它包含在循环的声明中,就可以对其进行隐式声明,而无需使用 let 关键字声明。
如果你不需要区间序列内每一项的值,你可以使用下划线(_)替代变量名来忽略这个值:
let base = 3
let power = 10
var answer = 1
for _ in 1...power {
answer *= base
}
print("\(base) to the power of \(power) is \(answer)")
// 输出 "3 to the power of 10 is 59049"
这个例子计算 base 这个数的 power 次幂(本例中,是 3 的 10 次幂),从 1( 3 的 0 次幂)开始做 3 的乘法, 进行 10 次,使用 1 到 10 的闭区间循环。这个计算并不需要知道每一次循环中计数器具体的值,只需要执行了正确的循环次数即可。下划线符号 _ (替代循环中的变量)能够忽略当前值,并且不提供循环遍历时对值的访问。
在某些情况下,你可能不想使用闭区间,包括两个端点。想象一下,你在一个手表上绘制分钟的刻度线。总共 60 个刻度,从 0 分开始。使用半开区间运算符(..<)来表示一个左闭右开的区间。有关区间的更多信息,请参阅区间运算符。
let minutes = 60
for tickMark in 0..<minutes {
// 每一分钟都渲染一个刻度线(60次)
}
一些用户可能在其UI中可能需要较少的刻度。他们可以每5分钟作为一个刻度。使用 stride(from:to:by:) 函数跳过不需要的标记。
let minuteInterval = 5
for tickMark in stride(from: 0, to: minutes, by: minuteInterval) {
// 每5分钟渲染一个刻度线 (0, 5, 10, 15 ... 45, 50, 55)
}
可以在闭区间使用 stride(from:through:by:) 起到同样作用:
let hours = 12
let hourInterval = 3
for tickMark in stride(from: 3, through: hours, by: hourInterval) {
// 每3小时渲染一个刻度线 (3, 6, 9, 12)
}
2 While 循环
while循环会一直运行一段语句直到条件变成false。这类循环适合使用在第一次迭代前,迭代次数未知的情况下。Swift 提供两种while循环形式:
- while循环,每次在循环开始时计算条件是否符合;
- repeat-while循环,每次在循环结束时计算条件是否符合。
2.1 While
while循环从计算一个条件开始。如果条件为true,会重复运行一段语句,直到条件变为false。
下面是 while 循环的一般格式:
while condition {
statements
}
下面的例子来玩一个叫做蛇和梯子(也叫做滑道和梯子)的小游戏:
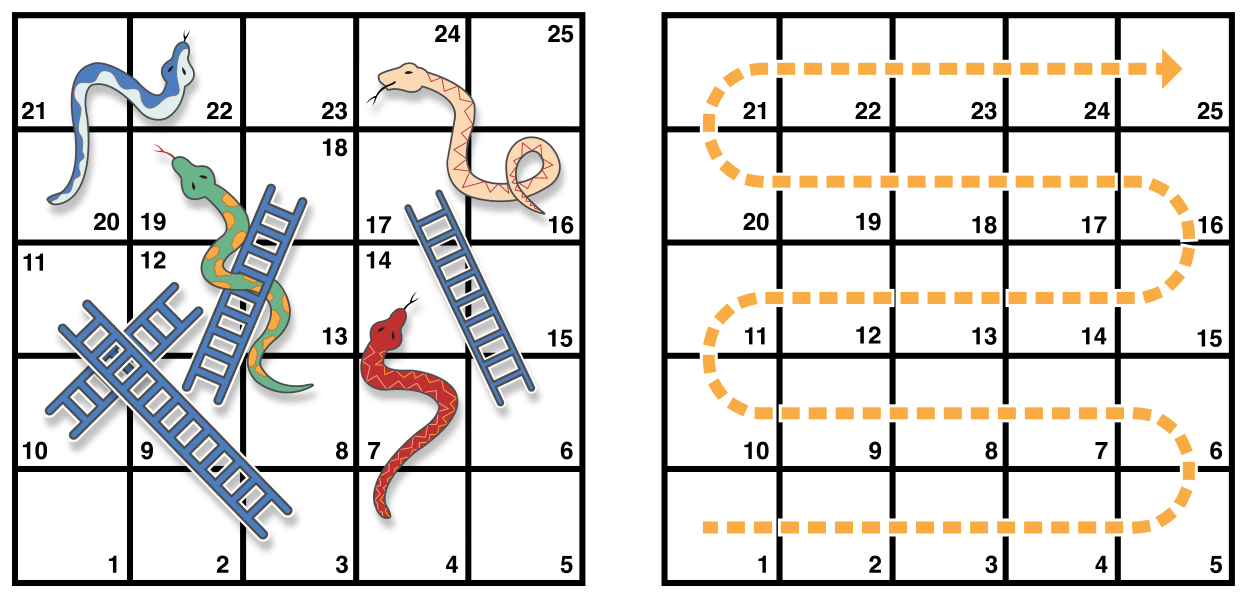
游戏的规则如下:
- 游戏盘面包括 25 个方格,游戏目标是达到或者超过第 25 个方格;
- 每一轮,你通过掷一个六面体骰子来确定你移动方块的步数,移动的路线由上图中横向的虚线所示;
- 如果在某轮结束,你移动到了梯子的底部,可以顺着梯子爬上去;
- 如果在某轮结束,你移动到了蛇的头部,你会顺着蛇的身体滑下去。
游戏盘面可以使用一个Int数组来表达。数组的长度由一个finalSquare常量储存,用来初始化数组和检测最终胜利条件。游戏盘面由 26 个 Int 0 值初始化,而不是 25 个(由0到25,一共 26 个):
let finalSquare = 25
var board = [Int](repeating: 0, count: finalSquare + 1)
一些方格被设置成特定的值来表示有蛇或者梯子。梯子底部的方格是一个正值,使你可以向上移动,蛇头处的方格是一个负值,会让你向下移动:
board[03] = +08; board[06] = +11; board[09] = +09; board[10] = +02
board[14] = -10; board[19] = -11; board[22] = -02; board[24] = -08
3 号方格是梯子的底部,会让你向上移动到 11 号方格,我们使用board[03]等于+08(来表示11和3之间的差值)。为了对齐语句,这里使用了一元正运算符(+i)和一元负运算符(-i),并且小于 10 的数字都使用 0 补齐(这些语法的技巧不是必要的,只是为了让代码看起来更加整洁)。
玩家由左下角空白处编号为 0 的方格开始游戏。玩家第一次掷骰子后才会进入游戏盘面:
var square = 0
var diceRoll = 0
while square < finalSquare {
// 掷骰子
diceRoll += 1
if diceRoll == 7 { diceRoll = 1 }
// 根据点数移动
square += diceRoll
if square < board.count {
// 如果玩家还在棋盘上,顺着梯子爬上去或者顺着蛇滑下去
square += board[square]
}
}
print("Game over!")
本例中使用了最简单的方法来模拟掷骰子。 diceRoll的值并不是一个随机数,而是以0为初始值,之后每一次while循环,diceRoll的值增加 1 ,然后检测是否超出了最大值。当diceRoll的值等于 7 时,就超过了骰子的最大值,会被重置为1。所以diceRoll的取值顺序会一直是 1 ,2,3,4,5,6,1,2 等。
掷完骰子后,玩家向前移动diceRoll个方格,如果玩家移动超过了第 25 个方格,这个时候游戏将会结束,为了应对这种情况,代码会首先判断square的值是否小于board的count属性,只有小于才会在board[square]上增加square,来向前或向后移动(遇到了梯子或者蛇)。
当本轮while循环运行完毕,会再检测循环条件是否需要再运行一次循环。如果玩家移动到或者超过第 25 个方格,循环条件结果为false,此时游戏结束。
while 循环比较适合本例中的这种情况,因为在 while 循环开始时,我们并不知道游戏要跑多久,只有在达成指定条件时循环才会结束。
2.2 Repeat-While
while循环的另外一种形式是repeat-while,它和while的区别是在判断循环条件之前,先执行一次循环的代码块。然后重复循环直到条件为false。
注意: Swift语言的repeat-while循环和其他语言中的do-while循环是类似的。
下面是 repeat-while循环的一般格式:
repeat {
statements
} while condition
还是蛇和梯子的游戏,使用repeat-while循环来替代while循环。finalSquare、board、square和diceRoll的值初始化同while循环时一样:
let finalSquare = 25
var board = [Int](repeating: 0, count: finalSquare + 1)
board[03] = +08; board[06] = +11; board[09] = +09; board[10] = +02
board[14] = -10; board[19] = -11; board[22] = -02; board[24] = -08
var square = 0
var diceRoll = 0
repeat-while的循环版本,循环中第一步就需要去检测是否在梯子或者蛇的方块上。没有梯子会让玩家直接上到第 25 个方格,所以玩家不会通过梯子直接赢得游戏。这样在循环开始时先检测是否踩在梯子或者蛇上是安全的。
游戏开始时,玩家在第 0 个方格上,board[0]一直等于 0, 不会有什么影响:
repeat {
// 顺着梯子爬上去或者顺着蛇滑下去
square += board[square]
// 掷骰子
diceRoll += 1
if diceRoll == 7 { diceRoll = 1 }
// 根据点数移动
square += diceRoll
} while square < finalSquare
print("Game over!")
检测完玩家是否踩在梯子或者蛇上之后,开始掷骰子,然后玩家向前移动diceRoll个方格,本轮循环结束。
循环条件(while square < finalSquare)和while方式相同,但是只会在循环结束后进行计算。在这个游戏中,repeat-while表现得比while循环更好。repeat-while方式会在条件判断square没有超出后直接运行square += board[square],这种方式可以比起前面 while 循环的版本,可以省去数组越界的检查。
3 条件语句
根据特定的条件执行特定的代码通常是十分有用的。当错误发生时,你可能想运行额外的代码;或者,当值太大或太小时,向用户显示一条消息。要实现这些功能,你就需要使用条件语句。
Swift 提供两种类型的条件语句:if语句和switch语句。通常,当条件较为简单且可能的情况很少时,使用if语句。而switch语句更适用于条件较复杂、有更多排列组合的时候。并且switch在需要用到模式匹配(pattern-matching)的情况下会更有用。
3.1 If
if语句最简单的形式就是只包含一个条件,只有该条件为true时,才执行相关代码:
var temperatureInFahrenheit = 30
if temperatureInFahrenheit <= 32 {
print("It's very cold. Consider wearing a scarf.")
}
// 输出 "It's very cold. Consider wearing a scarf."
上面的例子会判断温度是否小于等于 32 华氏度(水的冰点)。如果是,则打印一条消息;否则,不打印任何消息,继续执行if块后面的代码。
当然,if语句允许二选一执行,叫做else从句。也就是当条件为false时,执行 else 语句:
temperatureInFahrenheit = 40
if temperatureInFahrenheit <= 32 {
print("It's very cold. Consider wearing a scarf.")
} else {
print("It's not that cold. Wear a t-shirt.")
}
// 输出 "It's not that cold. Wear a t-shirt."
显然,这两条分支中总有一条会被执行。由于温度已升至 40 华氏度,不算太冷,没必要再围围巾。因此,else分支就被触发了。
你可以把多个if语句链接在一起,来实现更多分支:
temperatureInFahrenheit = 90
if temperatureInFahrenheit <= 32 {
print("It's very cold. Consider wearing a scarf.")
} else if temperatureInFahrenheit >= 86 {
print("It's really warm. Don't forget to wear sunscreen.")
} else {
print("It's not that cold. Wear a t-shirt.")
}
// 输出 "It's really warm. Don't forget to wear sunscreen."
在上面的例子中,额外的if语句用于判断是不是特别热。而最后的else语句被保留了下来,用于打印既不冷也不热时的消息。
实际上,当不需要完整判断情况的时候,最后的else语句是可选的:
temperatureInFahrenheit = 72
if temperatureInFahrenheit <= 32 {
print("It's very cold. Consider wearing a scarf.")
} else if temperatureInFahrenheit >= 86 {
print("It's really warm. Don't forget to wear sunscreen.")
}
在这个例子中,由于既不冷也不热,所以不会触发if或else if分支,也就不会打印任何消息。
3.2 Switch
switch语句会尝试把某个值与若干个模式(pattern)进行匹配。根据第一个匹配成功的模式,switch语句会执行对应的代码。当有可能的情况较多时,通常用switch语句替换if语句。
switch语句最简单的形式就是把某个值与一个或若干个相同类型的值作比较:
switch some value to consider {
case value 1:
respond to value 1
case value 2,
value 3:
respond to value 2 or 3
default:
otherwise, do something else
}
switch语句由多个 case 构成,每个由case关键字开始。为了匹配某些更特定的值,Swift 提供了几种方法来进行更复杂的模式匹配,这些模式将在本节的稍后部分提到。
与if语句类似,每一个 case 都是代码执行的一条分支。switch语句会决定哪一条分支应该被执行,这个流程被称作根据给定的值切换(switching)。
switch语句必须是完备的。这就是说,每一个可能的值都必须至少有一个 case 分支与之对应。在某些不可能涵盖所有值的情况下,你可以使用默认(default)分支来涵盖其它所有没有对应的值,这个默认分支必须在switch语句的最后面。
下面的例子使用switch语句来匹配一个名为someCharacter的小写字符:
let someCharacter: Character = "z"
switch someCharacter {
case "a":
print("The first letter of the alphabet")
case "z":
print("The last letter of the alphabet")
default:
print("Some other character")
}
// 输出 "The last letter of the alphabet"
在这个例子中,第一个 case 分支用于匹配第一个英文字母a,第二个 case 分支用于匹配最后一个字母z。 因为switch语句必须有一个case分支用于覆盖所有可能的字符,而不仅仅是所有的英文字母,所以switch语句使用default分支来匹配除了a和z外的所有值,这个分支保证了swith语句的完备性。
3.2.1 不存在隐式的贯穿
与 C 和 Objective-C 中的switch语句不同,在 Swift 中,当匹配的 case 分支中的代码执行完毕后,程序会终止switch语句,而不会继续执行下一个 case 分支。这也就是说,不需要在 case 分支中显式地使用break语句。这使得switch语句更安全、更易用,也避免了因忘记写break语句而产生的错误。
注意: 虽然在Swift中break不是必须的,但你依然可以在 case 分支中的代码执行完毕前使用break跳出,详情请参见Switch 语句中的 break。
每一个 case 分支都必须包含至少一条语句。像下面这样书写代码是无效的,因为第一个 case 分支是空的:
let anotherCharacter: Character = "a"
switch anotherCharacter {
case "a": // 无效,这个分支下面没有语句
case "A":
print("The letter A")
default:
print("Not the letter A")
}
// 这段代码会报编译错误
不像 C 语言里的switch语句,在 Swift 中,switch语句不会一起匹配”a”和”A”。相反的,上面的代码会引起编译期错误:case “a”: 不包含任何可执行语句——这就避免了意外地从一个 case 分支贯穿到另外一个,使得代码更安全、也更直观。
为了让单个case同时匹配a和A,可以将这个两个值组合成一个复合匹配,并且用逗号分开:
let anotherCharacter: Character = "a"
switch anotherCharacter {
case "a", "A":
print("The letter A")
default:
print("Not the letter A")
}
// 输出 "The letter A
为了可读性,符合匹配可以写成多行形式,详情请参考复合匹配
注意: 如果想要显式贯穿case分支,请使用fallthrough语句,详情请参考贯穿。
3.2.2 区间匹配
case 分支的模式也可以是一个值的区间。下面的例子展示了如何使用区间匹配来输出任意数字对应的自然语言格式:
let approximateCount = 62
let countedThings = "moons orbiting Saturn"
let naturalCount: String
switch approximateCount {
case 0:
naturalCount = "no"
case 1..<5:
naturalCount = "a few"
case 5..<12:
naturalCount = "several"
case 12..<100:
naturalCount = "dozens of"
case 100..<1000:
naturalCount = "hundreds of"
default:
naturalCount = "many"
}
print("There are \(naturalCount) \(countedThings).")
// 输出 "There are dozens of moons orbiting Saturn."
在上例中,approximateCount在一个switch声明中被评估。每一个case都与之进行比较。因为approximateCount落在了 12 到 100 的区间,所以naturalCount等于”dozens of”值,并且此后的执行跳出了switch语句。
3.2.3 元组
我们可以使用元组在同一个switch语句中测试多个值。元组中的元素可以是值,也可以是区间。另外,使用下划线(_)来匹配所有可能的值。
下面的例子展示了如何使用一个(Int, Int)类型的元组来分类下图中的点(x, y):
let somePoint = (1, 1)
switch somePoint {
case (0, 0):
print("\(somePoint) is at the origin")
case (_, 0):
print("\(somePoint) is on the x-axis")
case (0, _):
print("\(somePoint) is on the y-axis")
case (-2...2, -2...2):
print("\(somePoint) is inside the box")
default:
print("\(somePoint) is outside of the box")
}
// 输出 "(1, 1) is inside the box"
不像 C 语言,Swift 允许多个 case 匹配同一个值。实际上,在这个例子中,点(0, 0)可以匹配所有四个 case。但是,如果存在多个匹配,那么只会执行第一个被匹配到的 case 分支。考虑点(0, 0)会首先匹配case (0, 0),因此剩下的能够匹配的分支都会被忽视掉。
3.2.4 值绑定(Value Bindings)
case 分支允许将匹配的值声明为临时常量或变量,并且在case分支体内使用 —— 这种行为被称为值绑定(value binding),因为匹配的值在case分支体内,与临时的常量或变量绑定。
下面的例子将下图中的点(x, y),使用(Int, Int)类型的元组表示,然后分类表示:
let anotherPoint = (2, 0)
switch anotherPoint {
case (let x, 0):
print("on the x-axis with an x value of \(x)")
case (0, let y):
print("on the y-axis with a y value of \(y)")
case let (x, y):
print("somewhere else at (\(x), \(y))")
}
// 输出 "on the x-axis with an x value of 2"
这三个 case 都声明了常量x和y的占位符,用于临时获取元组anotherPoint的一个或两个值。第一个 case ——case (let x, 0)将匹配一个纵坐标为0的点,并把这个点的横坐标赋给临时的常量x。类似的,第二个 case ——case (0, let y)将匹配一个横坐标为0的点,并把这个点的纵坐标赋给临时的常量y。
一旦声明了这些临时的常量,它们就可以在其对应的 case 分支里使用。在这个例子中,它们用于打印给定点的类型。
请注意,这个switch语句不包含默认分支。这是因为最后一个 case ——case let(x, y)声明了一个可以匹配余下所有值的元组。这使得switch语句已经完备了,因此不需要再书写默认分支。
3.2.5 Where
case 分支的模式可以使用where语句来判断额外的条件。
下面的例子把下图中的点(x, y)进行了分类:
let yetAnotherPoint = (1, -1)
switch yetAnotherPoint {
case let (x, y) where x == y:
print("(\(x), \(y)) is on the line x == y")
case let (x, y) where x == -y:
print("(\(x), \(y)) is on the line x == -y")
case let (x, y):
print("(\(x), \(y)) is just some arbitrary point")
}
// 输出 "(1, -1) is on the line x == -y"
这三个 case 都声明了常量x和y的占位符,用于临时获取元组yetAnotherPoint的两个值。这两个常量被用作where语句的一部分,从而创建一个动态的过滤器(filter)。当且仅当where语句的条件为true时,匹配到的 case 分支才会被执行。
就像是值绑定中的例子,由于最后一个 case 分支匹配了余下所有可能的值,switch语句就已经完备了,因此不需要再书写默认分支。
3.2.6 复合匹配
当多个条件可以使用同一种方法来处理时,可以将这几种可能放在同一个case后面,并且用逗号隔开。当case后面的任意一种模式匹配的时候,这条分支就会被匹配。并且,如果匹配列表过长,还可以分行书写:
let someCharacter: Character = "e"
switch someCharacter {
case "a", "e", "i", "o", "u":
print("\(someCharacter) is a vowel")
case "b", "c", "d", "f", "g", "h", "j", "k", "l", "m",
"n", "p", "q", "r", "s", "t", "v", "w", "x", "y", "z":
print("\(someCharacter) is a consonant")
default:
print("\(someCharacter) is not a vowel or a consonant")
}
// 输出 "e is a vowel"
这个switch语句中的第一个case,匹配了英语中的五个小写元音字母。相似的,第二个case匹配了英语中所有的小写辅音字母。最终,default分支匹配了其它所有字符。 复合匹配同样可以包含值绑定。复合匹配里所有的匹配模式,都必须包含相同的值绑定。并且每一个绑定都必须获取到相同类型的值。这保证了,无论复合匹配中的哪个模式发生了匹配,分支体内的代码,都能获取到绑定的值,并且绑定的值都有一样的类型。
let stillAnotherPoint = (9, 0)
switch stillAnotherPoint {
case (let distance, 0), (0, let distance):
print("On an axis, \(distance) from the origin")
default:
print("Not on an axis")
}
// 输出 "On an axis, 9 from the origin"
上面的case有两个模式:(let distance, 0)匹配了在x轴上的值,(0, let distance)匹配了在y轴上的值。两个模式都绑定了distance,并且distance在两种模式下,都是整型——这意味着分支体内的代码,只要case匹配,都可以获取到distance值.
4 控制转移语句(Control Transfer Statements)
控制转移语句改变你代码的执行顺序,通过它可以实现代码的跳转。Swift 有五种控制转移语句:
- continue
- break
- fallthrough
- return
- throw
我们将会在下面讨论continue、break和fallthrough语句。return语句将会在函数章节讨论,throw语句会在错误抛出章节讨论。
4.1 Continue
continue语句告诉一个循环体立刻停止本次循环,重新开始下次循环。就好像在说“本次循环我已经执行完了”,但是并不会离开整个循环体。
下面的例子把一个小写字符串中的元音字母和空格字符移除,生成了一个含义模糊的短句:
let puzzleInput = "great minds think alike"
var puzzleOutput = ""
for character in puzzleInput {
switch character {
case "a", "e", "i", "o", "u", " ":
continue
default:
puzzleOutput.append(character)
}
}
print(puzzleOutput)
// 输出 "grtmndsthnklk"
在上面的代码中,只要匹配到元音字母或者空格字符,就调用continue语句,使本次循环结束,重新开始下次循环。这种行为使switch匹配到元音字母和空格字符时不做处理,而不是让每一个匹配到的字符都被打印。
4.2 Break
break语句会立刻结束整个控制流的执行。break 可以在 switch 或循环语句中使用,用来提前结束switch或循环语句。
循环语句中的 break
当在一个循环体中使用break时,会立刻中断该循环体的执行,然后跳转到表示循环体结束的大括号(})后的第一行代码。不会再有本次循环的代码被执行,也不会再有下次的循环产生。
Switch 语句中的 break
当在一个switch代码块中使用break时,会立即中断该switch代码块的执行,并且跳转到表示switch代码块结束的大括号(})后的第一行代码。
这种特性可以被用来匹配或者忽略一个或多个分支。因为 Swift 的switch需要包含所有的分支而且不允许有为空的分支,有时为了使你的意图更明显,需要特意匹配或者忽略某个分支。那么当你想忽略某个分支时,可以在该分支内写上break语句。当那个分支被匹配到时,分支内的break语句立即结束switch代码块。
注意: 当一个switch分支仅仅包含注释时,会被报编译时错误。注释不是代码语句而且也不能让switch分支达到被忽略的效果。你应该使用break来忽略某个分支。
下面的例子通过switch来判断一个Character值是否代表下面四种语言之一。为了简洁,多个值被包含在了同一个分支情况中。
let numberSymbol: Character = "三" // 简体中文里的数字 3
var possibleIntegerValue: Int?
switch numberSymbol {
case "1", "١", "一", "๑":
possibleIntegerValue = 1
case "2", "٢", "二", "๒":
possibleIntegerValue = 2
case "3", "٣", "三", "๓":
possibleIntegerValue = 3
case "4", "٤", "四", "๔":
possibleIntegerValue = 4
default:
break
}
if let integerValue = possibleIntegerValue {
print("The integer value of \(numberSymbol) is \(integerValue).")
} else {
print("An integer value could not be found for \(numberSymbol).")
}
// 输出 "The integer value of 三 is 3."
这个例子检查numberSymbol是否是拉丁,阿拉伯,中文或者泰语中的1到4之一。如果被匹配到,该switch分支语句给Int?类型变量possibleIntegerValue设置一个整数值。
当switch代码块执行完后,接下来的代码通过使用可选绑定来判断possibleIntegerValue是否曾经被设置过值。因为是可选类型的缘故,possibleIntegerValue有一个隐式的初始值nil,所以仅仅当possibleIntegerValue曾被switch代码块的前四个分支中的某个设置过一个值时,可选的绑定才会被判定为成功。
在上面的例子中,想要把Character所有的的可能性都枚举出来是不现实的,所以使用default分支来包含所有上面没有匹配到字符的情况。由于这个default分支不需要执行任何动作,所以它只写了一条break语句。一旦落入到default分支中后,break语句就完成了该分支的所有代码操作,代码继续向下,开始执行if let语句。
4.3 fallthrough(贯穿)
在 Swift 里,switch语句不会从上一个 case 分支跳转到下一个 case 分支中。相反,只要第一个匹配到的 case 分支完成了它需要执行的语句,整个switch代码块完成了它的执行。相比之下,C 语言要求你显式地插入break语句到每个 case 分支的末尾来阻止自动落入到下一个 case 分支中。Swift 的这种避免默认落入到下一个分支中的特性意味着它的switch 功能要比 C 语言的更加清晰和可预测,可以避免无意识地执行多个 case 分支从而引发的错误。
如果你确实需要 C 风格的贯穿的特性,你可以在每个需要该特性的 case 分支中使用fallthrough关键字。下面的例子使用fallthrough来创建一个数字的描述语句。
let integerToDescribe = 5
var description = "The number \(integerToDescribe) is"
switch integerToDescribe {
case 2, 3, 5, 7, 11, 13, 17, 19:
description += " a prime number, and also"
fallthrough
default:
description += " an integer."
}
print(description)
// 输出 "The number 5 is a prime number, and also an integer."
这个例子定义了一个String类型的变量description并且给它设置了一个初始值。函数使用switch逻辑来判断integerToDescribe变量的值。当integerToDescribe的值属于列表中的质数之一时,该函数在description后添加一段文字,来表明这个数字是一个质数。然后它使用fallthrough关键字来“贯穿”到default分支中。default分支在description的最后添加一段额外的文字,至此switch代码块执行完了。
如果integerToDescribe的值不属于列表中的任何质数,那么它不会匹配到第一个switch分支。而这里没有其他特别的分支情况,所以integerToDescribe匹配到default分支中。
当switch代码块执行完后,使用print(_:separator:terminator:)函数打印该数字的描述。在这个例子中,数字5被准确的识别为了一个质数。
注意: fallthrough关键字不会检查它下一个将会落入执行的 case 中的匹配条件。fallthrough简单地使代码继续连接到下一个 case 中的代码,这和 C 语言标准中的switch语句特性是一样的。
4.4 带标签的语句
在 Swift 中,你可以在循环体和条件语句中嵌套循环体和条件语句来创造复杂的控制流结构。并且,循环体和条件语句都可以使用break语句来提前结束整个代码块。因此,显式地指明break语句想要终止的是哪个循环体或者条件语句,会很有用。类似地,如果你有许多嵌套的循环体,显式指明continue语句想要影响哪一个循环体也会非常有用。
为了实现这个目的,你可以使用标签(statement label)来标记一个循环体或者条件语句,对于一个条件语句,你可以使用break加标签的方式,来结束这个被标记的语句。对于一个循环语句,你可以使用break或者continue加标签,来结束或者继续这条被标记语句的执行。
声明一个带标签的语句是通过在该语句的关键词的同一行前面放置一个标签,作为这个语句的前导关键字(introducor keyword),并且该标签后面跟随一个冒号。下面是一个针对while循环体的标签语法,同样的规则适用于所有的循环体和条件语句。
label name: while condition { statements }
gameLoop: while square != finalSquare {
diceRoll += 1
if diceRoll == 7 { diceRoll = 1 }
switch square + diceRoll {
case finalSquare:
// 骰子数刚好使玩家移动到最终的方格里,游戏结束。
break gameLoop
case let newSquare where newSquare > finalSquare:
// 骰子数将会使玩家的移动超出最后的方格,那么这种移动是不合法的,玩家需要重新掷骰子
continue gameLoop
default:
// 合法移动,做正常的处理
square += diceRoll
square += board[square]
}
}
print("Game over!")
5 提前退出
像if语句一样,guard的执行取决于一个表达式的布尔值。我们可以使用guard语句来要求条件必须为真时,以执行guard语句后的代码。不同于if语句,一个guard语句总是有一个else从句,如果条件不为真则执行else从句中的代码。
func greet(person: [String: String]) {
guard let name = person["name"] else {
return
}
print("Hello \(name)")
guard let location = person["location"] else {
print("I hope the weather is nice near you.")
return
}
print("I hope the weather is nice in \(location).")
}
greet(["name": "John"])
// 输出 "Hello John!"
// 输出 "I hope the weather is nice near you."
greet(["name": "Jane", "location": "Cupertino"])
// 输出 "Hello Jane!"
// 输出 "I hope the weather is nice in Cupertino."
如果guard语句的条件被满足,则继续执行guard语句大括号后的代码。将变量或者常量的可选绑定作为guard语句的条件,都可以保护guard语句后面的代码。
如果条件不被满足,在else分支上的代码就会被执行。这个分支必须转移控制以退出guard语句出现的代码段。它可以用控制转移语句如return,break,continue或者throw做这件事,或者调用一个不返回的方法或函数,例如fatalError()。
相比于可以实现同样功能的if语句,按需使用guard语句会提升我们代码的可读性。它可以使你的代码连贯的被执行而不需要将它包在else块中,它可以使你在紧邻条件判断的地方,处理违规的情况。
6 检测 API 可用性
Swift内置支持检查 API 可用性,这可以确保我们不会在当前部署机器上,不小心地使用了不可用的API。
编译器使用 SDK 中的可用信息来验证我们的代码中使用的所有 API 在项目指定的部署目标上是否可用。如果我们尝试使用一个不可用的 API,Swift 会在编译时报错。
我们在if或guard语句中使用可用性条件(availability condition)去有条件的执行一段代码,来在运行时判断调用的API是否可用。编译器使用从可用性条件语句中获取的信息去验证,在这个代码块中调用的 API 是否可用。
if #available(iOS 10, macOS 10.12, *) {
// 在 iOS 使用 iOS 10 的 API, 在 macOS 使用 macOS 10.12 的 API
} else {
// 使用先前版本的 iOS 和 macOS 的 API
}
以上可用性条件指定,if语句的代码块仅仅在 iOS 10 或 macOS 10.12 及更高版本才运行。最后一个参数,*,是必须的,用于指定在所有其它平台中,如果版本号高于你的设备指定的最低版本,if语句的代码块将会运行。
在它一般的形式中,可用性条件使用了一个平台名字和版本的列表。平台名字可以是iOS,macOS,watchOS和tvOS——请访问声明属性来获取完整列表。除了指定像 iOS 8 或 macOS 10.10 的大版本号,也可以指定像 iOS 8.3 以及 macOS 10.10.3 的小版本号。
if #available(platform name version, ..., *) {
APIs 可用,语句将执行
} else {
APIs 不可用,语句将不执行
}
函数
函数是一段完成特定任务的独立代码片段。你可以通过给函数命名来标识某个函数的功能,这个名字可以被用来在需要的时候”调用”这个函数来完成它的任务。
Swift 统一的函数语法非常的灵活,可以用来表示任何函数,包括从最简单的没有参数名字的 C 风格函数,到复杂的带局部和外部参数名的 Objective-C 风格函数。参数可以提供默认值,以简化函数调用。参数也可以既当做传入参数,也当做传出参数,也就是说,一旦函数执行结束,传入的参数值将被修改。
在 Swift 中,每个函数都有一个由函数的参数值类型和返回值类型组成的类型。你可以把函数类型当做任何其他普通变量类型一样处理,这样就可以更简单地把函数当做别的函数的参数,也可以从其他函数中返回函数。函数的定义可以写在其他函数定义中,这样可以在嵌套函数范围内实现功能封装。
1 函数定义与调用
当你定义一个函数时,你可以定义一个或多个有名字和类型的值,作为函数的输入,称为参数,也可以定义某种类型的值作为函数执行结束时的输出,称为返回类型。
每个函数有个函数名,用来描述函数执行的任务。要使用一个函数时,用函数名来“调用”这个函数,并传给它匹配的输入值(称作 实参 )。函数的实参必须与函数参数表里参数的顺序一致。
下面例子中的函数的名字是greet(person:),之所以叫这个名字,是因为这个函数用一个人的名字当做输入,并返回向这个人问候的语句。为了完成这个任务,你需要定义一个输入参数——一个叫做 person 的 String 值,和一个包含给这个人问候语的 String 类型的返回值:
func greet(person: String) -> String {
let greeting = "Hello, " + person + "!"
return greeting
}
所有的这些信息汇总起来成为函数的定义,并以 func 作为前缀。指定函数返回类型时,用返回箭头 ->(一个连字符后跟一个右尖括号)后跟返回类型的名称的方式来表示。
该定义描述了函数的功能,它期望接收什么作为参数和执行结束时它返回的结果是什么类型。这样的定义使得函数可以在别的地方以一种清晰的方式被调用:
print(greet(person: "Anna"))
// 打印 "Hello, Anna!"
print(greet(person: "Brian"))
// 打印 "Hello, Brian!"
调用 greet(person:) 函数时,在圆括号中传给它一个 String 类型的实参,例如 greet(person: “Anna”)。正如上面所示,因为这个函数返回一个 String 类型的值,所以greet 可以被包含在 print(_:separator:terminator:) 的调用中,用来输出这个函数的返回值。
注意 print(_:separator:terminator:) 函数的第一个参数并没有设置一个标签,而其他的参数因为已经有了默认值,因此是可选的。关于这些函数语法上的变化详见下方关于 函数参数标签和参数名 以及 默认参数值。
在 greet(person:) 的函数体中,先定义了一个新的名为 greeting 的 String 常量,同时,把对 personName 的问候消息赋值给了 greeting 。然后用 return 关键字把这个问候返回出去。一旦 return greeting 被调用,该函数结束它的执行并返回 greeting 的当前值。
你可以用不同的输入值多次调用 greet(person:)。上面的例子展示的是用”Anna”和”Brian”调用的结果,该函数分别返回了不同的结果。
为了简化这个函数的定义,可以将问候消息的创建和返回写成一句:
func greetAgain(person: String) -> String {
return "Hello again, " + person + "!"
}
print(greetAgain(person: "Anna"))
// 打印 "Hello again, Anna!"
2 函数参数与返回值
函数参数与返回值在 Swift 中非常的灵活。你可以定义任何类型的函数,包括从只带一个未名参数的简单函数到复杂的带有表达性参数名和不同参数选项的复杂函数。
2.1 无参数函数
函数可以没有参数。下面这个函数就是一个无参数函数,当被调用时,它返回固定的 String 消息:
func sayHelloWorld() -> String {
return "hello, world"
}
print(sayHelloWorld())
// 打印 "hello, world"
尽管这个函数没有参数,但是定义中在函数名后还是需要一对圆括号。当被调用时,也需要在函数名后写一对圆括号。
2.2 多参数函数
函数可以有多种输入参数,这些参数被包含在函数的括号之中,以逗号分隔。
下面这个函数用一个人名和是否已经打过招呼作为输入,并返回对这个人的适当问候语:
func greet(person: String, alreadyGreeted: Bool) -> String {
if alreadyGreeted {
return greetAgain(person: person)
} else {
return greet(person: person)
}
}
print(greet(person: "Tim", alreadyGreeted: true))
// 打印 "Hello again, Tim!"
你可以通过在括号内使用逗号分隔来传递一个String参数值和一个标识为alreadyGreeted的Bool值,来调用greet(person:alreadyGreeted:)函数。注意这个函数和上面greet(person:)是不同的。虽然它们都有着同样的名字greet,但是greet(person:alreadyGreeted:)函数需要两个参数,而greet(person:)只需要一个参数。
2.3 无返回值函数
函数可以没有返回值。下面是 greet(person:) 函数的另一个版本,这个函数直接打印一个String值,而不是返回它:
func greet(person: String) {
print("Hello, \(person)!")
}
greet(person: "Dave")
// 打印 "Hello, Dave!"
因为这个函数不需要返回值,所以这个函数的定义中没有返回箭头(->)和返回类型。
注意 严格上来说,虽然没有返回值被定义,greet(person:) 函数依然返回了值。没有定义返回类型的函数会返回一个特殊的Void值。它其实是一个空的元组(tuple),没有任何元素,可以写成()。
被调用时,一个函数的返回值可以被忽略:
func printAndCount(string: String) -> Int {
print(string)
return string.count
}
func printWithoutCounting(string: String) {
let _ = printAndCount(string: string)
}
printAndCount(string: "hello, world")
// 打印 "hello, world" 并且返回值 12
printWithoutCounting(string: "hello, world")
// 打印 "hello, world" 但是没有返回任何值
第一个函数 printAndCount(string:),输出一个字符串并返回 Int 类型的字符数。第二个函数 printWithoutCounting(string:)调用了第一个函数,但是忽略了它的返回值。当第二个函数被调用时,消息依然会由第一个函数输出,但是返回值不会被用到。
注意: 返回值可以被忽略,但定义了有返回值的函数必须返回一个值,如果在函数定义底部没有返回任何值,将导致编译时错误(compile-time error)。
2.4 多重返回值函数
你可以用元组(tuple)类型让多个值作为一个复合值从函数中返回。
下例中定义了一个名为 minMax(array:) 的函数,作用是在一个 Int 类型的数组中找出最小值与最大值。
func minMax(array: [Int]) -> (min: Int, max: Int) {
var currentMin = array[0]
var currentMax = array[0]
for value in array[1..<array.count] {
if value < currentMin {
currentMin = value
} else if value > currentMax {
currentMax = value
}
}
return (currentMin, currentMax)
}
minMax(array:) 函数返回一个包含两个 Int 值的元组,这些值被标记为 min 和 max ,以便查询函数的返回值时可以通过名字访问它们。
在 minMax(array:) 的函数体中,在开始的时候设置两个工作变量 currentMin 和 currentMax 的值为数组中的第一个数。然后函数会遍历数组中剩余的值并检查该值是否比 currentMin 和 currentMax 更小或更大。最后数组中的最小值与最大值作为一个包含两个 Int 值的元组返回。
因为元组的成员值已被命名,因此可以通过 . 语法来检索找到的最小值与最大值:
let bounds = minMax(array: [8, -6, 2, 109, 3, 71])
print("min is \(bounds.min) and max is \(bounds.max)")
// 打印 "min is -6 and max is 109"
需要注意的是,元组的成员不需要在元组从函数中返回时命名,因为它们的名字已经在函数返回类型中指定了。
2.5 可选元组返回类型
如果函数返回的元组类型有可能整个元组都“没有值”,你可以使用可选的( optional ) 元组返回类型反映整个元组可以是nil的事实。你可以通过在元组类型的右括号后放置一个问号来定义一个可选元组,例如 (Int, Int)? 或 (String, Int, Bool)?
注意 可选元组类型如 (Int, Int)? 与元组包含可选类型如 (Int?, Int?) 是不同的。可选的元组类型,整个元组是可选的,而不只是元组中的每个元素值。
前面的 minMax(array:) 函数返回了一个包含两个 Int 值的元组。但是函数不会对传入的数组执行任何安全检查,如果 array 参数是一个空数组,如上定义的 minMax(array:) 在试图访问 array[0] 时会触发一个运行时错误(runtime error)。
为了安全地处理这个“空数组”问题,将 minMax(array:) 函数改写为使用可选元组返回类型,并且当数组为空时返回 nil:
func minMax(array: [Int]) -> (min: Int, max: Int)? {
if array.isEmpty { return nil }
var currentMin = array[0]
var currentMax = array[0]
for value in array[1..<array.count] {
if value < currentMin {
currentMin = value
} else if value > currentMax {
currentMax = value
}
}
return (currentMin, currentMax)
}
你可以使用可选绑定来检查 minMax(array:) 函数返回的是一个存在的元组值还是 nil:
if let bounds = minMax(array: [8, -6, 2, 109, 3, 71]) {
print("min is \(bounds.min) and max is \(bounds.max)")
}
// 打印 "min is -6 and max is 109"
3 函数参数标签和参数名称
每个函数参数都有一个参数标签( argument label )以及一个参数名称( parameter name )。参数标签在调用函数的时候使用;调用的时候需要将函数的参数标签写在对应的参数前面。参数名称在函数的实现中使用。默认情况下,函数参数使用参数名称来作为它们的参数标签。
func someFunction(firstParameterName: Int, secondParameterName: Int) {
// 在函数体内,firstParameterName 和 secondParameterName 代表参数中的第一个和第二个参数值
}
someFunction(firstParameterName: 1, secondParameterName: 2)
所有的参数都必须有一个独一无二的名字。虽然多个参数拥有同样的参数标签是可能的,但是一个唯一的函数标签能够使你的代码更具可读性。
3.1 指定参数标签
你可以在参数名称前指定它的参数标签,中间以空格分隔:
func someFunction(argumentLabel parameterName: Int) {
// 在函数体内,parameterName 代表参数值
}
这个版本的 greet(person:) 函数,接收一个人的名字和他的家乡,并且返回一句问候:
func greet(person: String, from hometown: String) -> String {
return "Hello \(person)! Glad you could visit from \(hometown)."
}
print(greet(person: "Bill", from: "Cupertino"))
// 打印 "Hello Bill! Glad you could visit from Cupertino."
参数标签的使用能够让一个函数在调用时更有表达力,更类似自然语言,并且仍保持了函数内部的可读性以及清晰的意图。
3.2 忽略参数标签
如果你不希望为某个参数添加一个标签,可以使用一个下划线(_)来代替一个明确的参数标签。
func someFunction(_ firstParameterName: Int, secondParameterName: Int) {
// 在函数体内,firstParameterName 和 secondParameterName 代表参数中的第一个和第二个参数值
}
someFunction(1, secondParameterName: 2)
如果一个参数有一个标签,那么在调用的时候必须使用标签来标记这个参数。
3.3 默认参数值
你可以在函数体中通过给参数赋值来为任意一个参数定义默认值(Deafult Value)。当默认值被定义后,调用这个函数时可以忽略这个参数。
func someFunction(parameterWithoutDefault: Int, parameterWithDefault: Int = 12) {
// 如果你在调用时候不传第二个参数,parameterWithDefault 会值为 12 传入到函数体中。
}
someFunction(parameterWithoutDefault: 3, parameterWithDefault: 6) // parameterWithDefault = 6
someFunction(parameterWithoutDefault: 4) // parameterWithDefault = 12
将不带有默认值的参数放在函数参数列表的最前。一般来说,没有默认值的参数更加的重要,将不带默认值的参数放在最前保证在函数调用时,非默认参数的顺序是一致的,同时也使得相同的函数在不同情况下调用时显得更为清晰。
3.4 可变参数
一个可变参数(variadic parameter)可以接受零个或多个值。函数调用时,你可以用可变参数来指定函数参数可以被传入不确定数量的输入值。通过在变量类型名后面加入(…)的方式来定义可变参数。
可变参数的传入值在函数体中变为此类型的一个数组。例如,一个叫做 numbers 的 Double… 型可变参数,在函数体内可以当做一个叫 numbers 的 [Double] 型的数组常量。
下面的这个函数用来计算一组任意长度数字的 算术平均数(arithmetic mean):
func arithmeticMean(_ numbers: Double...) -> Double {
var total: Double = 0
for number in numbers {
total += number
}
return total / Double(numbers.count)
}
arithmeticMean(1, 2, 3, 4, 5)
// 返回 3.0, 是这 5 个数的平均数。
arithmeticMean(3, 8.25, 18.75)
// 返回 10.0, 是这 3 个数的平均数。
注意: 一个函数最多只能拥有一个可变参数。
3.5 输入输出参数
函数参数默认是常量。试图在函数体中更改参数值将会导致编译错误(compile-time error)。这意味着你不能错误地更改参数值。如果你想要一个函数可以修改参数的值,并且想要在这些修改在函数调用结束后仍然存在,那么就应该把这个参数定义为输入输出参数(In-Out Parameters)。
定义一个输入输出参数时,在参数定义前加 inout 关键字。一个输入输出参数有传入函数的值,这个值被函数修改,然后被传出函数,替换原来的值。想获取更多的关于输入输出参数的细节和相关的编译器优化,请查看输入输出参数一节。
你只能传递变量给输入输出参数。你不能传入常量或者字面量,因为这些量是不能被修改的。当传入的参数作为输入输出参数时,需要在参数名前加 & 符,表示这个值可以被函数修改。
注意 输入输出参数不能有默认值,而且可变参数不能用 inout 标记。
func swapTwoInts(_ a: inout Int, _ b: inout Int) {
let temporaryA = a
a = b
b = temporaryA
}
swapTwoInts(::) 函数简单地交换 a 与 b 的值。该函数先将 a 的值存到一个临时常量 temporaryA 中,然后将 b 的值赋给 a,最后将 temporaryA 赋值给 b。
你可以用两个 Int 型的变量来调用 swapTwoInts(::)。需要注意的是,someInt 和 anotherInt 在传入 swapTwoInts(::) 函数前,都加了 & 的前缀:
var someInt = 3
var anotherInt = 107
swapTwoInts(&someInt, &anotherInt)
print("someInt is now \(someInt), and anotherInt is now \(anotherInt)")
// 打印 "someInt is now 107, and anotherInt is now 3"
从上面这个例子中,我们可以看到 someInt 和 anotherInt 的原始值在 swapTwoInts(::) 函数中被修改,尽管它们的定义在函数体外。
注意: 输入输出参数和返回值是不一样的。上面的 swapTwoInts 函数并没有定义任何返回值,但仍然修改了 someInt 和 anotherInt 的值。输入输出参数是函数对函数体外产生影响的另一种方式。
4 函数类型
每个函数都有种特定的函数类型,函数的类型由函数的参数类型和返回类型组成。
例如:
func addTwoInts(_ a: Int, _ b: Int) -> Int {
return a + b
}
func multiplyTwoInts(_ a: Int, _ b: Int) -> Int {
return a * b
}
这个例子中定义了两个简单的数学函数:addTwoInts 和 multiplyTwoInts。这两个函数都接受两个 Int 值, 返回一个 Int 值。
这两个函数的类型是 (Int, Int) -> Int,可以解读为“这个函数类型有两个 Int 型的参数并返回一个 Int 型的值。”。
下面是另一个例子,一个没有参数,也没有返回值的函数:
func printHelloWorld() {
print("hello, world")
}
这个函数的类型是:() -> Void,或者叫“没有参数,并返回 Void 类型的函数”。
4.1 使用函数类型
在 Swift 中,使用函数类型就像使用其他类型一样。例如,你可以定义一个类型为函数的常量或变量,并将适当的函数赋值给它:
var mathFunction: (Int, Int) -> Int = addTwoInts
这段代码可以被解读为:
”定义一个叫做 mathFunction 的变量,类型是‘一个有两个 Int 型的参数并返回一个 Int 型的值的函数’,并让这个新变量指向 addTwoInts 函数”。
addTwoInts 和 mathFunction 有同样的类型,所以这个赋值过程在 Swift 类型检查(type-check)中是允许的。
现在,你可以用 mathFunction 来调用被赋值的函数了:
print("Result: \(mathFunction(2, 3))")
// Prints "Result: 5"
有相同匹配类型的不同函数可以被赋值给同一个变量,就像非函数类型的变量一样:
mathFunction = multiplyTwoInts
print("Result: \(mathFunction(2, 3))")
// Prints "Result: 6"
就像其他类型一样,当赋值一个函数给常量或变量时,你可以让 Swift 来推断其函数类型:
let anotherMathFunction = addTwoInts
// anotherMathFunction 被推断为 (Int, Int) -> Int 类型
4.2 函数类型作为参数类型
你可以用 (Int, Int) -> Int 这样的函数类型作为另一个函数的参数类型。这样你可以将函数的一部分实现留给函数的调用者来提供。
下面是另一个例子,正如上面的函数一样,同样是输出某种数学运算结果:
func printMathResult(_ mathFunction: (Int, Int) -> Int, _ a: Int, _ b: Int) {
print("Result: \(mathFunction(a, b))")
}
printMathResult(addTwoInts, 3, 5)
// 打印 "Result: 8"
这个例子定义了 printMathResult(::_:) 函数,它有三个参数:第一个参数叫 mathFunction,类型是 (Int, Int) -> Int,你可以传入任何这种类型的函数;第二个和第三个参数叫 a 和 b,它们的类型都是 Int,这两个值作为已给出的函数的输入值。
当 printMathResult(::_:) 被调用时,它被传入 addTwoInts 函数和整数 3 和 5。它用传入 3 和 5 调用 addTwoInts,并输出结果:8。
printMathResult(:::) 函数的作用就是输出另一个适当类型的数学函数的调用结果。它不关心传入函数是如何实现的,只关心传入的函数是不是一个正确的类型。这使得 printMathResult(:::) 能以一种类型安全(type-safe)的方式将一部分功能转给调用者实现。
4.3 函数类型作为返回类型
你可以用函数类型作为另一个函数的返回类型。你需要做的是在返回箭头(->)后写一个完整的函数类型。
下面的这个例子中定义了两个简单函数,分别是 stepForward(:) 和 stepBackward(:)。stepForward(:)函数返回一个比输入值大 1 的值。stepBackward(:) 函数返回一个比输入值小 1 的值。这两个函数的类型都是 (Int) -> Int:
func stepForward(_ input: Int) -> Int {
return input + 1
}
func stepBackward(_ input: Int) -> Int {
return input - 1
}
如下名为 chooseStepFunction(backward:) 的函数,它的返回类型是 (Int) -> Int 类型的函数。chooseStepFunction(backward:) 根据布尔值 backwards 来返回 stepForward(:) 函数或 stepBackward(:) 函数:
func chooseStepFunction(backward: Bool) -> (Int) -> Int {
return backward ? stepBackward : stepForward
}
你现在可以用 chooseStepFunction(backward:) 来获得两个函数其中的一个:
var currentValue = 3
let moveNearerToZero = chooseStepFunction(backward: currentValue > 0)
// moveNearerToZero 现在指向 stepBackward() 函数。
上面这个例子中计算出从 currentValue 逐渐接近到0是需要向正数走还是向负数走。currentValue 的初始值是 3,这意味着 currentValue > 0 为真(true),这将使得 chooseStepFunction(:) 返回 stepBackward(:) 函数。一个指向返回的函数的引用保存在了 moveNearerToZero 常量中。
现在,moveNearerToZero指向了正确的函数,它可以被用来数到零:
print("Counting to zero:")
// Counting to zero:
while currentValue != 0 {
print("\(currentValue)... ")
currentValue = moveNearerToZero(currentValue)
}
print("zero!")
// 3...
// 2...
// 1...
// zero!
5 嵌套函数
到目前为止本章中你所见到的所有函数都叫全局函数(global functions),它们定义在全局域中。你也可以把函数定义在别的函数体中,称作 嵌套函数(nested functions)。
默认情况下,嵌套函数是对外界不可见的,但是可以被它们的外围函数(enclosing function)调用。一个外围函数也可以返回它的某一个嵌套函数,使得这个函数可以在其他域中被使用。
你可以用返回嵌套函数的方式重写 chooseStepFunction(backward:) 函数:
func chooseStepFunction(backward: Bool) -> (Int) -> Int {
func stepForward(input: Int) -> Int { return input + 1 }
func stepBackward(input: Int) -> Int { return input - 1 }
return backward ? stepBackward : stepForward
}
var currentValue = -4
let moveNearerToZero = chooseStepFunction(backward: currentValue > 0)
// moveNearerToZero now refers to the nested stepForward() function
while currentValue != 0 {
print("\(currentValue)... ")
currentValue = moveNearerToZero(currentValue)
}
print("zero!")
// -4...
// -3...
// -2...
// -1...
// zero!
闭包
闭包是自包含的函数代码块,可以在代码中被传递和使用。Swift 中的闭包与 C 和 Objective-C 中的代码块(blocks)以及其他一些编程语言中的匿名函数比较相似。
闭包可以捕获和存储其所在上下文中任意常量和变量的引用。被称为包裹常量和变量。 Swift 会为你管理在捕获过程中涉及到的所有内存操作。
在函数章节中介绍的全局和嵌套函数实际上也是特殊的闭包,闭包采取如下三种形式之一:
- 全局函数是一个有名字但不会捕获任何值的闭包
- 嵌套函数是一个有名字并可以捕获其封闭函数域内值的闭包
- 闭包表达式是一个利用轻量级语法所写的可以捕获其上下文中变量或常量值的匿名闭包
Swift 的闭包表达式拥有简洁的风格,并鼓励在常见场景中进行语法优化,主要优化如下:
- 利用上下文推断参数和返回值类型
- 隐式返回单表达式闭包,即单表达式闭包可以省略 return 关键字
- 参数名称缩写
- 尾随闭包语法
1 闭包表达式
嵌套函数是一个在较复杂函数中方便进行命名和定义自包含代码模块的方式。当然,有时候编写小巧的没有完整定义和命名的类函数结构也是很有用处的,尤其是在你处理一些函数并需要将另外一些函数作为该函数的参数时。
闭包表达式是一种利用简洁语法构建内联闭包的方式。闭包表达式提供了一些语法优化,使得撰写闭包变得简单明了。下面闭包表达式的例子通过使用几次迭代展示了 sorted(by:) 方法定义和语法优化的方式。每一次迭代都用更简洁的方式描述了相同的功能。
1.1 sorted 方法
Swift 标准库提供了名为 sorted(by:) 的方法,它会根据你所提供的用于排序的闭包函数将已知类型数组中的值进行排序。一旦排序完成,sorted(by:) 方法会返回一个与原数组大小相同,包含同类型元素且元素已正确排序的新数组。原数组不会被 sorted(by:) 方法修改。
下面的闭包表达式示例使用 sorted(by:) 方法对一个 String 类型的数组进行字母逆序排序。以下是初始数组:
let names = ["Chris", "Alex", "Ewa", "Barry", "Daniella"]
sorted(by:) 方法接受一个闭包,该闭包函数需要传入与数组元素类型相同的两个值,并返回一个布尔类型值来表明当排序结束后传入的第一个参数排在第二个参数前面还是后面。如果第一个参数值出现在第二个参数值前面,排序闭包函数需要返回true,反之返回false。
该例子对一个 String 类型的数组进行排序,因此排序闭包函数类型需为 (String, String) -> Bool。
提供排序闭包函数的一种方式是撰写一个符合其类型要求的普通函数,并将其作为 sorted(by:) 方法的参数传入:
func backward(_ s1: String, _ s2: String) -> Bool {
return s1 > s2
}
var reversedNames = names.sorted(by: backward)
// reversedNames 为 ["Ewa", "Daniella", "Chris", "Barry", "Alex"]
如果第一个字符串(s1)大于第二个字符串(s2),backward(::) 函数会返回 true,表示在新的数组中 s1 应该出现在 s2 前。对于字符串中的字符来说,“大于”表示“按照字母顺序较晚出现”。这意味着字母 “B” 大于字母 “A” ,字符串 “Tom” 大于字符串 “Tim”。该闭包将进行字母逆序排序,”Barry” 将会排在 “Alex” 之前。
然而,以这种方式来编写一个实际上很简单的表达式(a > b),确实太过繁琐了。对于这个例子来说,利用闭包表达式语法可以更好地构造一个内联排序闭包。
1.2 闭包表达式语法
闭包表达式语法有如下的一般形式:
{ (parameters) -> returnType in
statements
}
闭包表达式参数 可以是 in-out 参数,但不能设定默认值。也可以使用具名的可变参数(译者注:但是如果可变参数不放在参数列表的最后一位的话,调用闭包的时时编译器将报错。可参考这里)。元组也可以作为参数和返回值。
下面的例子展示了之前 backward(::) 函数对应的闭包表达式版本的代码:
reversedNames = names.sorted(by: { (s1: String, s2: String) -> Bool in
return s1 > s2
})
需要注意的是内联闭包参数和返回值类型声明与 backward(::) 函数类型声明相同。在这两种方式中,都写成了 (s1: String, s2: String) -> Bool。然而在内联闭包表达式中,函数和返回值类型都写在大括号内,而不是大括号外。
闭包的函数体部分由关键字in引入。该关键字表示闭包的参数和返回值类型定义已经完成,闭包函数体即将开始。
由于这个闭包的函数体部分如此短,以至于可以将其改写成一行代码:
reversedNames = names.sorted(by: { (s1: String, s2: String) -> Bool in return s1 > s2 } )
该例中 sorted(by:) 方法的整体调用保持不变,一对圆括号仍然包裹住了方法的整个参数。然而,参数现在变成了内联闭包。
1.3 根据上下文推断类型
因为排序闭包函数是作为 sorted(by:) 方法的参数传入的,Swift 可以推断其参数和返回值的类型。sorted(by:) 方法被一个字符串数组调用,因此其参数必须是 (String, String) -> Bool 类型的函数。这意味着 (String, String) 和 Bool 类型并不需要作为闭包表达式定义的一部分。因为所有的类型都可以被正确推断,返回箭头(->)和围绕在参数周围的括号也可以被省略:
reversedNames = names.sorted(by: { s1, s2 in return s1 > s2 } )
实际上,通过内联闭包表达式构造的闭包作为参数传递给函数或方法时,总是能够推断出闭包的参数和返回值类型。这意味着闭包作为函数或者方法的参数时,你几乎不需要利用完整格式构造内联闭包。
尽管如此,你仍然可以明确写出有着完整格式的闭包。如果完整格式的闭包能够提高代码的可读性,则我们更鼓励采用完整格式的闭包。而在 sorted(by:) 方法这个例子里,显然闭包的目的就是排序。由于这个闭包是为了处理字符串数组的排序,因此读者能够推测出这个闭包是用于字符串处理的。
1.4 单表达式闭包隐式返回
单行表达式闭包可以通过省略 return 关键字来隐式返回单行表达式的结果,如上版本的例子可以改写为:
reversedNames = names.sorted(by: { s1, s2 in s1 > s2 } )
在这个例子中,sorted(by:) 方法的参数类型明确了闭包必须返回一个 Bool 类型值。因为闭包函数体只包含了一个单一表达式(s1 > s2),该表达式返回 Bool 类型值,因此这里没有歧义,return 关键字可以省略。
1.5 参数名称缩写
Swift 自动为内联闭包提供了参数名称缩写功能,你可以直接通过 $0,$1,$2 来顺序调用闭包的参数,以此类推。
如果你在闭包表达式中使用参数名称缩写,你可以在闭包定义中省略参数列表,并且对应参数名称缩写的类型会通过函数类型进行推断。in关键字也同样可以被省略,因为此时闭包表达式完全由闭包函数体构成:
reversedNames = names.sorted(by: { $0 > $1 } )
在这个例子中,$0和$1表示闭包中第一个和第二个 String 类型的参数。
1.6 运算符方法
实际上还有一种更简短的方式来编写上面例子中的闭包表达式。Swift 的 String 类型定义了关于大于号(>)的字符串实现,其作为一个函数接受两个 String 类型的参数并返回 Bool 类型的值。而这正好与 sorted(by:) 方法的参数需要的函数类型相符合。因此,你可以简单地传递一个大于号,Swift 可以自动推断出你想使用大于号的字符串函数实现:
reversedNames = names.sorted(by: >)
2 尾随闭包
如果你需要将一个很长的闭包表达式作为最后一个参数传递给函数,可以使用尾随闭包来增强函数的可读性。尾随闭包是一个书写在函数括号之后的闭包表达式,函数支持将其作为最后一个参数调用。在使用尾随闭包时,你不用写出它的参数标签:
func someFunctionThatTakesAClosure(closure: () -> Void) {
// 函数体部分
}
// 以下是不使用尾随闭包进行函数调用
someFunctionThatTakesAClosure(closure: {
// 闭包主体部分
})
// 以下是使用尾随闭包进行函数调用
someFunctionThatTakesAClosure() {
// 闭包主体部分
}
在闭包表达式语法一节中作为 sorted(by:) 方法参数的字符串排序闭包可以改写为:
reversedNames = names.sorted() { $0 > $1 }
如果闭包表达式是函数或方法的唯一参数,则当你使用尾随闭包时,你甚至可以把 () 省略掉:
reversedNames = names.sorted { $0 > $1 }
当闭包非常长以至于不能在一行中进行书写时,尾随闭包变得非常有用。举例来说,Swift 的 Array 类型有一个 map(_:) 方法,这个方法获取一个闭包表达式作为其唯一参数。该闭包函数会为数组中的每一个元素调用一次,并返回该元素所映射的值。具体的映射方式和返回值类型由闭包来指定。
当提供给数组的闭包应用于每个数组元素后,map(_:) 方法将返回一个新的数组,数组中包含了与原数组中的元素一一对应的映射后的值。
下例介绍了如何在 map(_:) 方法中使用尾随闭包将 Int 类型数组 [16, 58, 510] 转换为包含对应 String 类型的值的数组[“OneSix”, “FiveEight”, “FiveOneZero”]:
let digitNames = [
0: "Zero", 1: "One", 2: "Two", 3: "Three", 4: "Four",
5: "Five", 6: "Six", 7: "Seven", 8: "Eight", 9: "Nine"
]
let numbers = [16, 58, 510]
如上代码创建了一个整型数位和它们英文版本名字相映射的字典。同时还定义了一个准备转换为字符串数组的整型数组。
你现在可以通过传递一个尾随闭包给 numbers 数组的 map(_:) 方法来创建对应的字符串版本数组:
let strings = numbers.map {
(number) -> String in
var number = number
var output = ""
repeat {
output = digitNames[number % 10]! + output
number /= 10
} while number > 0
return output
}
// strings 常量被推断为字符串类型数组,即 [String]
// 其值为 ["OneSix", "FiveEight", "FiveOneZero"]
map(_:) 为数组中每一个元素调用了一次闭包表达式。你不需要指定闭包的输入参数 number 的类型,因为可以通过要映射的数组类型进行推断。
在该例中,局部变量 number 的值由闭包中的 number 参数获得,因此可以在闭包函数体内对其进行修改,(闭包或者函数的参数总是常量),闭包表达式指定了返回类型为 String,以表明存储映射值的新数组类型为 String。
闭包表达式在每次被调用的时候创建了一个叫做 output 的字符串并返回。其使用求余运算符(number % 10)计算最后一位数字并利用 digitNames 字典获取所映射的字符串。这个闭包能够用于创建任意正整数的字符串表示。
注意: 字典 digitNames 下标后跟着一个叹号(!),因为字典下标返回一个可选值(optional value),表明该键不存在时会查找失败。在上例中,由于可以确定 number % 10 总是 digitNames 字典的有效下标,因此叹号可以用于强制解包 (force-unwrap) 存储在下标的可选类型的返回值中的String类型的值。
从 digitNames 字典中获取的字符串被添加到 output 的前部,逆序建立了一个字符串版本的数字。(在表达式 number % 10 中,如果 number 为 16,则返回 6,58 返回 8,510 返回 0。)
number 变量之后除以 10。因为其是整数,在计算过程中未除尽部分被忽略。因此 16 变成了 1,58 变成了 5,510 变成了 51。
整个过程重复进行,直到 number /= 10 为 0,这时闭包会将字符串 output 返回,而 map(_:) 方法则会将字符串添加到映射数组中。
在上面的例子中,通过尾随闭包语法,优雅地在函数后封装了闭包的具体功能,而不再需要将整个闭包包裹在 map(_:) 方法的括号内。
3 值捕获
闭包可以在其被定义的上下文中捕获常量或变量。即使定义这些常量和变量的原作用域已经不存在,闭包仍然可以在闭包函数体内引用和修改这些值。
Swift 中,可以捕获值的闭包的最简单形式是嵌套函数,也就是定义在其他函数的函数体内的函数。嵌套函数可以捕获其外部函数所有的参数以及定义的常量和变量。
举个例子,这有一个叫做 makeIncrementer 的函数,其包含了一个叫做 incrementer 的嵌套函数。嵌套函数 incrementer() 从上下文中捕获了两个值,runningTotal 和 amount。捕获这些值之后,makeIncrementer 将 incrementer 作为闭包返回。每次调用 incrementer 时,其会以 amount 作为增量增加 runningTotal 的值。
func makeIncrementer(forIncrement amount: Int) -> () -> Int {
var runningTotal = 0
func incrementer() -> Int {
runningTotal += amount
return runningTotal
}
return incrementer
}
makeIncrementer 返回类型为 () -> Int。这意味着其返回的是一个函数,而非一个简单类型的值。该函数在每次调用时不接受参数,只返回一个 Int 类型的值。关于函数返回其他函数的内容,请查看函数类型作为返回类型。
makeIncrementer(forIncrement:) 函数定义了一个初始值为 0 的整型变量 runningTotal,用来存储当前总计数值。该值为 incrementer 的返回值。
makeIncrementer(forIncrement:) 有一个 Int 类型的参数,其外部参数名为 forIncrement,内部参数名为 amount,该参数表示每次 incrementer 被调用时 runningTotal 将要增加的量。makeIncrementer 函数还定义了一个嵌套函数 incrementer,用来执行实际的增加操作。该函数简单地使 runningTotal 增加 amount,并将其返回。
如果我们单独考虑嵌套函数 incrementer(),会发现它有些不同寻常:
func incrementer() -> Int {
runningTotal += amount
return runningTotal
}
incrementer() 函数并没有任何参数,但是在函数体内访问了 runningTotal 和 amount 变量。这是因为它从外围函数捕获了 runningTotal 和 amount 变量的引用。捕获引用保证了 runningTotal 和 amount 变量在调用完 makeIncrementer 后不会消失,并且保证了在下一次执行 incrementer 函数时,runningTotal 依旧存在。
注意 为了优化,如果一个值不会被闭包改变,或者在闭包创建后不会改变,Swift 可能会改为捕获并保存一份对值的拷贝。 Swift 也会负责被捕获变量的所有内存管理工作,包括释放不再需要的变量。
下面是一个使用 makeIncrementer 的例子:
let incrementByTen = makeIncrementer(forIncrement: 10)
该例子定义了一个叫做 incrementByTen 的常量,该常量指向一个每次调用会将其 runningTotal 变量增加 10 的 incrementer 函数。调用这个函数多次可以得到以下结果:
incrementByTen()
// 返回的值为10
incrementByTen()
// 返回的值为20
incrementByTen()
// 返回的值为30
如果你创建了另一个 incrementer,它会有属于自己的引用,指向一个全新、独立的 runningTotal 变量:
let incrementBySeven = makeIncrementer(forIncrement: 7)
incrementBySeven()
// 返回的值为7
再次调用原来的 incrementByTen 会继续增加它自己的 runningTotal 变量,该变量和 incrementBySeven 中捕获的变量没有任何联系:
incrementByTen()
// 返回的值为40
4 闭包是引用类型
上面的例子中,incrementBySeven 和 incrementByTen 都是常量,但是这些常量指向的闭包仍然可以增加其捕获的变量的值。这是因为函数和闭包都是引用类型。
无论你将函数或闭包赋值给一个常量还是变量,你实际上都是将常量或变量的值设置为对应函数或闭包的引用。上面的例子中,指向闭包的引用 incrementByTen 是一个常量,而并非闭包内容本身。
这也意味着如果你将闭包赋值给了两个不同的常量或变量,两个值都会指向同一个闭包:
let alsoIncrementByTen = incrementByTen
alsoIncrementByTen()
// 返回的值为50
5 逃逸闭包
当一个闭包作为参数传到一个函数中,但是这个闭包在函数返回之后才被执行,我们称该闭包从函数中逃逸。当你定义接受闭包作为参数的函数时,你可以在参数名之前标注 @escaping,用来指明这个闭包是允许“逃逸”出这个函数的。
一种能使闭包“逃逸”出函数的方法是,将这个闭包保存在一个函数外部定义的变量中。举个例子,很多启动异步操作的函数接受一个闭包参数作为 completion handler。这类函数会在异步操作开始之后立刻返回,但是闭包直到异步操作结束后才会被调用。在这种情况下,闭包需要“逃逸”出函数,因为闭包需要在函数返回之后被调用。例如:
var completionHandlers: [() -> Void] = []
func someFunctionWithEscapingClosure(completionHandler: @escaping () -> Void) {
completionHandlers.append(completionHandler)
}
someFunctionWithEscapingClosure(_:) 函数接受一个闭包作为参数,该闭包被添加到一个函数外定义的数组中。如果你不将这个参数标记为 @escaping,就会得到一个编译错误。
将一个闭包标记为 @escaping 意味着你必须在闭包中显式地引用 self。比如说,在下面的代码中,传递到 someFunctionWithEscapingClosure(_:) 中的闭包是一个逃逸闭包,这意味着它需要显式地引用 self。相对的,传递到 someFunctionWithNonescapingClosure(_:) 中的闭包是一个非逃逸闭包,这意味着它可以隐式引用 self。
func someFunctionWithNonescapingClosure(closure: () -> Void) {
closure()
}
class SomeClass {
var x = 10
func doSomething() {
someFunctionWithEscapingClosure { self.x = 100 }
someFunctionWithNonescapingClosure { x = 200 }
}
}
let instance = SomeClass()
instance.doSomething()
print(instance.x)
// 打印出 "200"
completionHandlers.first?()
print(instance.x)
// 打印出 "100"
6 自动闭包
自动闭包是一种自动创建的闭包,用于包装传递给函数作为参数的表达式。这种闭包不接受任何参数,当它被调用的时候,会返回被包装在其中的表达式的值。这种便利语法让你能够省略闭包的花括号,用一个普通的表达式来代替显式的闭包。
我们经常会调用采用自动闭包的函数,但是很少去实现这样的函数。举个例子来说,assert(condition:message:file:line:) 函数接受自动闭包作为它的 condition 参数和 message 参数;它的 condition 参数仅会在 debug 模式下被求值,它的 message 参数仅当 condition 参数为 false 时被计算求值。
自动闭包让你能够延迟求值,因为直到你调用这个闭包,代码段才会被执行。延迟求值对于那些有副作用(Side Effect)和高计算成本的代码来说是很有益处的,因为它使得你能控制代码的执行时机。下面的代码展示了闭包如何延时求值。
var customersInLine = ["Chris", "Alex", "Ewa", "Barry", "Daniella"]
print(customersInLine.count)
// 打印出 "5"
let customerProvider = { customersInLine.remove(at: 0) }
print(customersInLine.count)
// 打印出 "5"
print("Now serving \(customerProvider())!")
// Prints "Now serving Chris!"
print(customersInLine.count)
// 打印出 "4"
尽管在闭包的代码中,customersInLine 的第一个元素被移除了,不过在闭包被调用之前,这个元素是不会被移除的。如果这个闭包永远不被调用,那么在闭包里面的表达式将永远不会执行,那意味着列表中的元素永远不会被移除。请注意,customerProvider 的类型不是 String,而是 () -> String,一个没有参数且返回值为 String 的函数。
将闭包作为参数传递给函数时,你能获得同样的延时求值行为。
// customersInLine is ["Alex", "Ewa", "Barry", "Daniella"]
func serve(customer customerProvider: () -> String) {
print("Now serving \(customerProvider())!")
}
serve(customer: { customersInLine.remove(at: 0) } )
// 打印出 "Now serving Alex!"
上面的 serve(customer:) 函数接受一个返回顾客名字的显式的闭包。下面这个版本的 serve(customer:) 完成了相同的操作,不过它并没有接受一个显式的闭包,而是通过将参数标记为 @autoclosure 来接收一个自动闭包。现在你可以将该函数当作接受 String 类型参数(而非闭包)的函数来调用。customerProvider 参数将自动转化为一个闭包,因为该参数被标记了 @autoclosure 特性。
// customersInLine is ["Ewa", "Barry", "Daniella"]
func serve(customer customerProvider: @autoclosure () -> String) {
print("Now serving \(customerProvider())!")
}
serve(customer: customersInLine.remove(at: 0))
// 打印 "Now serving Ewa!"
注意 过度使用 autoclosures 会让你的代码变得难以理解。上下文和函数名应该能够清晰地表明求值是被延迟执行的。
如果你想让一个自动闭包可以“逃逸”,则应该同时使用 @autoclosure 和 @escaping 属性。@escaping 属性的讲解见上面的逃逸闭包。
// customersInLine i= ["Barry", "Daniella"]
var customerProviders: [() -> String] = []
func collectCustomerProviders(_ customerProvider: @autoclosure @escaping () -> String) {
customerProviders.append(customerProvider)
}
collectCustomerProviders(customersInLine.remove(at: 0))
collectCustomerProviders(customersInLine.remove(at: 0))
print("Collected \(customerProviders.count) closures.")
// 打印 "Collected 2 closures."
for customerProvider in customerProviders {
print("Now serving \(customerProvider())!")
}
// 打印 "Now serving Barry!"
// 打印 "Now serving Daniella!"
在上面的代码中,collectCustomerProviders(_:) 函数并没有调用传入的 customerProvider 闭包,而是将闭包追加到了 customerProviders 数组中。这个数组定义在函数作用域范围外,这意味着数组内的闭包能够在函数返回之后被调用。因此,customerProvider 参数必须允许“逃逸”出函数作用域。
枚举
重点:关联值 原始值
1 简介
枚举为一组相关值定义了一个通用类型,从而可以让你在代码中安全地操作这些值。
如果你熟悉 C ,那么你可能知道 C 中的枚举会给一组整数值分配相关的名称。Swift 中的枚举则更加灵活,并且不需给枚举中的每一个成员都提供值。如果一个值(所谓“原始”值)要被提供给每一个枚举成员,那么这个值可以是字符串、字符、任意的整数值,或者是浮点类型。
而且,枚举成员可以指定任意类型的值来与不同的成员值关联储存,这更像是其他语言中的 union 或variant 的效果。你可以定义一组相关成员的合集作为枚举的一部分,每一个成员都可以有不同类型的值的合集与其关联。
Swift 中的枚举是具有自己权限的一类类型。它们使用了许多一般只被类所支持的特性,例如计算属性用来提供关于枚举当前值的额外信息,并且实例方法用来提供与枚举表示的值相关的功能。枚举同样也能够定义初始化器来初始化成员值;而且能够遵循协议来提供标准功能。
2 语法
你可以用 enum 关键字来定义一个枚举,然后将其所有的定义内容放在一个大括号{}中:
enum SomeEnumeration {
}
这是一个指南针的四个主要方向的例子:
enum CompassPoint {
case north
case south
case eath
case west
}
在一个枚举中定义的值(比如: north, south, east和 west)就是枚举的成员值(或成员), case关键字则明确了要定义成员值。
不像 C 和 Objective-C 那样,Swift 的枚举成员在被创建时不会分配一个默认的整数值。
在上文的 CompassPoint例子中, north, south, east和 west并不代表 0, 1, 2和 3。
而相反,不同的枚举成员在它们自己的权限中都是完全合格的值,并且是一个在 CompassPoint中被显式定义的类型。
多个成员值可以出现在同一行中,要用逗号隔开:
enum Planet {
case mercury, venus, earth, mars, jupiter, saturn, uranus, neptune
}
每个枚举都定义了一个全新的类型。正如 Swift 中其它的类型那样,它们的名称(例如: CompassPoint和 Planet)需要首字母大写。给枚举类型起一个单数的而不是复数的名字,从而使得它们能够顾名思义:
var directionToHead = CompassPoint.west
directionToHead = .east
当与 CompassPoint中可用的某一值一同初始化时 directionToHead的类型会被推断出来。一旦 directionToHead以 CompassPoint类型被声明,你就可以用一个点语法把它设定成不同的 CompassPoint值:
directionToHead的类型是已知的,所以当设定它的值时你可以不用写类型。这样做可以使得你在操作确定类型的枚举时让代码非常易读。
3 使用 Switch 语句来匹配枚举值
你可以用 switch 语句来匹配每一个单独的枚举值:
directionToHead = .south
switch directionToHead {
case .north:
print("Lots of planets have a north")
case .south:
print("Watch out for penguins")
case .east:
print("Where the sun rises")
case .west:
print("Where the skies are blue")
}
当判断一个枚举成员时, switch语句必须是全覆盖的。如果 .west的 case被省略了,那么代码将不能编译,因为这时表明它并没有覆盖 CompassPoint的所有成员。要求覆盖所有枚举成员是因为这样可以保证枚举成员不会意外的被漏掉。
如果不能为所有枚举成员都提供一个 case,那你也可以提供一个 default情况来包含那些不能被明确写出的成员:
let somePlanet = Planet.earth
switch somePlanet {
case .earth:
print("Mostly harmless")
default:
print("Not a safe place for humans")
}
4 关联值
之前几节中的栗子展示了枚举成员是怎样在他们各自的权限中被定义(和被分类)的。你可以给 Planet.earth设定常量或变量,然后再使用这个值。总之,有时将其它类型的关联值与这些成员值一起存储是很有用的。这样你就可以将额外的自定义信息和成员值一起储存,并且允许你在代码中每次调用这个成员时都能使用它。
你可以定义 Swift 枚举来存储任意给定类型的关联值,如果需要的话不同枚举成员关联值的类型可以不同。枚举与其他语言中的 discriminated unions, tagged unions, 或者 variants 类似。
举个栗子,假设库存跟踪系统需要按两个不同类型的条形码跟踪产品,一些产品贴的是用数字 0~9 的 UPC-A 格式一维条形码。每一个条码数字都含有一个“数字系统”位,之后是五个“制造商代码”数字和五个“产品代码”数字。而最后则是一个“检测”位来验证代码已经被正确扫描:

其它的产品则贴着二维码,它可以使用任何 ISO 8859-1 字符并且编码最长有 2953 个字符的字符串:

这样可以让库存跟踪系统很方便的以一个由 4 个整数组成的元组来储存 UPC-A 条形码,然而二维码则可以被存储为一个任意长度的字符串中。
在 Swift 中,为不同类型产品条码定义枚举大概是这种姿势:
enum Barcode {
case upc(Int, Int, Int, Int)
case qrCode(String)
}
这可以读作:
“定义一个叫做 Barcode的枚举类型,它要么用 (Int, Int, Int, Int)类型的关联值获取 upc 值,要么用 String 类型的关联值获取一个 qrCode的值。”
这个定义并不提供任何实际的 Int或者 String的值——它只定义当 Barcode常量和变量与 Barcode. upc或 Barcode. qrCode相同时可以存储的关联值的类型。
然后,新的条码就可以用任意一个类型来创建了:
var productBarcode = Barcode.upc(8, 85909, 51226, 3)
这个栗子创建了一个叫做 productBarcode的新变量而且给它赋值了一个 Barcode.upc的值关联了值为 (8, 85909, 51226, 3)的元组值。
同样的产品可以被分配一个不同类型的条码:
productBarcode = .qrCode("ABCDEFGHIJKLMNOP")
这时,最初的 Barcode.upc和它的整数值将被新的 Barcode.qrCode和它的字符串值代替。 Barcode类型的常量和变量可以存储一个 .upc或一个 .qrCode(和它们的相关值一起存储)中的任意一个,但是它们只可以在给定的时间内存储它们它们其中之一。
和以往一样,不同的条码类型可以用 switch 语句来检查。这一次,总之,相关值可以被提取为 switch 语句的一部分。你提取的每一个相关值都可以作为常量(用 let前缀) 或者变量(用 var前缀)在 switch的 case中使用:
switch productBarcode {
case .upc(let numberSystem, let manufacturer, let product, let check):
print("UPC: \(numberSystem), \(manufacturer), \(product), \(check).")
case .qrCode(let productCode):
print("QR code: \(productCode).")
}
如果对于一个枚举成员的所有的相关值都被提取为常量,或如果都被提取为变量,为了简洁,你可以用一个单独的 var或 let在成员名称前标注:
switch productBarcode {
case let .upc(numberSystem, manufacturer, product, check):
print("UPC : \(numberSystem), \(manufacturer), \(product), \(check).")
case let .qrCode(productCode):
print("QR code: \(productCode).")
}
5 原始值
关联值中条形码的栗子展示了枚举成员是如何声明它们存储不同类型的相关值的。作为相关值的另一种选择,枚举成员可以用相同类型的默认值预先填充(称为原始值)。
这里有一个和已命名的枚举成员一起存储的原始 ASCII 码的例子:
enum ASCIIControlCharacter: Character {
case tab = "\t"
case lineFeed = "\n"
case carriageReturn = "\r"
}
这里,一个叫做 ASCIIControlCharacter的枚举原始值被定义为类型 Character,并且被放置在了更多的一些 ASCII 控制字符中, Character值的描述见字符串和字符。
原始值与关联值不同。原始值是当你第一次定义枚举的时候,它们用来预先填充的值,正如上面的三个 ASCII 码。特定枚举成员的原始值是始终相同的。关联值在你基于枚举成员的其中之一创建新的常量或变量时设定,并且在你每次这么做的时候这些关联值可以是不同的。
6 隐式指定的原始值
当你在操作存储整数或字符串原始值枚举的时候,你不必显式地给每一个成员都分配一个原始值。当你没有分配时,Swift 将会自动为你分配值。
实际上,当整数值被用于作为原始值时,每成员的隐式值都比前一个大一。如果第一个成员没有值,那么它的值是 0 。
下面的枚举是先前的 Planet枚举的简化,用整数原始值来代表从太阳到每一个行星的顺序:
enum Planet: Int {
case mercury = 1, venus, earth, mars, jupiter, saturn, uranus, neptune
}
在上面的例子中, Planet.mercury有一个明确的原始值 1 , Planet.venus的隐式原始值是 2,以此类推。
当字符串被用于原始值,那么每一个成员的隐式原始值则是那个成员的名称。
下面的枚举是先前 CompassPoint枚举的简化,有字符串的原始值来代表每一个方位的名字:
enum CompassPoint: String {
case north, south, east, west
}
在上面的例子中, CompassPoint.south有一个隐式原始值 “south” ,以此类推。
你可以用 rawValue属性来访问一个枚举成员的原始值:
let earthsOrder = Planet.Earth.rawValue
// earthsOrder is 3
let sunsetDirection = CompassPoint.west.rawValue
// sunsetDirection is "west"
7 从原始值初始化
如果你用原始值类型来定义一个枚举,那么枚举就会自动收到一个可以接受原始值类型的值的初始化器(叫做 rawValue的形式参数)然后返回一个枚举成员或者 nil 。你可以使用这个初始化器来尝试创建一个枚举的新实例。
这个例子从它的原始值 7来辨认出 Uranus :
let possiblePlanet = Planet(rawValue: 7)
总之,不是所有可能的 Int值都会对应一个行星。因此原始值的初始化器总是返回可选的枚举成员。在上面的例子中, possiblePlanet的类型是 Planet? ,或者“可选项 Planet”
8 递归枚举
枚举在对序号考虑固定数量可能性的数据建模时表现良好,比如用来做简单整数运算的运算符。这些运算符允许你组合简单的整数数学运算表达式比如5到更复杂的比如5+4.
数学表达式的一大特征就是它们可以内嵌。比如说表达式(5 + 4) * 2 在乘法右手侧有一个数但其他表达式在乘法的左手侧。因为数据被内嵌了,用来储存数据的枚举同样需要支持内嵌——这意味着枚举需要被递归。
递归枚举是拥有另一个枚举作为枚举成员关联值的枚举。当编译器操作递归枚举时必须插入间接寻址层。你可以在声明枚举成员之前使用indirect关键字来明确它是递归的。
举例来讲,这里有一个储存简单数学运算表达式的枚举:
enum ArithmeticExpression {
case number(Int)
indirect case addition(ArithmeticExpression, ArithmeticExpression)
indirect case multiplication(ArithmeticExpression, ArithmeticExpression)
}
你同样可以在枚举之前写 indirect 来让整个枚举成员在需要时可以递归:
indirect enum ArithmeticExpression {
case number(Int)
case addition(ArithmeticExpression, ArithmeticExpression)
case multiplication(ArithmeticExpression, ArithmeticExpression)
}
这个枚举可以储存三种数学运算表达式:单一的数字,两个表达式的加法,以及两个表达式的乘法。 addition 和 multiplication 成员拥有同样是数学表达式的关联值——这些关联值让嵌套表达式成为可能。比如说,表达式 (5 + 4) * 2 乘号右侧有一个数字左侧有其他表达式。由于数据是内嵌的,用来储存数据的枚举同样需要支持内嵌——这就是说枚举需要递归。下边的代码展示了为 (5 + 4) * 2 创建的递归枚举 ArithmeticExpression :
let five = ArithmeticExpression.number(5)
let four = ArithmeticExpression.number(4)
let sum = ArithmeticExpression.addition(five, four)
let product = ArithmeticExpression.multiplication(sum, ArithmeticExpression.number(2))
递归函数是一种操作递归结构数据的简单方法。比如说,这里有一个判断数学表达式的函数:
func evaluate(_ expression: ArithmeticExpression) -> Int {
switch expression {
case let .number(value):
return value
case let .addition(left, right):
return evaluate(left) + evaluate(right)
case let .multiplication(left, right):
return evaluate(left) * evaluate(right)
}
}
print(evaluate(product))
// Prints "18"
这个函数通过直接返回关联值来判断普通数字。它通过衡量表达式左手侧和右手侧判断是加法还是乘法,然后对它们加或者乘。
源码:
indirect enum ArithmeticExpression {
case number(Int)
case addNumber(ArithmeticExpression, ArithmeticExpression)
case mutiNumber(ArithmeticExpression, ArithmeticExpression)
static func evalute(value: ArithmeticExpression) -> Int {
switch value {
case let .number(num):
return num
case let .addNumber(left, right):
return evalute(value: left) + evalute(value: right)
case let .mutiNumber(left, right):
return evalute(value: left) * evalute(value: right)
}
}
}
let four = ArithmeticExpression.number(4)
let five = ArithmeticExpression.number(5)
let addNum = ArithmeticExpression.addNumber(four, five)
let mutiNum = ArithmeticExpression.mutiNumber(addNum, ArithmeticExpression.number(2))
ArithmeticExpression.evalute(value: mutiNum)
9 位移枚举
OC枚举:
- 普通枚举
typedef NS_ENUM(NSInteger, UIViewAnimationTransition) {
UIViewAnimationTransitionNone,
UIViewAnimationTransitionFlipFromLeft,
UIViewAnimationTransitionFlipFromRight,
UIViewAnimationTransitionCurlUp,
UIViewAnimationTransitionCurlDown,
};
- 位移枚举
typedef NS_OPTIONS(NSUInteger, UIViewAutoresizing) {
UIViewAutoresizingNone = 0,
UIViewAutoresizingFlexibleLeftMargin = 1 << 0,
UIViewAutoresizingFlexibleWidth = 1 << 1,
UIViewAutoresizingFlexibleRightMargin= 1 << 2,
UIViewAutoresizingFlexibleTopMargin= 1 << 3,
UIViewAutoresizingFlexibleHeight= 1 << 4,
UIViewAutoresizingFlexibleBottomMargin = 1 << 5
};
Swift枚举:
对于位掩码,Swift 给出的方案是:选项集合(option sets)。在 C 和 Objective-C 中,通常的做法是将一个布尔值选项集合表示为一系列值为 2 的整数次幂的枚举成员。
Swift 使用结构体(struct)来遵从 OptionSet 协议,以引入选项集合,而非枚举(enum)。为什么这样处理呢?当枚举成员互斥的时候,比如说,一次只有一个选项可以被选择的情况下,枚举是非常好的。但是和 C 不同,在 Swift 中,你无法把多个枚举成员组合成一个值,而 C 中的枚举对编译器来说就是整型,可以接受任意整数值。
和 C 中一样,Swift 中的选项集合结构体使用了高效的位域来表示,但是这个结构体本身表现为一个集合,它的成员则为被选择的选项。这允许你使用标准的集合运算#Basic_operations)来维护位域,比如使用 contains 来检验集合中是否有某个成员,或者是用 union 来组合两个位域。另外,由于 OptionSet 继承于 ExpressibleByArrayLiteral,你可以使用数组字面量来生成一个选项集合。
如何创建你自己的选项集合类型呢?仅有的要求是,一个类型为整型的原始值(rawValue)和一个初始化构造器。对于结构体来说,Swift 通常都会自动提供一个逐一成员构造器(memberwise initializer),所以你并不需要自己写一个。rawValue 是位域底层的存储单元。每个选项都应该是静态的常量,并使用适当的值初始化了其位域。
struct EWSLearningRemindDateOption: OptionSet {
let rawValue: Int
static let None = EWSLearningRemindDateOption(rawValue: 0)
static let Sunday = EWSLearningRemindDateOption(rawValue: 1 << 0)
static let Monday = EWSLearningRemindDateOption(rawValue: 1 << 1)
static let Tuesday = EWSLearningRemindDateOption(rawValue: 1 << 2)
static let Wednesday = EWSLearningRemindDateOption(rawValue: 1 << 3)
static let Thursday = EWSLearningRemindDateOption(rawValue: 1 << 4)
static let Friday = EWSLearningRemindDateOption(rawValue: 1 << 5)
static let Saturday = EWSLearningRemindDateOption(rawValue: 1 << 6)
}
选项集合并不是集合类型
遵从 OptionSet 并不意味着遵从 Sequence 和 Collection 协议,所以你无法使用 count 来确定集合中有几个元素,也无法使用 for 循环来遍历选择的选项。从根本上说,一个选项集合仅仅是简单的整数值。
类和结构体
类和结构体是人们构建代码所用的一种通用且灵活的构造体。我们可以使用完全相同的语法规则来为类和结构体定义属性(常量、变量)和添加方法,从而扩展类和结构体的功能。
与其他编程语言所不同的是,Swift 并不要求你为自定义类和结构去创建独立的接口和实现文件。你所要做的是在一个单一文件中定义一个类或者结构体,系统将会自动生成面向其它代码的外部接口。
注意 通常一个类的实例被称为对象。然而在 Swift 中,类和结构体的关系要比在其他语言中更加的密切,本章中所讨论的大部分功能都可以用在类和结构体上。因此,我们会主要使用实例。
1 类和结构体对比
Swift 中类和结构体有很多共同点。共同处在于:
- 定义属性用于存储值
- 定义方法用于提供功能
- 定义下标操作使得可以通过下标语法来访问实例所包含的值
- 定义构造器用于生成初始化值
- 通过扩展以增加默认实现的功能
- 实现协议以提供某种标准功能
与结构体相比,类还有如下的附加功能:
- 继承允许一个类继承另一个类的特征
- 类型转换允许在运行时检查和解释一个类实例的类型
- 析构器允许一个类实例释放任何其所被分配的资源
- 引用计数允许对一个类的多次引用
注意 结构体总是通过被复制的方式在代码中传递,不使用引用计数。
1.1 定义语法
类和结构体有着类似的定义方式。我们通过关键字class和struct来分别表示类和结构体,并在一对大括号中定义它们的具体内容:
class SomeClass {
// 在这里定义类
}
struct SomeStructure {
// 在这里定义结构体
}
注意 在你每次定义一个新类或者结构体的时候,实际上你是定义了一个新的 Swift 类型。因此请使用UpperCamelCase这种方式来命名(如SomeClass和SomeStructure等),以便符合标准 Swift 类型的大写命名风格(如String,Int和Bool)。相反的,请使用lowerCamelCase这种方式为属性和方法命名(如framerate和incrementCount),以便和类型名区分。
以下是定义结构体和定义类的示例:
struct Resolution {
var width = 0
var height = 0
}
class VideoMode {
var resolution = Resolution()
var interlaced = false
var frameRate = 0.0
var name: String?
}
在上面的示例中我们定义了一个名为Resolution的结构体,用来描述一个显示器的像素分辨率。这个结构体包含了两个名为width和height的存储属性。存储属性是被捆绑和存储在类或结构体中的常量或变量。当这两个属性被初始化为整数0的时候,它们会被推断为Int类型。
在上面的示例中我们还定义了一个名为VideoMode的类,用来描述一个视频显示器的特定模式。这个类包含了四个变量存储属性。第一个是分辨率,它被初始化为一个新的Resolution结构体的实例,属性类型被推断为Resolution。新VideoMode实例同时还会初始化其它三个属性,它们分别是,初始值为false的interlaced,初始值为0.0的frameRate,以及值为可选String的name。name属性会被自动赋予一个默认值nil,意为“没有name值”,因为它是一个可选类型。
1.2 类和结构体实例
Resolution结构体和VideoMode类的定义仅描述了什么是Resolution和VideoMode。它们并没有描述一个特定的分辨率(resolution)或者视频模式(video mode)。为了描述一个特定的分辨率或者视频模式,我们需要生成一个它们的实例。
生成结构体和类实例的语法非常相似:
let someResolution = Resolution()
let someVideoMode = VideoMode()
结构体和类都使用构造器语法来生成新的实例。构造器语法的最简单形式是在结构体或者类的类型名称后跟随一对空括号,如Resolution()或VideoMode()。通过这种方式所创建的类或者结构体实例,其属性均会被初始化为默认值。构造过程章节会对类和结构体的初始化进行更详细的讨论。
1.3 属性访问
通过使用点语法,你可以访问实例的属性。其语法规则是,实例名后面紧跟属性名,两者通过点号(.)连接:
print("The width of someResolution is \(someResolution.width)")
// 打印 "The width of someResolution is 0"
在上面的例子中,someResolution.width引用someResolution的width属性,返回width的初始值0。
你也可以访问子属性,如VideoMode中Resolution属性的width属性:
print("The width of someVideoMode is \(someVideoMode.resolution.width)")
// 打印 "The width of someVideoMode is 0"
你也可以使用点语法为变量属性赋值:
someVideoMode.resolution.width = 1280
print("The width of someVideoMode is now \(someVideoMode.resolution.width)")
// 打印 "The width of someVideoMode is now 1280"
注意 与 Objective-C 语言不同的是,Swift 允许直接设置结构体属性的子属性。上面的最后一个例子,就是直接设置了someVideoMode中resolution属性的width这个子属性,以上操作并不需要重新为整个resolution属性设置新值。
1.4 结构体类型的成员逐一构造器
所有结构体都有一个自动生成的成员逐一构造器,用于初始化新结构体实例中成员的属性。新实例中各个属性的初始值可以通过属性的名称传递到成员逐一构造器之中:
let vga = Resolution(width: 640, height: 480)
与结构体不同,类实例没有默认的成员逐一构造器。构造过程章节会对构造器进行更详细的讨论。
2 结构体和枚举是值类型
值类型被赋予给一个变量、常量或者被传递给一个函数的时候,其值会被拷贝。
在之前的章节中,我们已经大量使用了值类型。实际上,在 Swift 中,所有的基本类型:整数(Integer)、浮点数(floating-point)、布尔值(Boolean)、字符串(string)、数组(array)和字典(dictionary),都是值类型,并且在底层都是以结构体的形式所实现。
在 Swift 中,所有的结构体和枚举类型都是值类型。这意味着它们的实例,以及实例中所包含的任何值类型属性,在代码中传递的时候都会被复制。
请看下面这个示例,其使用了前一个示例中的Resolution结构体:
let hd = Resolution(width: 1920, height: 1080)
var cinema = hd
在以上示例中,声明了一个名为hd的常量,其值为一个初始化为全高清视频分辨率(1920 像素宽,1080 像素高)的Resolution实例。
然后示例中又声明了一个名为cinema的变量,并将hd赋值给它。因为Resolution是一个结构体,所以cinema的值其实是hd的一个拷贝副本,而不是hd本身。尽管hd和cinema有着相同的宽(width)和高(height),但是在幕后它们是两个完全不同的实例。
下面,为了符合数码影院放映的需求(2048 像素宽,1080 像素高),cinema的width属性需要作如下修改:
cinema.width = 2048
这里,将会显示cinema的width属性确已改为了2048:
print("cinema is now \(cinema.width) pixels wide")
// 打印 "cinema is now 2048 pixels wide"
然而,初始的hd实例中width属性还是1920:
print("hd is still \(hd.width) pixels wide")
// 打印 "hd is still 1920 pixels wide"
在将hd赋予给cinema的时候,实际上是将hd中所存储的值进行拷贝,然后将拷贝的数据存储到新的cinema实例中。结果就是两个完全独立的实例碰巧包含有相同的数值。由于两者相互独立,因此将cinema的width修改为2048并不会影响hd中的width的值。
枚举也遵循相同的行为准则:
enum CompassPoint {
case North, South, East, West
}
var currentDirection = CompassPoint.West
let rememberedDirection = currentDirection
currentDirection = .East
if rememberedDirection == .West {
print("The remembered direction is still .West")
}
// 打印 "The remembered direction is still .West"
上例中rememberedDirection被赋予了currentDirection的值,实际上它被赋予的是值的一个拷贝。赋值过程结束后再修改currentDirection的值并不影响rememberedDirection所储存的原始值的拷贝。
3 类是引用类型
与值类型不同,引用类型在被赋予到一个变量、常量或者被传递到一个函数时,其值不会被拷贝。因此,引用的是已存在的实例本身而不是其拷贝。
请看下面这个示例,其使用了之前定义的VideoMode类:
let tenEighty = VideoMode()
tenEighty.resolution = hd
tenEighty.interlaced = true
tenEighty.name = "1080i"
tenEighty.frameRate = 25.0
以上示例中,声明了一个名为tenEighty的常量,其引用了一个VideoMode类的新实例。在之前的示例中,这个视频模式(video mode)被赋予了HD分辨率(1920*1080)的一个拷贝(即hd实例)。同时设置为interlaced,命名为“1080i”。最后,其帧率是25.0帧每秒。
然后,tenEighty被赋予名为alsoTenEighty的新常量,同时对alsoTenEighty的帧率进行修改:
let alsoTenEighty = tenEighty
alsoTenEighty.frameRate = 30.0
因为类是引用类型,所以tenEight和alsoTenEight实际上引用的是相同的VideoMode实例。换句话说,它们是同一个实例的两种叫法。
下面,通过查看tenEighty的frameRate属性,我们会发现它正确的显示了所引用的VideoMode实例的新帧率,其值为30.0:
print("The frameRate property of tenEighty is now \(tenEighty.frameRate)")
// 打印 "The frameRate property of theEighty is now 30.0"
需要注意的是tenEighty和alsoTenEighty被声明为常量而不是变量。然而你依然可以改变tenEighty.frameRate和alsoTenEighty.frameRate,因为tenEighty和alsoTenEighty这两个常量的值并未改变。它们并不“存储”这个VideoMode实例,而仅仅是对VideoMode实例的引用。所以,改变的是被引用的VideoMode的frameRate属性,而不是引用VideoMode的常量的值。
3.1 恒等运算符
因为类是引用类型,有可能有多个常量和变量在幕后同时引用同一个类实例。(对于结构体和枚举来说,这并不成立。因为它们作为值类型,在被赋予到常量、变量或者传递到函数时,其值总是会被拷贝。)
如果能够判定两个常量或者变量是否引用同一个类实例将会很有帮助。为了达到这个目的,Swift 内建了两个恒等运算符:
- 等价于(===)
- 不等价于(!==)
运用这两个运算符检测两个常量或者变量是否引用同一个实例:
if tenEighty === alsoTenEighty {
print("tenEighty and alsoTenEighty refer to the same Resolution instance.")
}
//打印 "tenEighty and alsoTenEighty refer to the same Resolution instance."
请注意,“等价于”(用三个等号表示,===)与“等于”(用两个等号表示,==)的不同:
- “等价于”表示两个类类型(class type)的常量或者变量引用同一个类实例。
- “等于”表示两个实例的值“相等”或“相同”,判定时要遵照设计者定义的评判标准,因此相对于“相等”来说,这是一种更加合适的叫法。
当你在定义你的自定义类和结构体的时候,你有义务来决定判定两个实例“相等”的标准。在章节等价操作符中将会详细介绍实现自定义“等于”和“不等于”运算符的流程。
3.2 指针
如果你有 C,C++ 或者 Objective-C 语言的经验,那么你也许会知道这些语言使用指针来引用内存中的地址。一个引用某个引用类型实例的 Swift 常量或者变量,与 C 语言中的指针类似,但是并不直接指向某个内存地址,也不要求你使用星号(*)来表明你在创建一个引用。Swift 中的这些引用与其它的常量或变量的定义方式相同。
4 类和结构体的选择
在你的代码中,你可以使用类和结构体来定义你的自定义数据类型。
然而,结构体实例总是通过值传递,类实例总是通过引用传递。这意味两者适用不同的任务。当你在考虑一个工程项目的数据结构和功能的时候,你需要决定每个数据结构是定义成类还是结构体。
按照通用的准则,当符合一条或多条以下条件时,请考虑构建结构体:
- 该数据结构的主要目的是用来封装少量相关简单数据值。
- 有理由预计该数据结构的实例在被赋值或传递时,封装的数据将会被拷贝而不是被引用。
- 该数据结构中储存的值类型属性,也应该被拷贝,而不是被引用。
- 该数据结构不需要去继承另一个既有类型的属性或者行为。
举例来说,以下情境中适合使用结构体:
- 几何形状的大小,封装一个width属性和height属性,两者均为Double类型。
- 一定范围内的路径,封装一个start属性和length属性,两者均为Int类型。
- 三维坐标系内一点,封装x,y和z属性,三者均为Double类型。
在所有其它案例中,定义一个类,生成一个它的实例,并通过引用来管理和传递。实际中,这意味着绝大部分的自定义数据构造都应该是类,而非结构体。
5 字符串、数组、和字典类型的赋值与复制行为
Swift 中,许多基本类型,诸如String,Array和Dictionary类型均以结构体的形式实现。这意味着被赋值给新的常量或变量,或者被传入函数或方法中时,它们的值会被拷贝。
Objective-C 中NSString,NSArray和NSDictionary类型均以类的形式实现,而并非结构体。它们在被赋值或者被传入函数或方法时,不会发生值拷贝,而是传递现有实例的引用。
注意 以上是对字符串、数组、字典的“拷贝”行为的描述。在你的代码中,拷贝行为看起来似乎总会发生。然而,Swift 在幕后只在绝对必要时才执行实际的拷贝。Swift 管理所有的值拷贝以确保性能最优化,所以你没必要去回避赋值来保证性能最优化。
属性
属性可以将值与特定的类、结构体或者是枚举联系起来。存储属性会存储常量或变量作为实例的一部分,反之计算属性会计算(而不是存储)值。计算属性可以由类、结构体和枚举定义。存储属性只能由类和结构体定义。
存储属性和计算属性通常和特定类型的实例相关联(实例属性)。属性也可以与类型本身相关联,这种属性就是所谓的类型属性。
另外,你也可以定义属性观察器来检查属性中值的变化,这样你就可以用自定义的行为来响应。属性观察器可以被添加到你自己定义的存储属性中,也可以添加到子类从他的父类那里所继承来的属性中。
1 存储属性
在其最简单的形式下,存储属性是一个作为特定类和结构体实例一部分的常量或变量。存储属性要么是变量存储属性(由 var 关键字引入)要么是常量存储属性(由 let 关键字引入)。
正如默认属性值中所述,你可以为存储属性提供一个默认值作为它定义的一部分。你也可以在初始化的过程中设置和修改存储属性的初始值。正如在构造过程中常量属性的赋值所述,这一点对于常量存储属性也成立。
下面的例子定义了一个名为 FixedLengthRange 的结构体,它描述了一个一旦被创建长度就不能改变的整型值域:
struct FixedLengthRange {
var firstValue: Int
let length: Int
}
var rangeOfThreeItems = FixedLengthRange(firstValue: 0, length: 3)
// the range represents integer values 0, 1, and 2
rangeOfThreeItems.firstValue = 6
// the range now represents integer values 6, 7, and 8
FixedLengthRange 的实例有一个名为 firstValue 的变量存储属性和一个名为 length 的常量存储属性。在上面的例子中,当新的值域创建时 length 已经被创建并且不能再修改,因为这是一个常量属性。
1.1 常量结构体实例的存储属性
如果你创建了一个结构体的实例并且把这个实例赋给常量,你不能修改这个实例的属性,即使是声明为变量的属性:
let rangeOfFourItems = FixedLengthRange(firstValue: 0, length: 4)
// this range represents integer values 0, 1, 2, and 3
rangeOfFourItems.firstValue = 6
// * this will report an error, even though firstValue is a variable property
由于 rangeOfFourItems 被声明为常量(用 let 关键字),我们不能改变其 firstValue 属性,即使 firstValue 是一个变量属性。
这是由于结构体是值类型。当一个值类型的实例被标记为常量时,该实例的其他属性也均为常量。
对于类来说则不同,它是引用类型。如果你给一个常量赋值引用类型实例,你仍然可以修改那个实例的变量属性。
1.2 延迟存储属性
延迟存储属性的初始值在其第一次使用时才进行计算。你可以通过在其声明前标注 lazy 修饰语来表示一个延迟存储属性。
你必须把延迟存储属性声明为变量(使用
var关键字),因为它的初始值可能在实例初始化完成之前无法取得。常量属性则必须在初始化完成之前有值,因此不能声明为延迟。
一个属性的初始值可能依赖于某些外部因素,当这些外部因素的值只有在实例的初始化完成后才能得到时,延迟属性就可以发挥作用了。而当属性的初始值需要执行复杂或代价高昂的配置才能获得,你又想要在需要时才执行,延迟属性就能够派上用场了。
下面这个栗子使用了一个延迟存储属性来避免复杂类不必要的初始化。这个例子定义了两个名为 DartImporter 和 DartManager 的类,他们都没有完整显示:
class DataImporter {
//DataImporter is a class to import data from an external file.
//The class is assumed to take a non-trivial amount of time to initialize.
var fileName = "data.txt"
// the DataImporter class would provide data importing functionality here
}
class DataManager {
lazy var importer = DataImporter()
var data = [String]()
// the DataManager class would provide data management functionality here
}
let manager = DataManager()
manager.data.append("Some data")
manager.data.append("Some more data")
// the DataImporter instance for the importer property has not yet been created
类 DataManager 有一个名为 data 的存储属性,它被初始化为一个空的新 String 数组。尽管它的其余功能没有展示出来,还是可以知道类 DataManager 的目的是管理并提供访问这个 String 数组的方法。
DataManager 类的功能之一是从文件导入数据。此功能由 DataImporter 类提供,它假定为需要一定时间来进行初始化。这大概是因为 DataImporter 实例在进行初始化的时候需要打开文件并读取其内容到内存中。
DataManager 实例并不要从文件导入数据就可以管理其数据的情况是有可能发生的,所以当 DataManager 本身创建的时候没有必要去再创建一个新的 DataImporter 实例。反之,在 DataImporter 第一次被使用的时候再创建它才更有意义。
因为它被 lazy 修饰符所标记,只有在 importer 属性第一次被访问时才会创建 DataManager 实例,比如当查询它的 fileName 属性时:
print(manager.importer.fileName)
// the DataImporter instance for the importer property has now been created
// prints "data.txt"
如果被标记为 lazy 修饰符的属性同时被多个线程访问并且属性还没有被初始化,则无法保证属性只初始化一次。
1.3 存储属性与实例变量
如果你有 Objective-C 的开发经验,那你应该知道在类实例里有两种方法来存储值和引用。另外,你还可以使用实例变量作为属性中所储存的值的备份存储。
Swift 把这些概念都统一到了属性声明里。Swift 属性没有与之相对应的实例变量,并且属性的后备存储不能被直接访问。这避免了不同环境中对值的访问的混淆并且将属性的声明简化为一条单一的、限定的语句。所有关于属性的信息——包括它的名字,类型和内存管理特征——都作为类的定义放在了同一个地方。
2 计算属性
除了存储属性,类、结构体和枚举也能够定义计算属性,而它实际并不存储值。相反,他们提供一个读取器和一个可选的设置器来间接得到和设置其他的属性和值。
struct Point {
var x = 0.0, y = 0.0
}
struct Size {
var width = 0.0, height = 0.0
}
struct Rect {
var origin = Point()
var size = Size()
var center: Point {
get {
let centerX = origin.x + (size.width / 2)
let centerY = origin.y + (size.height / 2)
return Point(x: centerX, y: centerY)
}
set(newCenter) {
origin.x = newCenter.x - (size.width / 2)
origin.y = newCenter.y - (size.height / 2)
}
}
}
var square = Rect(origin: Point(x: 0.0, y: 0.0),
size: Size(width: 10.0, height: 10.0))
let initialSquareCenter = square.center
square.center = Point(x: 15.0, y: 15.0)
print("square.origin is now at (\(square.origin.x), \(square.origin.y))")
// prints "square.origin is now at (10.0, 10.0)"
2.1 简写设置器(setter)声明
如果一个计算属性的设置器没有为将要被设置的值定义一个名字,那么他将被默认命名为 newValue 。下面是结构体 Rect 的另一种写法,其中利用了简写设置器声明的特性。
struct AlternativeRect {
var origin = Point()
var size = Size()
var center: Point {
get {
let centerX = origin.x + (size.width / 2)
let centerY = origin.y + (size.height / 2)
return Point(x: centerX, y: centerY)
}
set {
origin.x = newValue.x - (size.width / 2)
origin.y = newValue.y - (size.height / 2)
}
}
}
2.2 只读计算属性
一个有读取器但是没有设置器的计算属性就是所谓的只读计算属性。只读计算属性返回一个值,也可以通过点语法访问,但是不能被修改为另一个值。
你必须用
var关键字定义计算属性——包括只读计算属性——为变量属性,因为它们的值不是固定的。let关键字只用于常量属性,用于明确那些值一旦作为实例初始化就不能更改。
你可以通过去掉 get 关键字和他的大扩号来简化只读计算属性的声明:
struct Cuboid {
var width = 0.0, height = 0.0, depth = 0.0
var volume: Double {
return width * height * depth
}
}
let fourByFiveByTwo = Cuboid(width: 4.0, height: 5.0, depth: 2.0)
print("the volume of fourByFiveByTwo is \(fourByFiveByTwo.volume)")
// prints "the volume of fourByFiveByTwo is 40.0"
这个例子定义了一个名为 Cuboid 的新结构体,它代表了一个有 width , height 和 depth 属性的三维长方形结构。这个结构体还有一个名为 volume 的只读计算属性,它计算并返回长方体的当前体积。对于 volume 属性来说可被设置并没有意义,因为它会明确 width , height 和 depth 中哪个值用在特定的 volume 值中,对 Cuboid 来说提供一个只读计算属性来让外部用户来发现它的当前计算体积就显得很有用了。
3 属性观察者
属性观察者会观察并对属性值的变化做出回应。每当一个属性的值被设置时,属性观察者都会被调用,即使这个值与该属性当前的值相同。
你可以为你定义的任意存储属性添加属性观察者,除了延迟存储属性。你也可以通过在子类里重写属性来为任何继承属性(无论是存储属性还是计算属性)添加属性观察者。属性重载将会在重写中详细描述。
你不需要为非重写的计算属性定义属性观察者,因为你可以在计算属性的设置器里直接观察和相应它们值的改变。
你可以选择将这些观察者或其中之一定义在属性上:
willSet会在该值被存储之前被调用。didSet会在一个新值被存储后被调用。
如果你实现了一个 willSet 观察者,新的属性值会以常量形式参数传递。你可以在你的 willSet 实现中为这个参数定义名字。如果你没有为它命名,那么它会使用默认的名字 newValue 。
同样,如果你实现了一个 didSet 观察者,一个包含旧属性值的常量形式参数将会被传递。你可以为它命名,也可以使用默认的形式参数名 oldValue 。如果你在属性自己的 didSet 观察者里给自己赋值,你赋值的新值就会取代刚刚设置的值。
父类属性的
willSet和didSet观察者会在子类初始化器中设置时被调用。它们不会在类的父类初始化器调用中设置其自身属性时被调用。
这里有一个关于 willSet 和 didSet 的使用栗子。下面的栗子定义了一个名为 StepCounter 的新类,它追踪人散步的总数量。这个类可能会用于从计步器或者其他计步工具导入数据来追踪人日常的锻炼情况。
class StepCounter {
var totalSteps: Int = 0 {
willSet(newTotalSteps) {
print("About to set totalSteps to \(newTotalSteps)")
}
didSet {
if totalSteps > oldValue {
print("Added \(totalSteps - oldValue) steps")
}
}
}
}
let stepCounter = StepCounter()
stepCounter.totalSteps = 200
// About to set totalSteps to 200
// Added 200 steps
stepCounter.totalSteps = 360
// About to set totalSteps to 360
// Added 160 steps
stepCounter.totalSteps = 896
// About to set totalSteps to 896
// Added 536 steps
StepCounter 类声明了一个 Int 类型的 totalSteps 属性。这是一个包含了 willSet 和 didSet 观察者的储存属性。 totalSteps 的 willSet 和 didSet 观察者会在每次属性被赋新值的时候调用。就算新值与当前值完全相同也会如此。
栗子中的 willSet 观察者为增量的新值使用自定义的形式参数名 newTotalSteps ,它只是简单的打印出将要设置的值。
didSet 观察者在 totalSteps 的值更新后调用。它用旧值对比 totalSteps 的新值。如果总步数增加了,就打印一条信息来表示接收了多少新的步数。 didSet 观察者不会提供自定义的形式参数名给旧值,而是使用 oldValue 这个默认的名字。
如果你以输入输出形式参数传一个拥有观察者的属性给函数, willSet 和 didSet 观察者一定会被调用。这是由于输入输出形式参数的拷贝入拷贝出存储模型导致的:值一定会在函数结束后写回属性。
4 全局和局部变量
上边描述的计算属性和观察属性的能力同样对全局变量和局部变量有效。全局变量是定义在任何函数、方法、闭包或者类型环境之外的变量。局部变量是定义在函数、方法或者闭包环境之中的变量。
你在之前章节中所遇到的全局和局部变量都是存储变量。存储变量,类似于存储属性,为特定类型的值提供存储并且允许这个值被设置和取回。
总之,你同样可以定义计算属性以及给存储变量定义观察者,无论是全局还是局部环境。计算变量计算而不是存储值,并且与计算属性的写法一致。
全局常量和变量永远是延迟计算的,与延迟存储属性有着相同的行为。不同于延迟存储属性,全局常量和变量不需要标记
lazy修饰符。
5 类型属性
实例属性是属于特定类型实例的属性。每次你创建这个类型的新实例,它就拥有一堆属性值,与其他实例不同。
你同样可以定义属于类型本身的属性,不是这个类型的某一个实例的属性。这个属性只有一个拷贝,无论你创建了多少个类对应的实例。这样的属性叫做类型属性。
类型属性在定义那些对特定类型的所有实例都通用的值的时候很有用,比如实例要使用的常量属性(类似 C 里的静态常量),或者储存对这个类型的所有实例全局可见的值的存储属性(类似 C 里的静态变量)。
存储类型属性可以是变量或者常量。计算类型属性总要被声明为变量属性,与计算实例属性一致。
不同于存储实例属性,你必须总是给存储类型属性一个默认值。这是因为类型本身不能拥有能够在初始化时给存储类型属性赋值的初始化器。
存储类型属性是在它们第一次访问时延迟初始化的。它们保证只会初始化一次,就算被多个线程同时访问,他们也不需要使用 lazy 修饰符标记。
5.1 类型属性语法
在 C 和 Objective-C 中,你使用全局静态变量来定义一个与类型关联的静态常量和变量。在 Swift 中,总之,类型属性是写在类型的定义之中的,在类型的花括号里,并且每一个类型属性都显式地放在它支持的类型范围内。
使用 static 关键字来开一类型属性。对于类类型的计算类型属性,你可以使用 class 关键字来允许子类重写父类的实现。下面的栗子展示了存储和计算类型属性的语法:
struct SomeStructure {
static var storedTypeProperty = "Some value."
static var computedTypeProperty: Int {
return 1
}
}
enum SomeEnumeration {
static var storedTypeProperty = "Some value."
static var computedTypeProperty: Int {
return 6
}
}
class SomeClass {
static var storedTypeProperty = "Some value."
static var computedTypeProperty: Int {
return 27
}
class var overrideableComputedTypeProperty: Int {
return 107
}
}
5.2 查询和设置类型属性
类型属性使用点语法来查询和设置,与类型属性一致。总之,类型属性在类里查询和设置,而不是这个类型的实例。举例来说:
print(SomeStructure.storedTypeProperty)
// prints "Some value."
SomeStructure.storedTypeProperty = "Another value."
print(SomeStructure.storedTypeProperty)
// prints "Another value."
print(SomeEnumeration.computedTypeProperty)
// prints "6"
print(SomeClass.computedTypeProperty)
// prints "27"
方法
方法是与某些特定类型相关联的函数。类、结构体、枚举都可以定义实例方法;实例方法为给定类型的实例封装了具体的任务与功能。类、结构体、枚举也可以定义类型方法;类型方法与类型本身相关联。类型方法与 Objective-C 中的类方法(class methods)相似。
结构体和枚举能够定义方法是 Swift 与 C/Objective-C 的主要区别之一。在 Objective-C 中,类是唯一能定义方法的类型。但在 Swift 中,你不仅能选择是否要定义一个类/结构体/枚举,还能灵活地在你创建的类型(类/结构体/枚举)上定义方法。
1 实例方法
实例方法是属于某个特定类、结构体或者枚举类型实例的方法。实例方法提供访问和修改实例属性的方法或提供与实例目的相关的功能,并以此来支撑实例的功能。实例方法的语法与函数完全一致,详情参见函数。
实例方法要写在它所属的类型的前后大括号之间。实例方法能够隐式访问它所属类型的所有的其他实例方法和属性。实例方法只能被它所属的类的某个特定实例调用。实例方法不能脱离于现存的实例而被调用。
下面的例子,定义一个很简单的Counter类,Counter能被用来对一个动作发生的次数进行计数:
class Counter {
var count = 0
func increment() {
count += 1
}
func increment(by amount: Int) {
count += amount
}
func reset() {
count = 0
}
}
Counter类定义了三个实例方法:
- increment让计数器按一递增;
- increment(by: Int)让计数器按一个指定的整数值递增;
- reset将计数器重置为0。
Counter这个类还声明了一个可变属性count,用它来保持对当前计数器值的追踪。
和调用属性一样,用点语法(dot syntax)调用实例方法:
let counter = Counter()
// 初始计数值是0
counter.increment()
// 计数值现在是1
counter.increment(by: 5)
// 计数值现在是6
counter.reset()
// 计数值现在是0
函数参数可以同时有一个局部名称(在函数体内部使用)和一个外部名称(在调用函数时使用),详情参见指定外部参数名。方法参数也一样,因为方法就是函数,只是这个函数与某个类型相关联了。
1.1 self 属性
类型的每一个实例都有一个隐含属性叫做self,self完全等同于该实例本身。你可以在一个实例的实例方法中使用这个隐含的self属性来引用当前实例。
上面例子中的increment方法还可以这样写:
func increment() {
self.count += 1
}
实际上,你不必在你的代码里面经常写self。不论何时,只要在一个方法中使用一个已知的属性或者方法名称,如果你没有明确地写self,Swift 假定你是指当前实例的属性或者方法。这种假定在上面的Counter中已经示范了:Counter中的三个实例方法中都使用的是count(而不是self.count)。
使用这条规则的主要场景是实例方法的某个参数名称与实例的某个属性名称相同的时候。在这种情况下,参数名称享有优先权,并且在引用属性时必须使用一种更严格的方式。这时你可以使用self属性来区分参数名称和属性名称。
下面的例子中,self消除方法参数x和实例属性x之间的歧义:
struct Point {
var x = 0.0, y = 0.0
func isToTheRightOfX(_ x: Double) -> Bool {
return self.x > x
}
}
let somePoint = Point(x: 4.0, y: 5.0)
if somePoint.isToTheRightOfX(1.0) {
print("This point is to the right of the line where x == 1.0")
}
// 打印 "This point is to the right of the line where x == 1.0"
如果不使用self前缀,Swift 就认为两次使用的x都指的是名称为x的函数参数。
1.2 在实例方法中修改值类型
结构体和枚举是值类型。默认情况下,值类型属性不能被自身的实例方法修改。
总之,如果你需要在特定的方法中修改结构体或者枚举的属性,你可以选择将这个方法异变。然后这个方法就可以在方法中异变(嗯,改变)它的属性了,并且任何改变在方法结束的时候都会写入到原始的结构体中。方法同样可以指定一个全新的实例给它隐含的self属性,并且这个新的实例将会在方法结束的时候替换掉现存的这个实例。
你可以选择在 func关键字前放一个 mutating关键字来使用这个行为:
struct Point {
var x = 0.0, y = 0.0
mutating func moveBy(x deltaX: Double, y deltaY: Double) {
x += deltaX
y += deltaY
}
}
var somePoint = Point(x: 1.0, y: 1.0)
somePoint.moveBy(x: 2.0, y: 3.0)
print("The point is now at (\(somePoint.x), \(somePoint.y))")
// prints "The point is now at (3.0, 4.0)"
上文中的 Point 结构体定义了一个异变方法 moveBy(x:y:),它以特定的数值移动一个 Point实例。相比于返回一个新的点,这个方法实际上修改了调用它的点。 被添加到定义中的 mutating关键字允许它修改自身的属性。
注意,如同常量结构体实例的存储属性里描述的那样,你不能在常量结构体类型里调用异变方法,因为自身属性不能被改变,就算它们是变量属性:
let fixedPoint = Point(x: 3.0, y: 3.0)
fixedPoint.moveBy(x: 2.0, y: 3.0)
// this will report an error
1.3 在可变方法中给 self 赋值
可变方法能够赋给隐含属性self一个全新的实例。上面Point的例子可以用下面的方式改写:
struct Point {
var x = 0.0, y = 0.0
mutating func moveBy(x deltaX: Double, y deltaY: Double) {
self = Point(x: x + deltaX, y: y + deltaY)
}
}
新版的可变方法moveBy(x:y:)创建了一个新的结构体实例,它的 x 和 y 的值都被设定为目标值。调用这个版本的方法和调用上个版本的最终结果是一样的。
枚举的可变方法可以把self设置为同一枚举类型中不同的成员:
enum TriStateSwitch {
case Off, Low, High
mutating func next() {
switch self {
case .Off:
self = .Low
case .Low:
self = .High
case .High:
self = .Off
}
}
}
var ovenLight = TriStateSwitch.Low
ovenLight.next()
// ovenLight 现在等于 .High
ovenLight.next()
// ovenLight 现在等于 .Off
上面的例子中定义了一个三态开关的枚举。每次调用next()方法时,开关在不同的电源状态(Off,Low,High)之间循环切换。
2 类型方法
实例方法是被某个类型的实例调用的方法。你也可以定义在类型本身上调用的方法,这种方法就叫做类型方法。在方法的func关键字之前加上关键字static,来指定类型方法。类还可以用关键字class来允许子类重写父类的方法实现。
注意 在 Objective-C 中,你只能为 Objective-C 的类类型(classes)定义类型方法(type-level methods)。在 Swift 中,你可以为所有的类、结构体和枚举定义类型方法。每一个类型方法都被它所支持的类型显式包含。
类型方法和实例方法一样用点语法调用。但是,你是在类型上调用这个方法,而不是在实例上调用。下面是如何在SomeClass类上调用类型方法的例子:
class SomeClass {
class func someTypeMethod() {
// 在这里实现类型方法
}
}
SomeClass.someTypeMethod()
在类型方法的方法体(body)中,self指向这个类型本身,而不是类型的某个实例。这意味着你可以用self来消除类型属性和类型方法参数之间的歧义(类似于我们在前面处理实例属性和实例方法参数时做的那样)。
一般来说,在类型方法的方法体中,任何未限定的方法和属性名称,可以被本类中其他的类型方法和类型属性引用。一个类型方法可以直接通过类型方法的名称调用本类中的其它类型方法,而无需在方法名称前面加上类型名称。类似地,在结构体和枚举中,也能够直接通过类型属性的名称访问本类中的类型属性,而不需要前面加上类型名称。
下面的例子定义了一个名为LevelTracker结构体。它监测玩家的游戏发展情况(游戏的不同层次或阶段)。这是一个单人游戏,但也可以存储多个玩家在同一设备上的游戏信息。
游戏初始时,所有的游戏等级(除了等级 1)都被锁定。每次有玩家完成一个等级,这个等级就对这个设备上的所有玩家解锁。LevelTracker结构体用类型属性和方法监测游戏的哪个等级已经被解锁。它还监测每个玩家的当前等级。
struct LevelTracker {
static var highestUnlockedLevel = 1
var currentLevel = 1
static func unlock(_ level: Int) {
if level > highestUnlockedLevel { highestUnlockedLevel = level }
}
static func isUnlocked(_ level: Int) -> Bool {
return level <= highestUnlockedLevel
}
@discardableResult
mutating func advance(to level: Int) -> Bool {
if LevelTracker.isUnlocked(level) {
currentLevel = level
return true
} else {
return false
}
}
}
LevelTracker监测玩家已解锁的最高等级。这个值被存储在类型属性highestUnlockedLevel中。
LevelTracker还定义了两个类型方法与highestUnlockedLevel配合工作。第一个类型方法是unlock(:),一旦新等级被解锁,它会更新highestUnlockedLevel的值。第二个类型方法是isUnlocked(:),如果某个给定的等级已经被解锁,它将返回true。(注意,尽管我们没有使用类似LevelTracker.highestUnlockedLevel的写法,这个类型方法还是能够访问类型属性highestUnlockedLevel)
除了类型属性和类型方法,LevelTracker还监测每个玩家的进度。它用实例属性currentLevel来监测每个玩家当前的等级。
为了便于管理currentLevel属性,LevelTracker定义了实例方法advance(to:)。这个方法会在更新currentLevel之前检查所请求的新等级是否已经解锁。advance(to:)方法返回布尔值以指示是否能够设置currentLevel。因为允许在调用advance(to:)时候忽略返回值,不会产生编译警告,所以函数被标注为@ discardableResult属性,更多关于属性信息,请参考属性章节。
下面,Player类使用LevelTracker来监测和更新每个玩家的发展进度:
class Player {
var tracker = LevelTracker()
let playerName: String
func complete(level: Int) {
LevelTracker.unlock(level + 1)
tracker.advance(to: level + 1)
}
init(name: String) {
playerName = name
}
}
Player类创建一个新的LevelTracker实例来监测这个用户的进度。它提供了complete(level:)方法,一旦玩家完成某个指定等级就调用它。这个方法为所有玩家解锁下一等级,并且将当前玩家的进度更新为下一等级。(我们忽略了advance(to:)返回的布尔值,因为之前调用LevelTracker.unlock(_:)时就知道了这个等级已经被解锁了)。
你还可以为一个新的玩家创建一个Player的实例,然后看这个玩家完成等级一时发生了什么:
var player = Player(name: "Argyrios")
player.complete(level: 1)
print("highest unlocked level is now \(LevelTracker.highestUnlockedLevel)")
// 打印 "highest unlocked level is now 2"
如果你创建了第二个玩家,并尝试让他开始一个没有被任何玩家解锁的等级,那么试图设置玩家当前等级将会失败:
player = Player(name: "Beto")
if player.tracker.advance(to: 6) {
print("player is now on level 6")
} else {
print("level 6 has not yet been unlocked")
}
// 打印 "level 6 has not yet been unlocked"
下标
下标可以定义在类、结构体和枚举中,是访问集合、列表或序列中元素的快捷方式。可以使用下标的索引,设置和获取值,而不需要再调用对应的存取方法。举例来说,用下标访问一个Array实例中的元素可以写作someArray[index],访问Dictionary实例中的元素可以写作someDictionary[key]。
一个类型可以定义多个下标,通过不同索引类型进行重载。下标不限于一维,你可以定义具有多个入参的下标满足自定义类型的需求。
1 下标语法
下标允许你通过在实例名称后面的方括号中传入一个或者多个索引值来对实例进行存取。语法类似于实例方法语法和计算型属性语法的混合。与定义实例方法类似,定义下标使用subscript关键字,指定一个或多个输入参数和返回类型;与实例方法不同的是,下标可以设定为读写或只读。这种行为由 getter 和 setter 实现,有点类似计算型属性:
subscript(index: Int) -> Int {
get {
// 返回一个适当的 Int 类型的值
}
set(newValue) {
// 执行适当的赋值操作
}
}
newValue的类型和下标的返回类型相同。如同计算型属性,可以不指定 setter 的参数(newValue)。如果不指定参数,setter 会提供一个名为newValue的默认参数。
如同只读计算型属性,可以省略只读下标的get关键字:
subscript(index: Int) -> Int {
// 返回一个适当的 Int 类型的值
}
下面代码演示了只读下标的实现,这里定义了一个TimesTable结构体,用来表示传入整数的乘法表:
struct TimesTable {
let multiplier: Int
subscript(index: Int) -> Int {
return multiplier * index
}
}
let threeTimesTable = TimesTable(multiplier: 3)
print("six times three is \(threeTimesTable[6])")
// 打印 "six times three is 18"
在上例中,创建了一个TimesTable实例,用来表示整数3的乘法表。数值3被传递给结构体的构造函数,作为实例成员multiplier的值。
你可以通过下标访问threeTimesTable实例,例如上面演示的threeTimesTable[6]。这条语句查询了3的乘法表中的第六个元素,返回3的6倍即18。
注意 TimesTable例子基于一个固定的数学公式,对threeTimesTable[someIndex]进行赋值操作并不合适,因此下标定义为只读的。
2 下标用法
下标的确切含义取决于使用场景。下标通常作为访问集合,列表或序列中元素的快捷方式。你可以针对自己特定的类或结构体的功能来自由地以最恰当的方式实现下标。
例如,Swift 的Dictionary类型实现下标用于对其实例中储存的值进行存取操作。为字典设值时,在下标中使用和字典的键类型相同的键,并把一个和字典的值类型相同的值赋给这个下标:
var numberOfLegs = ["spider": 8, "ant": 6, "cat": 4]
numberOfLegs["bird"] = 2
上例定义一个名为numberOfLegs的变量,并用一个包含三对键值的字典字面量初始化它。numberOfLegs字典的类型被推断为[String: Int]。字典创建完成后,该例子通过下标将String类型的键bird和Int类型的值2添加到字典中。
注意 Swift 的Dictionary类型的下标接受并返回可选类型的值。上例中的numberOfLegs字典通过下标返回的是一个Int?或者说“可选的int”。Dictionary类型之所以如此实现下标,是因为不是每个键都有个对应的值,同时这也提供了一种通过键删除对应值的方式,只需将键对应的值赋值为nil即可。
3 下标选项
下标可以接受任意数量的入参,并且这些入参可以是任意类型。下标的返回值也可以是任意类型。下标可以使用变量参数和可变参数,但不能使用输入输出参数,也不能给参数设置默认值。
一个类或结构体可以根据自身需要提供多个下标实现,使用下标时将通过入参的数量和类型进行区分,自动匹配合适的下标,这就是下标的重载。
虽然接受单一入参的下标是最常见的,但也可以根据情况定义接受多个入参的下标。例如下例定义了一个Matrix结构体,用于表示一个Double类型的二维矩阵。Matrix结构体的下标接受两个整型参数:
struct Matrix {
let rows: Int, columns: Int
var grid: [Double]
init(rows: Int, columns: Int) {
self.rows = rows
self.columns = columns
grid = Array(repeating: 0.0, count: rows * columns)
}
func indexIsValid(row: Int, column: Int) -> Bool {
return row >= 0 && row < rows && column >= 0 && column < columns
}
subscript(row: Int, column: Int) -> Double {
get {
assert(indexIsValid(row: row, column: column), "Index out of range")
return grid[(row * columns) + column]
}
set {
assert(indexIsValid(row: row, column: column), "Index out of range")
grid[(row * columns) + column] = newValue
}
}
}
Matrix提供了一个接受两个入参的构造方法,入参分别是rows和columns,创建了一个足够容纳rows * columns个Double类型的值的数组。通过传入数组长度和初始值0.0到数组的构造器,将矩阵中每个位置的值初始化为0.0。关于数组的这种构造方法请参考创建一个空数组。
你可以通过传入合适的row和column的数量来构造一个新的Matrix实例:
var matrix = Matrix(rows: 2, columns: 2)
上例中创建了一个Matrix实例来表示两行两列的矩阵。该Matrix实例的grid数组按照从左上到右下的阅读顺序将矩阵扁平化存储:
将row和column的值传入下标来为矩阵设值,下标的入参使用逗号分隔:
matrix[0, 1] = 1.5
matrix[1, 0] = 3.2
上面两条语句分别调用下标的 setter 将矩阵右上角位置(即row为0、column为1的位置)的值设置为1.5,将矩阵左下角位置(即row为1、column为0的位置)的值设置为3.2:
Matrix下标的 getter 和 setter 中都含有断言,用来检查下标入参row和column的值是否有效。为了方便进行断言,Matrix包含了一个名为indexIsValid(row:column:)的便利方法,用来检查入参row和column的值是否在矩阵范围内:
func indexIsValid(row: Int, column: Int) -> Bool {
return row >= 0 && row < rows && column >= 0 && column < columns
}
断言在下标越界时触发:
let someValue = matrix[2, 2]
// 断言将会触发,因为 [2, 2] 已经超过了 matrix 的范围
继承
一个类可以继承另一个类的方法,属性和其它特性。当一个类继承其它类时,继承类叫子类,被继承类叫超类(或父类)。在 Swift 中,继承是区分「类」与其它类型的一个基本特征。
在 Swift 中,类可以调用和访问超类的方法、属性和下标,并且可以重写这些方法,属性和下标来优化或修改它们的行为。Swift 会检查你的重写定义在超类中是否有匹配的定义,以此确保你的重写行为是正确的。
可以为类中继承来的属性添加属性观察器,这样一来,当属性值改变时,类就会被通知到。可以为任何属性添加属性观察器,无论它原本被定义为存储型属性还是计算型属性。
1 定义一个基类
不继承于其它类的类,称之为基类。
注意 Swift 中的类并不是从一个通用的基类继承而来。如果你不为你定义的类指定一个超类的话,这个类就自动成为基类。
下面的例子定义了一个叫Vehicle的基类。这个基类声明了一个名为currentSpeed,默认值是0.0的存储属性(属性类型推断为Double)。currentSpeed属性的值被一个String类型的只读计算型属性description使用,用来创建车辆的描述。
Vehicle基类也定义了一个名为makeNoise的方法。这个方法实际上不为Vehicle实例做任何事,但之后将会被Vehicle的子类定制:
class Vehicle {
var currentSpeed = 0.0
var description: String {
return "traveling at \(currentSpeed) miles per hour"
}
func makeNoise() {
// 什么也不做-因为车辆不一定会有噪音
}
}
您可以用初始化语法创建一个Vehicle的新实例,即类名后面跟一个空括号:
let someVehicle = Vehicle()
现在已经创建了一个Vehicle的新实例,你可以访问它的description属性来打印车辆的当前速度:
print("Vehicle: \(someVehicle.description)")
// 打印 "Vehicle: traveling at 0.0 miles per hour"
Vehicle类定义了一个通用特性的车辆类,实际上没什么用处。为了让它变得更加有用,需要完善它从而能够描述一个更加具体类型的车辆。
2 子类
子类生成指的是在一个已有类的基础上创建一个新的类。子类继承超类的特性,并且可以进一步完善。你还可以为子类添加新的特性。
为了指明某个类的超类,将超类名写在子类名的后面,用冒号分隔:
class SomeClass: SomeSuperclass {
// 这里是子类的定义
}
下一个例子,定义一个叫Bicycle的子类,继承成父类Vehicle:
class Bicycle: Vehicle {
var hasBasket = false
}
新的Bicycle类自动获得Vehicle类的所有特性,比如currentSpeed和description属性,还有它的makeNoise()方法。
除了它所继承的特性,Bicycle类还定义了一个默认值为false的存储型属性hasBasket(属性推断为Bool)。
默认情况下,你创建任何新的Bicycle实例将不会有一个篮子(即hasBasket属性默认为false),创建该实例之后,你可以为特定的Bicycle实例设置hasBasket属性为ture:
let bicycle = Bicycle()
bicycle.hasBasket = true
你还可以修改Bicycle实例所继承的currentSpeed属性,和查询实例所继承的description属性:
bicycle.currentSpeed = 15.0
print("Bicycle: \(bicycle.description)")
// 打印 "Bicycle: traveling at 15.0 miles per hour"
子类还可以继续被其它类继承,下面的示例为Bicycle创建了一个名为Tandem(双人自行车)的子类:
class Tandem: Bicycle {
var currentNumberOfPassengers = 0
}
Tandem从Bicycle继承了所有的属性与方法,这又使它同时继承了Vehicle的所有属性与方法。Tandem也增加了一个新的叫做currentNumberOfPassengers的存储型属性,默认值为0。
如果你创建了一个Tandem的实例,你可以使用它所有的新属性和继承的属性,还能查询从Vehicle继承来的只读属性description:
let tandem = Tandem()
tandem.hasBasket = true
tandem.currentNumberOfPassengers = 2
tandem.currentSpeed = 22.0
print("Tandem: \(tandem.description)")
// 打印:"Tandem: traveling at 22.0 miles per hour"
3 重写
子类可以提供它自己的实例方法、类型方法、实例属性,类型属性或下标脚本的自定义实现,否则它将会从父类继承。这就所谓的重写。
要重写而不是继承一个特征,你需要在你的重写定义前面加上 override 关键字。这样做说明你打算提供一个重写而不是意外提供了一个相同定义。意外的重写可能导致意想不到的行为,并且任何没有使用 override 关键字的重写都会在编译时被诊断为错误。
override 关键字会执行 Swift 编译器检查你重写的类的父类(或者父类的父类)是否有与之匹配的声明来供你重写。这个检查确保你重写的定义是正确的。
3.1 访问父类的方法、属性和下标
当你在子类中重写超类的方法,属性或下标时,有时在你的重写版本中使用已经存在的超类实现会大有裨益。比如,你可以完善已有实现的行为,或在一个继承来的变量中存储一个修改过的值。
在合适的地方,你可以通过使用super前缀来访问超类版本的方法,属性或下标:
- 在方法someMethod()的重写实现中,可以通过super.someMethod()来调用超类版本的someMethod()方法。
- 在属性someProperty的 getter 或 setter 的重写实现中,可以通过super.someProperty来访问超类版本的someProperty属性。
- 在下标的重写实现中,可以通过super[someIndex]来访问超类版本中的相同下标。
3.2 重写方法
在子类中,你可以重写继承来的实例方法或类方法,提供一个定制或替代的方法实现。
下面的例子定义了Vehicle的一个新的子类,叫Train,它重写了从Vehicle类继承来的makeNoise()方法:
class Train: Vehicle {
override func makeNoise() {
print("Choo Choo")
}
}
如果你创建一个Train的新实例,并调用了它的makeNoise()方法,你就会发现Train版本的方法被调用:
let train = Train()
train.makeNoise()
// 打印 "Choo Choo"
3.3 重写属性
你可以重写继承来的实例属性或类型属性,提供自己定制的 getter 和 setter,或添加属性观察器使重写的属性可以观察属性值什么时候发生改变。
你可以提供定制的 getter(或 setter)来重写任意继承来的属性,无论继承来的属性是存储型的还是计算型的属性。子类并不知道继承来的属性是存储型的还是计算型的,它只知道继承来的属性会有一个名字和类型。你在重写一个属性时,必需将它的名字和类型都写出来。这样才能使编译器去检查你重写的属性是与超类中同名同类型的属性相匹配的。
你可以将一个继承来的只读属性重写为一个读写属性,只需要在重写版本的属性里提供 getter 和 setter 即可。但是,你不可以将一个继承来的读写属性重写为一个只读属性。
注意 如果你在重写属性中提供了 setter,那么你也一定要提供 getter。如果你不想在重写版本中的 getter 里修改继承来的属性值,你可以直接通过super.someProperty来返回继承来的值,其中someProperty是你要重写的属性的名字。
以下的例子定义了一个新类,叫Car,它是Vehicle的子类。这个类引入了一个新的存储型属性叫做gear,默认值为整数1。Car类重写了继承自Vehicle的description属性,提供包含当前档位的自定义描述:
class Car: Vehicle {
var gear = 1
override var description: String {
return super.description + " in gear \(gear)"
}
}
重写的description属性首先要调用super.description返回Vehicle类的description属性。之后,Car类版本的description在末尾增加了一些额外的文本来提供关于当前档位的信息。
如果你创建了Car的实例并且设置了它的gear和currentSpeed属性,你可以看到它的description返回了Car中的自定义描述:
let car = Car()
car.currentSpeed = 25.0
car.gear = 3
print("Car: \(car.description)")
// 打印 "Car: traveling at 25.0 miles per hour in gear 3"
3.4 重写属性观察器
你可以通过重写属性为一个继承来的属性添加属性观察器。这样一来,当继承来的属性值发生改变时,你就会被通知到,无论那个属性原本是如何实现的。关于属性观察器的更多内容,请看属性观察器。
注意 你不可以为继承来的常量存储型属性或继承来的只读计算型属性添加属性观察器。这些属性的值是不可以被设置的,所以,为它们提供willSet或didSet实现是不恰当。 此外还要注意,你不可以同时提供重写的 setter 和重写的属性观察器。如果你想观察属性值的变化,并且你已经为那个属性提供了定制的 setter,那么你在 setter 中就可以观察到任何值变化了。
下面的例子定义了一个新类叫AutomaticCar,它是Car的子类。AutomaticCar表示自动挡汽车,它可以根据当前的速度自动选择合适的挡位:
class AutomaticCar: Car {
override var currentSpeed: Double {
didSet {
gear = Int(currentSpeed / 10.0) + 1
}
}
}
当你设置AutomaticCar的currentSpeed属性,属性的didSet观察器就会自动地设置gear属性,为新的速度选择一个合适的挡位。具体来说就是,属性观察器将新的速度值除以10,然后向下取得最接近的整数值,最后加1来得到档位gear的值。例如,速度为35.0时,挡位为4:
let automatic = AutomaticCar()
automatic.currentSpeed = 35.0
print("AutomaticCar: \(automatic.description)")
// 打印 "AutomaticCar: traveling at 35.0 miles per hour in gear 4"
4 阻止重写
你可以通过把方法,属性或下标标记为final来防止它们被重写,只需要在声明关键字前加上final修饰符即可(例如:final var,final func,final class func,以及final subscript)。
如果你重写了带有final标记的方法、属性或下标,在编译时会报错。在类扩展中的方法,属性或下标也可以在扩展的定义里标记为 final 的。
你可以通过在关键字class前添加final修饰符(final class)来将整个类标记为 final 的。这样的类是不可被继承的,试图继承这样的类会导致编译报错。
构造过程
构造过程是使用类、结构体或枚举类型的实例之前的准备过程。在新实例可用前必须执行这个过程,具体操作包括设置实例中每个存储型属性的初始值和执行其他必须的设置或初始化工作。
通过定义构造器来实现构造过程,就像用来创建特定类型新实例的特殊方法。与 Objective-C 中的构造器不同,Swift 的构造器无需返回值,它们的主要任务是保证新实例在第一次使用前完成正确的初始化。
类的实例也可以通过定义析构器在实例释放之前执行特定的清除工作。想了解更多关于析构器的内容,请参考析构过程。
1 存储属性的初始赋值
类和结构体在创建实例时,必须为所有存储型属性设置合适的初始值。存储型属性的值不能处于一个未知的状态。
你可以在构造器中为存储型属性赋初值,也可以在定义属性时为其设置默认值。以下小节将详细介绍这两种方法。
注意 当你为存储型属性设置默认值或者在构造器中为其赋值时,它们的值是被直接设置的,不会触发任何属性观察者。
1.1 构造器
构造器在创建某个特定类型的新实例时被调用。它的最简形式类似于一个不带任何参数的实例方法,以关键字 init 命名:
init() {
// 在此处执行构造过程
}
下面例子中定义了一个用来保存华氏温度的结构体 Fahrenheit,它拥有一个 Double 类型的存储型属性 temperature:
struct Fahrenheit {
var temperature: Double
init() {
temperature = 32.0
}
}
var f = Fahrenheit()
print("The default temperature is \(f.temperature)° Fahrenheit")
// 打印 "The default temperature is 32.0° Fahrenheit"
这个结构体定义了一个不带参数的构造器 init,并在里面将存储型属性 temperature 的值初始化为 32.0(华氏温度下水的冰点)。
1.2 默认的属性值
如上所述,你可以在初始化器里为存储属性设置初始值。另外,指定一个默认属性值作为属性声明的一部分。当属性被定义的时候你可以通过为这个属性分配一个初始值来指定默认的属性值。
如果一个属性一直保持相同的初始值,可以提供一个默认值而不是在初始化器里设置这个值。最终结果是一样的,但是默认值将属性的初始化与声明更紧密地联系到一起。它使得你的初始化器更短更清晰,并且可以让你属性根据默认值推断类型。如后边的章节所述,默认值也让你使用默认初始化器和初始化器继承更加容易。
通过提供 temperature 属性的默认值,你可以把上面的 Fahrenheit 结构体写的更简单:
struct Fahrenheit {
var temperature = 32.0
}
2 自定义构造过程
你可以通过输入参数和可选类型的属性来自定义构造过程,也可以在构造过程中给常量属性赋初值。这些都将在后面章节中提到。
2.1 构造参数
自定义构造过程时,可以在定义中提供构造参数,指定参数值的类型和名字。构造参数的功能和语法跟函数和方法的参数相同。
下面例子中定义了一个包含摄氏度温度的结构体 Celsius。它定义了两个不同的构造器:init(fromFahrenheit:)和init(fromKelvin:),二者分别通过接受不同温标下的温度值来创建新的实例:
struct Celsius {
var temperatureInCelsius: Double
init(fromFahrenheit fahrenheit: Double) {
temperatureInCelsius = (fahrenheit - 32.0) / 1.8
}
init(fromKelvin kelvin: Double) {
temperatureInCelsius = kelvin - 273.15
}
}
let boilingPointOfWater = Celsius(fromFahrenheit: 212.0)
// boilingPointOfWater.temperatureInCelsius 是 100.0
let freezingPointOfWater = Celsius(fromKelvin: 273.15)
// freezingPointOfWater.temperatureInCelsius 是 0.0
第一个构造器拥有一个构造参数,其外部名字为fromFahrenheit,内部名字为fahrenheit;第二个构造器也拥有一个构造参数,其外部名字为fromKelvin,内部名字为kelvin。这两个构造器都将唯一的参数值转换成摄氏温度值,并保存在属性 temperatureInCelsius 中。
2.2 参数的内部名称和外部名称
跟函数和方法参数相同,构造参数也拥有一个在构造器内部使用的参数名字和一个在调用构造器时使用的外部参数名字。
然而,构造器并不像函数和方法那样在括号前有一个可辨别的名字。因此在调用构造器时,主要通过构造器中的参数名和类型来确定应该被调用的构造器。正因为参数如此重要,如果你在定义构造器时没有提供参数的外部名字,Swift 会为构造器的每个参数自动生成一个跟内部名字相同的外部名。
以下例子中定义了一个结构体 Color,它包含了三个常量:red、green 和 blue。这些属性可以存储 0.0 到 1.0 之间的值,用来指示颜色中红、绿、蓝成分的含量。
Color 提供了一个构造器,其中包含三个Double类型的构造参数。Color 也提供了第二个构造器,它只包含名为white 的 Double 类型的参数,它被用于给上述三个构造参数赋予同样的值。
struct Color {
let red, green, blue: Double
init(red: Double, green: Double, blue: Double) {
self.red = red
self.green = green
self.blue = blue
}
init(white: Double) {
red = white
green = white
blue = white
}
}
两种构造器都能通过提供的初始参数值来创建一个新的Color实例:
let magenta = Color(red: 1.0, green: 0.0, blue: 1.0)
let halfGray = Color(white: 0.5)
注意,如果不通过外部参数名字传值,你是没法调用这个构造器的。只要构造器定义了某个外部参数名,你就必须使用它,忽略它将导致编译错误:
let veryGreen = Color(0.0, 1.0, 0.0)
// 报编译时错误,需要外部名称
2.3 不带外部名的构造器参数
如果你不希望为构造器的某个参数提供外部名字,你可以使用下划线(_)来显式描述它的外部名,以此重写上面所说的默认行为。
下面是之前 Celsius 例子的扩展,跟之前相比添加了一个带有 Double 类型参数的构造器,其外部名用 _ 代替:
struct Celsius {
var temperatureInCelsius: Double
init(fromFahrenheit fahrenheit: Double) {
temperatureInCelsius = (fahrenheit - 32.0) / 1.8
}
init(fromKelvin kelvin: Double) {
temperatureInCelsius = kelvin - 273.15
}
init(_ celsius: Double){
temperatureInCelsius = celsius
}
}
let bodyTemperature = Celsius(37.0)
// bodyTemperature.temperatureInCelsius 为 37.0
调用 Celsius(37.0) 意图明确,不需要外部参数名称。因此适合使用 init(_ celsius: Double) 这样的构造器,从而可以通过提供 Double 类型的参数值调用构造器,而不需要加上外部名。
2.4 可选属性类型
如果你定制的类型包含一个逻辑上允许取值为空的存储型属性——无论是因为它无法在初始化时赋值,还是因为它在之后某个时间点可以赋值为空——你都需要将它定义为可选类型。可选类型的属性将自动初始化为 nil,表示这个属性是有意在初始化时设置为空的。
下面例子中定义了类 SurveyQuestion,它包含一个可选字符串属性 response:
class SurveyQuestion {
var text: String
var response: String?
init(text: String) {
self.text = text
}
func ask() {
print(text)
}
}
let cheeseQuestion = SurveyQuestion(text: "Do you like cheese?")
cheeseQuestion.ask()
// 打印 "Do you like cheese?"
cheeseQuestion.response = "Yes, I do like cheese."
调查问题的答案在回答前是无法确定的,因此我们将属性 response 声明为 String? 类型,或者说是可选字符串类型。当 SurveyQuestion 实例化时,它将自动赋值为nil,表明此字符串暂时还没有值。
2.5 构造过程中常量属性的赋值
你可以在构造过程中的任意时间点给常量属性指定一个值,只要在构造过程结束时是一个确定的值。一旦常量属性被赋值,它将永远不可更改。
注意 对于类的实例来说,它的常量属性只能在定义它的类的构造过程中修改;不能在子类中修改。
你可以修改上面的 SurveyQuestion 示例,用常量属性替代变量属性 text,表示问题内容 text 在SurveyQuestion的实例被创建之后不会再被修改。尽管 text 属性现在是常量,我们仍然可以在类的构造器中设置它的值:
class SurveyQuestion {
let text: String
var response: String?
init(text: String) {
self.text = text
}
func ask() {
print(text)
}
}
let beetsQuestion = SurveyQuestion(text: "How about beets?")
beetsQuestion.ask()
// 打印 "How about beets?"
beetsQuestion.response = "I also like beets. (But not with cheese.)"
3 默认构造器
如果结构体或类的所有属性都有默认值,同时没有自定义的构造器,那么 Swift 会给这些结构体或类提供一个默认构造器(default initializers)。这个默认构造器将简单地创建一个所有属性值都设置为默认值的实例。
下面例子中创建了一个类 ShoppingListItem,它封装了购物清单中的某一物品的属性:名字(name)、数量(quantity)和购买状态 purchase state:
class ShoppingListItem {
var name: String?
var quantity = 1
var purchased = false
}
var item = ShoppingListItem()
由于 ShoppingListItem 类中的所有属性都有默认值,且它是没有父类的基类,它将自动获得一个可以为所有属性设置默认值的默认构造器(尽管代码中没有显式为name属性设置默认值,但由于name是可选字符串类型,它将默认设置为nil)。上面例子中使用默认构造器创造了一个 ShoppingListItem 类的实例(使用 ShoppingListItem() 形式的构造器语法),并将其赋值给变量 item。
除了上面提到的默认构造器,如果结构体没有提供自定义的构造器,它们将自动获得一个逐一成员构造器,即使结构体的存储型属性没有默认值。
逐一成员构造器是用来初始化结构体新实例里成员属性的快捷方法。我们在调用逐一成员构造器时,通过与成员属性名相同的参数名进行传值来完成对成员属性的初始赋值。
下面例子中定义了一个结构体 Size,它包含两个属性 width 和 height。Swift 可以根据这两个属性的初始赋值0.0 自动推导出它们的类型为 Double。
结构体 Size 自动获得了一个逐一成员构造器 init(width:height:)。你可以用它来创建新的 Size 实例:
struct Size {
var width = 0.0, height = 0.0
}
let twoByTwo = Size(width: 2.0, height: 2.0)
4 值类型的构造器代理
构造器可以通过调用其它构造器来完成实例的部分构造过程。这一过程称为构造器代理,它能避免多个构造器间的代码重复。
构造器代理的实现规则和形式在值类型和类类型中有所不同。值类型(结构体和枚举类型)不支持继承,所以构造器代理的过程相对简单,因为它们只能代理给自己的其它构造器。类则不同,它可以继承自其它类(请参考继承),这意味着类有责任保证其所有继承的存储型属性在构造时也能正确的初始化。这些责任将在后续章节类的继承和构造过程中介绍。
对于值类型,你可以使用 self.init 在自定义的构造器中引用相同类型中的其它构造器。并且你只能在构造器内部调用 self.init。
请注意,如果你为某个值类型定义了一个自定义的构造器,你将无法访问到默认构造器(如果是结构体,还将无法访问逐一成员构造器)。这种限制可以防止你为值类型增加了一个额外的且十分复杂的构造器之后,仍然有人错误的使用自动生成的构造器。
注意 假如你希望默认构造器、逐一成员构造器以及你自己的自定义构造器都能用来创建实例,可以将自定义的构造器写到扩展(extension)中,而不是写在值类型的原始定义中。想查看更多内容,请查看扩展章节。
下面例子将定义一个结构体 Rect,用来代表几何矩形。这个例子需要两个辅助的结构体 Size 和 Point,它们各自为其所有的属性提供了默认初始值 0.0。
struct Size {
var width = 0.0, height = 0.0
}
struct Point {
var x = 0.0, y = 0.0
}
你可以通过以下三种方式为 Rect 创建实例——使用含有默认值的 origin 和 size 属性来初始化;提供指定的origin 和 size 实例来初始化;提供指定的 center 和 size 来初始化。在下面 Rect 结构体定义中,我们为这三种方式提供了三个自定义的构造器:
struct Rect {
var origin = Point()
var size = Size()
init() {}
init(origin: Point, size: Size) {
self.origin = origin
self.size = size
}
init(center: Point, size: Size) {
let originX = center.x - (size.width / 2)
let originY = center.y - (size.height / 2)
self.init(origin: Point(x: originX, y: originY), size: size)
}
}
第一个 Rect 构造器 init(),在功能上跟没有自定义构造器时自动获得的默认构造器是一样的。这个构造器是一个空函数,使用一对大括号 {} 来表示。调用这个构造器将返回一个 Rect 实例,它的 origin 和 size 属性都使用定义时的默认值 Point(x: 0.0, y: 0.0) 和 Size(width: 0.0, height: 0.0):
let basicRect = Rect()
// basicRect 的 origin 是 (0.0, 0.0),size 是 (0.0, 0.0)
第二个 Rect 构造器 init(origin:size:),在功能上跟结构体在没有自定义构造器时获得的逐一成员构造器是一样的。这个构造器只是简单地将 origin 和 size 的参数值赋给对应的存储型属性:
let originRect = Rect(origin: Point(x: 2.0, y: 2.0),
size: Size(width: 5.0, height: 5.0))
// originRect 的 origin 是 (2.0, 2.0),size 是 (5.0, 5.0)
第三个 Rect 构造器 init(center:size:) 稍微复杂一点。它先通过 center 和 size 的值计算出 origin 的坐标,然后再调用(或者说代理给)init(origin:size:) 构造器来将新的 origin 和 size 值赋值到对应的属性中:
let centerRect = Rect(center: Point(x: 4.0, y: 4.0),
size: Size(width: 3.0, height: 3.0))
// centerRect 的 origin 是 (2.5, 2.5),size 是 (3.0, 3.0)
构造器 init(center:size:) 可以直接将 origin 和 size 的新值赋值到对应的属性中。然而,构造器 init(center:size:) 通过使用提供了相关功能的现有构造器将会更加便捷。
注意 如果你想用另外一种不需要自己定义init()和init(origin:size:)的方式来实现这个例子,请参考扩展。
5 类的继承和构造过程
类里面的所有存储型属性——包括所有继承自父类的属性——都必须在构造过程中设置初始值。
Swift 为类类型提供了两种构造器来确保实例中所有存储型属性都能获得初始值,它们分别是指定构造器和便利构造器。
5.1 指定构造器和便利构造器
指定构造器是类中最主要的构造器。一个指定构造器将初始化类中提供的所有属性,并根据父类链往上调用父类合适的构造器来实现父类的初始化。
类倾向于拥有少量指定构造器,普遍的是一个类拥有一个指定构造器。指定构造器在初始化的地方通过“管道”将初始化过程持续到父类链。
每一个类都必须至少拥有一个指定构造器。在某些情况下,许多类通过继承了父类中的指定构造器而满足了这个条件。具体内容请参考后续章节构造器的自动继承。
便利构造器是类中比较次要的、辅助型的构造器。你可以定义便利构造器来调用同一个类中的指定构造器,并为其参数提供默认值。你也可以定义便利构造器来创建一个特殊用途或特定输入值的实例。
你应当只在必要的时候为类提供便利构造器,比方说某种情况下通过使用便利构造器来快捷调用某个指定构造器,能够节省更多开发时间并让类的构造过程更清晰明了。
5.2 指定构造器和便利构造器的语法
类的指定构造器的写法跟值类型简单构造器一样:
init(parameters) {
statements
}
便利构造器也采用相同样式的写法,但需要在 init 关键字之前放置 convenience 关键字,并使用空格将它们俩分开:
convenience init(parameters) {
statements
}
5.3 类的构造器代理规则
为了简化指定构造器和便利构造器之间的调用关系,Swift 采用以下三条规则来限制构造器之间的代理调用:
规则 1
指定构造器必须调用其直接父类的的指定构造器。
规则 2
便利构造器必须调用同类中定义的其它构造器。
规则 3
便利构造器最后必须调用指定构造器。
一个更方便记忆的方法是:
- 指定构造器必须总是向上代理
- 便利构造器必须总是横向代理
5.4 两段式构造过程
Swift 中类的构造过程包含两个阶段。第一个阶段,类中的每个存储型属性赋一个初始值。当每个存储型属性的初始值被赋值后,第二阶段开始,它给每个类一次机会,在新实例准备使用之前进一步定制它们的存储型属性。
两段式构造过程的使用让构造过程更安全,同时在整个类层级结构中给予了每个类完全的灵活性。两段式构造过程可以防止属性值在初始化之前被访问,也可以防止属性被另外一个构造器意外地赋予不同的值。
注意 Swift 的两段式构造过程跟 Objective-C 中的构造过程类似。最主要的区别在于阶段 1,Objective-C 给每一个属性赋值 0 或空值(比如说0或nil)。Swift 的构造流程则更加灵活,它允许你设置定制的初始值,并自如应对某些属性不能以 0 或 nil 作为合法默认值的情况。
Swift 编译器将执行 4 种有效的安全检查,以确保两段式构造过程不出错地完成:
安全检查 1
指定构造器必须保证它所在类的所有属性都必须先初始化完成,之后才能将其它构造任务向上代理给父类中的构造器。
如上所述,一个对象的内存只有在其所有存储型属性确定之后才能完全初始化。为了满足这一规则,指定构造器必须保证它所在类的属性在它往上代理之前先完成初始化。
安全检查 2
指定构造器必须在为继承的属性设置新值之前向上代理调用父类构造器,如果没这么做,指定构造器赋予的新值将被父类中的构造器所覆盖。
安全检查 3
便利构造器必须为任意属性(包括同类中定义的)赋新值之前代理调用同一类中的其它构造器,如果没这么做,便利构造器赋予的新值将被同一类中其它指定构造器所覆盖。
安全检查 4
构造器在第一阶段构造完成之前,不能调用任何实例方法,不能读取任何实例属性的值,不能引用self作为一个值。
类实例在第一阶段结束以前并不是完全有效的。只有第一阶段完成后,该实例才会成为有效实例,才能访问属性和调用方法。
以下是两段式构造过程中基于上述安全检查的构造流程展示:
阶段 1
- 某个指定构造器或便利构造器被调用。
- 完成新实例内存的分配,但此时内存还没有被初始化。
- 指定构造器确保其所在类引入的所有存储型属性都已赋初值。存储型属性所属的内存完成初始化。
- 指定构造器将调用父类的构造器,完成父类属性的初始化。
- 这个调用父类构造器的过程沿着构造器链一直往上执行,直到到达构造器链的最顶部。
- 当到达了构造器链最顶部,且已确保所有实例包含的存储型属性都已经赋值,这个实例的内存被认为已经完全初始化。此时阶段 1 完成。
阶段 2
- 从顶部构造器链一直往下,每个构造器链中类的指定构造器都有机会进一步定制实例。构造器此时可以访问 self、修改它的属性并调用实例方法等等。
- 最终,任意构造器链中的便利构造器可以有机会定制实例和使用 self。
5.5 构造器的继承和重写
跟 Objective-C 中的子类不同,Swift 中的子类默认情况下不会继承父类的构造器。Swift 的这种机制可以防止一个父类的简单构造器被一个更精细的子类继承,并被错误地用来创建子类的实例。
注意 父类的构造器仅会在安全和适当的情况下被继承。具体内容请参考后续章节构造器的自动继承。
假如你希望自定义的子类中能提供一个或多个跟父类相同的构造器,你可以在子类中提供这些构造器的自定义实现。
当你在编写一个和父类中指定构造器相匹配的子类构造器时,你实际上是在重写父类的这个指定构造器。因此,你必须在定义子类构造器时带上 override 修饰符。即使你重写的是系统自动提供的默认构造器,也需要带上 override 修饰符,具体内容请参考默认构造器。
正如重写属性,方法或者是下标,override 修饰符会让编译器去检查父类中是否有相匹配的指定构造器,并验证构造器参数是否正确。
注意 当你重写一个父类的指定构造器时,你总是需要写override修饰符,即使是为了实现子类的便利构造器。
相反,如果你编写了一个和父类便利构造器相匹配的子类构造器,由于子类不能直接调用父类的便利构造器(每个规则都在上文类的构造器代理规则有所描述),因此,严格意义上来讲,你的子类并未对一个父类构造器提供重写。最后的结果就是,你在子类中“重写”一个父类便利构造器时,不需要加 override 修饰符。
在下面的例子中定义了一个叫 Vehicle 的基类。基类中声明了一个存储型属性 numberOfWheels,它是默认值为 0 的 Int 类型的存储型属性。numberOfWheels 属性用于创建名为 descrpiption 的 String 类型的计算型属性:
class Vehicle {
var numberOfWheels = 0
var description: String {
return "\(numberOfWheels) wheel(s)"
}
}
Vehicle 类只为存储型属性提供默认值,也没有提供自定义构造器。因此,它会自动获得一个默认构造器,具体内容请参考默认构造器。自动获得的默认构造器总是类中的指定构造器,它可以用于创建numberOfWheels 为 0 的 Vehicle 实例:
let vehicle = Vehicle()
print("Vehicle: \(vehicle.description)")
// Vehicle: 0 wheel(s)
下面例子中定义了一个 Vehicle 的子类 Bicycle:
class Bicycle: Vehicle {
override init() {
super.init()
numberOfWheels = 2
}
}
子类 Bicycle 定义了一个自定义指定构造器 init()。这个指定构造器和父类的指定构造器相匹配,所以 Bicycle 中的指定构造器需要带上 override 修饰符。
Bicycle 的构造器 init() 以调用 super.init() 方法开始,这个方法的作用是调用 Bicycle 的父类Vehicle 的默认构造器。这样可以确保 Bicycle 在修改属性之前,它所继承的属性 numberOfWheels 能被 Vehicle 类初始化。在调用 super.init() 之后,属性 numberOfWheels 的原值被新值 2 替换。
如果你创建一个 Bicycle 实例,你可以调用继承的 description 计算型属性去查看属性 numberOfWheels 是否有改变:
let bicycle = Bicycle()
print("Bicycle: \(bicycle.description)")
// 打印 "Bicycle: 2 wheel(s)"
注意 子类可以在初始化时修改继承来的变量属性,但是不能修改继承来的常量属性。
5.6 构造器的自动继承
如上所述,子类在默认情况下不会继承父类的构造器。但是如果满足特定条件,父类构造器是可以被自动继承的。事实上,这意味着对于许多常见场景你不必重写父类的构造器,并且可以在安全的情况下以最小的代价继承父类的构造器。
假设你为子类中引入的所有新属性都提供了默认值,以下 2 个规则适用:
规则 1
如果子类没有定义任何指定构造器,它将自动继承父类所有的指定构造器。
规则 2
如果子类提供了所有父类指定构造器的实现——无论是通过规则 1 继承过来的,还是提供了自定义实现——它将自动继承父类所有的便利构造器。
即使你在子类中添加了更多的便利构造器,这两条规则仍然适用。
注意 对于规则 2,子类可以将父类的指定构造器实现为便利构造器。
5.7 指定构造器和便利构造器实践
接下来的例子将在实践中展示指定构造器、便利构造器以及构造器的自动继承。这个例子定义了包含三个类 Food、RecipeIngredient 以及 ShoppingListItem 的类层次结构,并将演示它们的构造器是如何相互作用的。
类层次中的基类是 Food,它是一个简单的用来封装食物名字的类。Food 类引入了一个叫做 name 的 String 类型的属性,并且提供了两个构造器来创建Food实例:
class Food {
var name: String
init(name: String) {
self.name = name
}
convenience init() {
self.init(name: "[Unnamed]")
}
}
类类型没有默认的逐一成员构造器,所以 Food 类提供了一个接受单一参数 name 的指定构造器。这个构造器可以使用一个特定的名字来创建新的 Food 实例:
let namedMeat = Food(name: "Bacon")
// namedMeat 的名字是 "Bacon"
Food 类中的构造器 init(name: String) 被定义为一个指定构造器,因为它能确保 Food 实例的所有存储型属性都被初始化。Food 类没有父类,所以 init(name: String) 构造器不需要调用 super.init() 来完成构造过程。
Food 类同样提供了一个没有参数的便利构造器 init()。这个 init() 构造器为新食物提供了一个默认的占位名字,通过横向代理到指定构造器 init(name: String) 并给参数 name 赋值为 [Unnamed] 来实现:
let mysteryMeat = Food()
// mysteryMeat 的名字是 [Unnamed]
类层级中的第二个类是 Food 的子类 RecipeIngredient。RecipeIngredient 类用来表示食谱中的一项原料。它引入了 Int 类型的属性 quantity(以及从 Food 继承过来的 name 属性),并且定义了两个构造器来创建RecipeIngredient 实例:
class RecipeIngredient: Food {
var quantity: Int
init(name: String, quantity: Int) {
self.quantity = quantity
super.init(name: name)
}
override convenience init(name: String) {
self.init(name: name, quantity: 1)
}
}
RecipeIngredient 类拥有一个指定构造器 init(name: String, quantity: Int),它可以用来填充RecipeIngredient 实例的所有属性值。这个构造器一开始先将传入的 quantity 参数赋值给 quantity 属性,这个属性也是唯一在 RecipeIngredient 中新引入的属性。随后,构造器向上代理到父类 Food 的init(name: String)。这个过程满足两段式构造过程中的安全检查 1。
RecipeIngredient 也定义了一个便利构造器 init(name: String),它只通过 name 来创建 RecipeIngredient 的实例。这个便利构造器假设任意 RecipeIngredient 实例的 quantity 为 1,所以不需要显式指明数量即可创建出实例。这个便利构造器的定义可以更加方便和快捷地创建实例,并且避免了创建多个quantity 为 1 的 RecipeIngredient 实例时的代码重复。这个便利构造器只是简单地横向代理到类中的指定构造器,并为 quantity 参数传递 1。
注意,RecipeIngredient 的便利构造器 init(name: String) 使用了跟 Food 中指定构造器 init(name: String) 相同的参数。由于这个便利构造器重写了父类的指定构造器 init(name: String),因此必须在前面使用 override 修饰符(参见构造器的继承和重写)。
尽管 RecipeIngredient 将父类的指定构造器重写为了便利构造器,但是它依然提供了父类的所有指定构造器的实现。因此,RecipeIngredient 会自动继承父类的所有便利构造器。
在这个例子中,RecipeIngredient 的父类是 Food,它有一个便利构造器 init()。这个便利构造器会被RecipeIngredient 继承。这个继承版本的 init() 在功能上跟 Food 提供的版本是一样的,只是它会代理到RecipeIngredient 版本的 init(name: String) 而不是 Food 提供的版本。
所有的这三种构造器都可以用来创建新的 RecipeIngredient实例:
let oneMysteryItem = RecipeIngredient()
let oneBacon = RecipeIngredient(name: "Bacon")
let sixEggs = RecipeIngredient(name: "Eggs", quantity: 6)
类层级中第三个也是最后一个类是 RecipeIngredient 的子类,叫做 ShoppingListItem。这个类构建了购物单中出现的某一种食谱原料。
购物单中的每一项总是从未购买状态开始的。为了呈现这一事实,ShoppingListItem 引入了一个 Boolean(布尔类型) 的属性 purchased,它的默认值是 false。ShoppingListItem 还添加了一个计算型属性 description,它提供了关于 ShoppingListItem 实例的一些文字描述:
class ShoppingListItem: RecipeIngredient {
var purchased = false
var description: String {
var output = "\(quantity) x \(name)"
output += purchased ? " ✔" : " ✘"
return output
}
}
注意 ShoppingListItem 没有定义构造器来为 purchased 提供初始值,因为添加到购物单的物品的初始状态总是未购买。
6 可失败构造器
如果一个类、结构体或枚举类型的对象,在构造过程中有可能失败,则为其定义一个可失败构造器是很有用的。这里所指的“失败” 指的是,如给构造器传入无效的参数值,或缺少某种所需的外部资源,又或是不满足某种必要的条件等。
为了妥善处理这种构造过程中可能会失败的情况。你可以在一个类,结构体或是枚举类型的定义中,添加一个或多个可失败构造器。其语法为在 init 关键字后面添加问号 (init?)。
注意 可失败构造器的参数名和参数类型,不能与其它非可失败构造器的参数名,及其参数类型相同。
可失败构造器会创建一个类型为自身类型的可选类型的对象。你通过 return nil 语句来表明可失败构造器在何种情况下应该 “失败”。
注意 严格来说,构造器都不支持返回值。因为构造器本身的作用,只是为了确保对象能被正确构造。因此你只是用return nil表明可失败构造器构造失败,而不要用关键字return来表明构造成功。
例如,实现针对数字类型转换的可失败构造器。确保数字类型之间的转换能保持精确的值,使用这个 init(exactly:) 构造器。如果类型转换不能保持值不变,则这个构造器构造失败。
let wholeNumber: Double = 12345.0
let pi = 3.14159
if let valueMaintained = Int(exactly: wholeNumber) {
print("\(wholeNumber) conversion to Int maintains value of \(valueMaintained)")
}
// 打印 "12345.0 conversion to Int maintains value of 12345"
let valueChanged = Int(exactly: pi)
// valueChanged 是 Int? 类型,不是 Int 类型
if valueChanged == nil {
print("\(pi) conversion to Int does not maintain value")
}
// 打印 "3.14159 conversion to Int does not maintain value"
下例中,定义了一个名为 Animal 的结构体,其中有一个名为 species 的 String 类型的常量属性。同时该结构体还定义了一个接受一个名为 species 的 String 类型参数的可失败构造器。这个可失败构造器检查传入的参数是否为一个空字符串。如果为空字符串,则构造失败。否则,species属性被赋值,构造成功。
struct Animal {
let species: String
init?(species: String) {
if species.isEmpty {
return nil
}
self.species = species
}
}
你可以通过该可失败构造器来尝试构建一个 Animal 的实例,并检查构造过程是否成功:
let someCreature = Animal(species: "Giraffe")
// someCreature 的类型是 Animal? 而不是 Animal
if let giraffe = someCreature {
print("An animal was initialized with a species of \(giraffe.species)")
}
// 打印 "An animal was initialized with a species of Giraffe"
如果你给该可失败构造器传入一个空字符串作为其参数,则会导致构造失败:
let anonymousCreature = Animal(species: "")
// anonymousCreature 的类型是 Animal?, 而不是 Animal
if anonymousCreature == nil {
print("The anonymous creature could not be initialized")
}
// 打印 "The anonymous creature could not be initialized"
注意 空字符串(如 ““,而不是 “Giraffe” )和一个值为 nil 的可选类型的字符串是两个完全不同的概念。上例中的空字符串(”“)其实是一个有效的,非可选类型的字符串。这里我们之所以让 Animal 的可失败构造器构造失败,只是因为对于 Animal 这个类的 species 属性来说,它更适合有一个具体的值,而不是空字符串。
6.1 枚举类型的可失败构造器
你可以通过一个带一个或多个参数的可失败构造器来获取枚举类型中特定的枚举成员。如果提供的参数无法匹配任何枚举成员,则构造失败。
下例中,定义了一个名为 TemperatureUnit 的枚举类型。其中包含了三个可能的枚举成员(Kelvin,Celsius,和Fahrenheit),以及一个根据 Character 值找出所对应的枚举成员的可失败构造器:
enum TemperatureUnit {
case Kelvin, Celsius, Fahrenheit
init?(symbol: Character) {
switch symbol {
case "K":
self = .Kelvin
case "C":
self = .Celsius
case "F":
self = .Fahrenheit
default:
return nil
}
}
}
你可以利用该可失败构造器在三个枚举成员中获取一个相匹配的枚举成员,当参数的值不能与任何枚举成员相匹配时,则构造失败:
let fahrenheitUnit = TemperatureUnit(symbol: "F")
if fahrenheitUnit != nil {
print("This is a defined temperature unit, so initialization succeeded.")
}
// 打印 "This is a defined temperature unit, so initialization succeeded."
let unknownUnit = TemperatureUnit(symbol: "X")
if unknownUnit == nil {
print("This is not a defined temperature unit, so initialization failed.")
}
// 打印 "This is not a defined temperature unit, so initialization failed."
6.2 带原始值的枚举类型的可失败构造器
带原始值的枚举类型会自带一个可失败构造器 init?(rawValue:),该可失败构造器有一个名为 rawValue 的参数,其类型和枚举类型的原始值类型一致,如果该参数的值能够和某个枚举成员的原始值匹配,则该构造器会构造相应的枚举成员,否则构造失败。
因此上面的 TemperatureUnit 的例子可以重写为:
enum TemperatureUnit: Character {
case Kelvin = "K", Celsius = "C", Fahrenheit = "F"
}
let fahrenheitUnit = TemperatureUnit(rawValue: "F")
if fahrenheitUnit != nil {
print("This is a defined temperature unit, so initialization succeeded.")
}
// 打印 "This is a defined temperature unit, so initialization succeeded."
let unknownUnit = TemperatureUnit(rawValue: "X")
if unknownUnit == nil {
print("This is not a defined temperature unit, so initialization failed.")
}
// 打印 "This is not a defined temperature unit, so initialization failed."
6.3 构造失败的传递
类,结构体,枚举的可失败构造器可以横向代理到同类型中的其他可失败构造器。类似的,子类的可失败构造器也能向上代理到父类的可失败构造器。
无论是向上代理还是横向代理,如果你代理到的其他可失败构造器触发构造失败,整个构造过程将立即终止,接下来的任何构造代码不会再被执行。
注意 可失败构造器也可以代理到其它的非可失败构造器。通过这种方式,你可以增加一个可能的失败状态到现有的构造过程中。
下面这个例子,定义了一个名为CartItem的Product类的子类。这个类建立了一个在线购物车中的物品的模型,它有一个名为quantity的常量存储型属性,并确保该属性的值至少为1:
class Product {
let name: String
init?(name: String) {
if name.isEmpty { return nil }
self.name = name
}
}
class CartItem: Product {
let quantity: Int
init?(name: String, quantity: Int) {
if quantity < 1 { return nil }
self.quantity = quantity
super.init(name: name)
}
}
CartItem 可失败构造器首先验证接收的 quantity 值是否大于等于 1 。倘若 quantity 值无效,则立即终止整个构造过程,返回失败结果,且不再执行余下代码。同样地,Product 的可失败构造器首先检查 name 值,假如 name 值为空字符串,则构造器立即执行失败。
如果你通过传入一个非空字符串 name 以及一个值大于等于 1 的 quantity 来创建一个 CartItem 实例,那么构造方法能够成功被执行:
if let twoSocks = CartItem(name: "sock", quantity: 2) {
print("Item: \(twoSocks.name), quantity: \(twoSocks.quantity)")
}
// 打印 "Item: sock, quantity: 2"
倘若你以一个值为 0 的 quantity 来创建一个 CartItem 实例,那么将导致 CartItem 构造器失败:
if let zeroShirts = CartItem(name: "shirt", quantity: 0) {
print("Item: \(zeroShirts.name), quantity: \(zeroShirts.quantity)")
} else {
print("Unable to initialize zero shirts")
}
// 打印 "Unable to initialize zero shirts"
同样地,如果你尝试传入一个值为空字符串的 name 来创建一个 CartItem 实例,那么将导致父类 Product 的构造过程失败:
if let oneUnnamed = CartItem(name: "", quantity: 1) {
print("Item: \(oneUnnamed.name), quantity: \(oneUnnamed.quantity)")
} else {
print("Unable to initialize one unnamed product")
}
// 打印 "Unable to initialize one unnamed product"
6.4 重写一个可失败构造器
如同其它的构造器,你可以在子类中重写父类的可失败构造器。或者你也可以用子类的非可失败构造器重写一个父类的可失败构造器。这使你可以定义一个不会构造失败的子类,即使父类的构造器允许构造失败。
注意,当你用子类的非可失败构造器重写父类的可失败构造器时,向上代理到父类的可失败构造器的唯一方式是对父类的可失败构造器的返回值进行强制解包。
注意 你可以用非可失败构造器重写可失败构造器,但反过来却不行。
下例定义了一个名为 Document 的类,name 属性的值必须为一个非空字符串或 nil,但不能是一个空字符串:
class Document {
var name: String?
// 该构造器创建了一个 name 属性的值为 nil 的 document 实例
init() {}
// 该构造器创建了一个 name 属性的值为非空字符串的 document 实例
init?(name: String) {
self.name = name
if name.isEmpty { return nil }
}
}
下面这个例子,定义了一个 Document 类的子类 AutomaticallyNamedDocument。这个子类重写了父类的两个指定构造器,确保了无论是使用 init() 构造器,还是使用 init(name:) 构造器并为参数传递空字符串,生成的实例中的 name 属性总有初始”[Untitled]”:
class AutomaticallyNamedDocument: Document {
override init() {
super.init()
self.name = "[Untitled]"
}
override init(name: String) {
super.init()
if name.isEmpty {
self.name = "[Untitled]"
} else {
self.name = name
}
}
}
AutomaticallyNamedDocument 用一个非可失败构造器 init(name:) 重写了父类的可失败构造器 init?(name:)。因为子类用另一种方式处理了空字符串的情况,所以不再需要一个可失败构造器,因此子类用一个非可失败构造器代替了父类的可失败构造器。
你可以在子类的非可失败构造器中使用强制解包来调用父类的可失败构造器。比如,下面的 UntitledDocument 子类的 name 属性的值总是 “[Untitled]”,它在构造过程中使用了父类的可失败构造器 init?(name:):
class UntitledDocument: Document {
override init() {
super.init(name: "[Untitled]")!
}
}
在这个例子中,如果在调用父类的可失败构造器 init?(name:) 时传入的是空字符串,那么强制解包操作会引发运行时错误。不过,因为这里是通过非空的字符串常量来调用它,所以并不会发生运行时错误。
6.5 可失败构造器 init!
通常来说我们通过在init关键字后添加问号的方式(init?)来定义一个可失败构造器,但你也可以通过在init后面添加惊叹号的方式来定义一个可失败构造器(init!),该可失败构造器将会构建一个对应类型的隐式解包可选类型的对象。
你可以在 init? 中代理到 init!,反之亦然。你也可以用 init? 重写 init!,反之亦然。你还可以用init 代理到 init!,不过,一旦 init! 构造失败,则会触发一个断言。
7 必要构造器
在类的构造器前添加 required 修饰符表明所有该类的子类都必须实现该构造器:
class SomeClass {
required init() {
// 构造器的实现代码
}
}
在子类重写父类的必要构造器时,必须在子类的构造器前也添加 required 修饰符,表明该构造器要求也应用于继承链后面的子类。在重写父类中必要的指定构造器时,不需要添加 override 修饰符:
class SomeSubclass: SomeClass {
required init() {
// 构造器的实现代码
}
}
注意 如果子类继承的构造器能满足必要构造器的要求,则无须在子类中显式提供必要构造器的实现。
8 通过闭包或函数设置属性的默认值
如果某个存储型属性的默认值需要一些定制或设置,你可以使用闭包或全局函数为其提供定制的默认值。每当某个属性所在类型的新实例被创建时,对应的闭包或函数会被调用,而它们的返回值会当做默认值赋值给这个属性。
这种类型的闭包或函数通常会创建一个跟属性类型相同的临时变量,然后修改它的值以满足预期的初始状态,最后返回这个临时变量,作为属性的默认值。
下面模板介绍了如何用闭包为属性提供默认值:
class SomeClass {
let someProperty: SomeType = {
// 在这个闭包中给 someProperty 创建一个默认值
// someValue 必须和 SomeType 类型相同
return someValue
}()
}
注意闭包结尾的花括号后面接了一对空的小括号。这用来告诉 Swift 立即执行此闭包。如果你忽略了这对括号,相当于将闭包本身作为值赋值给了属性,而不是将闭包的返回值赋值给属性。
注意 如果你使用闭包来初始化属性,请记住在闭包执行时,实例的其它部分都还没有初始化。这意味着你不能在闭包里访问其它属性,即使这些属性有默认值。同样,你也不能使用隐式的 self 属性,或者调用任何实例方法。
下面例子中定义了一个结构体 Chessboard,它构建了西洋跳棋游戏的棋盘,西洋跳棋游戏在一副黑白格交替的 8 x 8 的棋盘中进行的:
为了呈现这副游戏棋盘,Chessboard结构体定义了一个属性 boardColors,它是一个包含 64 个 Bool值的数组。在数组中,值为 true 的元素表示一个黑格,值为 false 的元素表示一个白格。数组中第一个元素代表棋盘上左上角的格子,最后一个元素代表棋盘上右下角的格子。
boardColors 数组是通过一个闭包来初始化并设置颜色值的:
struct Chessboard {
let boardColors: [Bool] = {
var temporaryBoard = [Bool]()
var isBlack = false
for i in 1...8 {
for j in 1...8 {
temporaryBoard.append(isBlack)
isBlack = !isBlack
}
isBlack = !isBlack
}
return temporaryBoard
}()
func squareIsBlackAt(row: Int, column: Int) -> Bool {
return boardColors[(row * 8) + column]
}
}
每当一个新的 Chessboard 实例被创建时,赋值闭包则会被执行,boardColors 的默认值会被计算出来并返回。上面例子中描述的闭包将计算出棋盘中每个格子对应的颜色,并将这些值保存到一个临时数组 temporaryBoard 中,最后在构建完成时将此数组作为闭包返回值返回。这个返回的数组会保存到 boardColors 中,并可以通过工具函数squareIsBlackAtRow来查询:
let board = Chessboard()
print(board.squareIsBlackAt(row: 0, column: 1))
// Prints "true"
print(board.squareIsBlackAt(row: 7, column: 7))
// Prints "false”
析构过程
析构器只适用于类类型,当一个类的实例被释放之前,析构器会被立即调用。析构器用关键字deinit来标示,类似于构造器要用init来标示。
1 析构过程原理
Swift 会自动释放不再需要的实例以释放资源。如自动引用计数章节中所讲述,Swift 通过自动引用计数(ARC)处理实例的内存管理。通常当你的实例被释放时不需要手动地去清理。但是,当使用自己的资源时,你可能需要进行一些额外的清理。例如,如果创建了一个自定义的类来打开一个文件,并写入一些数据,你可能需要在类实例被释放之前手动去关闭该文件。
在类的定义中,每个类最多只能有一个析构器,而且析构器不带任何参数,如下所示:
deinit {
// 执行析构过程
}
析构器是在实例释放发生前被自动调用。你不能主动调用析构器。子类继承了父类的析构器,并且在子类析构器实现的最后,父类的析构器会被自动调用。即使子类没有提供自己的析构器,父类的析构器也同样会被调用。
因为直到实例的析构器被调用后,实例才会被释放,所以析构器可以访问实例的所有属性,并且可以根据那些属性可以修改它的行为(比如查找一个需要被关闭的文件)。
2 析构器实践
这是一个析构器实践的例子。这个例子描述了一个简单的游戏,这里定义了两种新类型,分别是Bank和Player。Bank类管理一种虚拟硬币,确保流通的硬币数量永远不可能超过 10,000。在游戏中有且只能有一个Bank存在,因此Bank用类来实现,并使用类型属性和类型方法来存储和管理其当前状态。
class Bank {
static var coinsInBank = 10_000
static func distribute(coins numberOfCoinsRequested: Int) -> Int {
let numberOfCoinsToVend = min(numberOfCoinsRequested, coinsInBank)
coinsInBank -= numberOfCoinsToVend
return numberOfCoinsToVend
}
static func receive(coins: Int) {
coinsInBank += coins
}
}
Bank使用coinsInBank属性来跟踪它当前拥有的硬币数量。Bank还提供了两个方法,distribute(coins:)和receive(coins:),分别用来处理硬币的分发和收集。
distribute(coins:)方法在Bank对象分发硬币之前检查是否有足够的硬币。如果硬币不足,Bank对象会返回一个比请求时小的数字(如果Bank对象中没有硬币了就返回0)。此方法返回一个整型值,表示提供的硬币的实际数量。
receive(coins:)方法只是将Bank实例接收到的硬币数目加回硬币存储中。
Player类描述了游戏中的一个玩家。每一个玩家在任意时间都有一定数量的硬币存储在他们的钱包中。这通过玩家的coinsInPurse属性来表示:
class Player {
var coinsInPurse: Int
init(coins: Int) {
coinsInPurse = Bank.distribute(coins: coins)
}
func win(coins: Int) {
coinsInPurse += Bank.distribute(coins: coins)
}
deinit {
Bank.receive(coins: coinsInPurse)
}
}
每个Player实例在初始化的过程中,都从Bank对象获取指定数量的硬币。如果没有足够的硬币可用,Player实例可能会收到比指定数量少的硬币。
Player类定义了一个win(coins:)方法,该方法从Bank对象获取一定数量的硬币,并把它们添加到玩家的钱包。Player类还实现了一个析构器,这个析构器在Player实例释放前被调用。在这里,析构器的作用只是将玩家的所有硬币都返还给Bank对象:
var playerOne: Player? = Player(coins: 100)
print("A new player has joined the game with \(playerOne!.coinsInPurse) coins")
// 打印 "A new player has joined the game with 100 coins"
print("There are now \(Bank.coinsInBank) coins left in the bank")
// 打印 "There are now 9900 coins left in the bank"
创建一个Player实例的时候,会向Bank对象请求 100 个硬币,如果有足够的硬币可用的话。这个Player实例存储在一个名为playerOne的可选类型的变量中。这里使用了一个可选类型的变量,因为玩家可以随时离开游戏,设置为可选使你可以追踪玩家当前是否在游戏中。
因为playerOne是可选的,所以访问其coinsInPurse属性来打印钱包中的硬币数量时,使用感叹号(!)强制解包:
playerOne!.win(coins: 2_000)
print("PlayerOne won 2000 coins & now has \(playerOne!.coinsInPurse) coins")
// 输出 "PlayerOne won 2000 coins & now has 2100 coins"
print("The bank now only has \(Bank.coinsInBank) coins left")
// 输出 "The bank now only has 7900 coins left"
这里,玩家已经赢得了 2,000 枚硬币,所以玩家的钱包中现在有 2,100 枚硬币,而Bank对象只剩余 7,900 枚硬币。
playerOne = nil
print("PlayerOne has left the game")
// 打印 "PlayerOne has left the game"
print("The bank now has \(Bank.coinsInBank) coins")
// 打印 "The bank now has 10000 coins"
玩家现在已经离开了游戏。这通过将可选类型的playerOne变量设置为nil来表示,意味着“没有Player实例”。当这一切发生时,playerOne变量对Player实例的引用被破坏了。没有其它属性或者变量引用Player实例,因此该实例会被释放,以便回收内存。在这之前,该实例的析构器被自动调用,玩家的硬币被返还给银行。
自动引用计数
Swift 使用自动引用计数(ARC)机制来跟踪和管理你的应用程序的内存。通常情况下,Swift 内存管理机制会一直起作用,你无须自己来考虑内存的管理。ARC 会在类的实例不再被使用时,自动释放其占用的内存。
然而在少数情况下,为了能帮助你管理内存,ARC 需要更多的,代码之间关系的信息。本章描述了这些情况,并且为你示范怎样才能使 ARC 来管理你的应用程序的所有内存。在 Swift 使用 ARC 与在 Obejctive-C 中使用 ARC 非常类似。
注意 引用计数仅仅应用于类的实例。结构体和枚举类型是值类型,不是引用类型,也不是通过引用的方式存储和传递。
1 自动引用计数的工作机制
当你每次创建一个类的新的实例的时候,ARC 会分配一块内存来储存该实例信息。内存中会包含实例的类型信息,以及这个实例所有相关的存储型属性的值。
此外,当实例不再被使用时,ARC 释放实例所占用的内存,并让释放的内存能挪作他用。这确保了不再被使用的实例,不会一直占用内存空间。
然而,当 ARC 收回和释放了正在被使用中的实例,该实例的属性和方法将不能再被访问和调用。实际上,如果你试图访问这个实例,你的应用程序很可能会崩溃。
为了确保使用中的实例不会被销毁,ARC 会跟踪和计算每一个实例正在被多少属性,常量和变量所引用。哪怕实例的引用数为1,ARC都不会销毁这个实例。
为了使上述成为可能,无论你将实例赋值给属性、常量或变量,它们都会创建此实例的强引用。之所以称之为“强”引用,是因为它会将实例牢牢地保持住,只要强引用还在,实例是不允许被销毁的。
2 自动引用计数实践
下面的例子展示了自动引用计数的工作机制。例子以一个简单的Person类开始,并定义了一个叫name的常量属性:
class Person {
let name: String
init(name: String) {
self.name = name
print("\(name) is being initialized")
}
deinit {
print("\(name) is being deinitialized")
}
}
Person类有一个构造函数,此构造函数为实例的name属性赋值,并打印一条消息以表明初始化过程生效。Person类也拥有一个析构函数,这个析构函数会在实例被销毁时打印一条消息。
接下来的代码片段定义了三个类型为Person?的变量,用来按照代码片段中的顺序,为新的Person实例建立多个引用。由于这些变量是被定义为可选类型(Person?,而不是Person),它们的值会被自动初始化为nil,目前还不会引用到Person类的实例。
var reference1: Person?
var reference2: Person?
var reference3: Person?
现在你可以创建Person类的新实例,并且将它赋值给三个变量中的一个:
reference1 = Person(name: "John Appleseed")
// 打印 "John Appleseed is being initialized"
应当注意到当你调用Person类的构造函数的时候,”John Appleseed is being initialized”会被打印出来。由此可以确定构造函数被执行。
由于Person类的新实例被赋值给了reference1变量,所以reference1到Person类的新实例之间建立了一个强引用。正是因为这一个强引用,ARC 会保证Person实例被保持在内存中不被销毁。
如果你将同一个Person实例也赋值给其他两个变量,该实例又会多出两个强引用:
reference2 = reference1
reference3 = reference1
现在这一个Person实例已经有三个强引用了。
如果你通过给其中两个变量赋值nil的方式断开两个强引用(包括最先的那个强引用),只留下一个强引用,Person实例不会被销毁:
reference1 = nil
reference2 = nil
在你清楚地表明不再使用这个Person实例时,即第三个也就是最后一个强引用被断开时,ARC 会销毁它:
reference3 = nil
// 打印 "John Appleseed is being deinitialized"
3 类实例之间的循环强引用
在上面的例子中,ARC 会跟踪你所新创建的Person实例的引用数量,并且会在Person实例不再被需要时销毁它。
然而,我们可能会写出一个类实例的强引用数永远不能变成0的代码。如果两个类实例互相持有对方的强引用,因而每个实例都让对方一直存在,就是这种情况。这就是所谓的循环强引用。
你可以通过定义类之间的关系为弱引用或无主引用,以替代强引用,从而解决循环强引用的问题。具体的过程在解决类实例之间的循环强引用中有描述。不管怎样,在你学习怎样解决循环强引用之前,很有必要了解一下它是怎样产生的。
下面展示了一个不经意产生循环强引用的例子。例子定义了两个类:Person和Apartment,用来建模公寓和它其中的居民:
class Person {
let name: String
init(name: String) { self.name = name }
var apartment: Apartment?
deinit { print("\(name) is being deinitialized") }
}
class Apartment {
let unit: String
init(unit: String) { self.unit = unit }
var tenant: Person?
deinit { print("Apartment \(unit) is being deinitialized") }
}
每一个Person实例有一个类型为String,名字为name的属性,并有一个可选的初始化为nil的apartment属性。apartment属性是可选的,因为一个人并不总是拥有公寓。
类似的,每个Apartment实例有一个叫unit,类型为String的属性,并有一个可选的初始化为nil的tenant属性。tenant属性是可选的,因为一栋公寓并不总是有居民。
这两个类都定义了析构函数,用以在类实例被析构的时候输出信息。这让你能够知晓Person和Apartment的实例是否像预期的那样被销毁。
接下来的代码片段定义了两个可选类型的变量john和unit4A,并分别被设定为下面的Apartment和Person的实例。这两个变量都被初始化为nil,这正是可选类型的优点:
var john: Person?
var unit4A: Apartment?
现在你可以创建特定的Person和Apartment实例并将赋值给john和unit4A变量:
john = Person(name: "John Appleseed")
unit4A = Apartment(unit: "4A")
在两个实例被创建和赋值后,下图表现了强引用的关系。变量john现在有一个指向Person实例的强引用,而变量unit4A有一个指向Apartment实例的强引用:
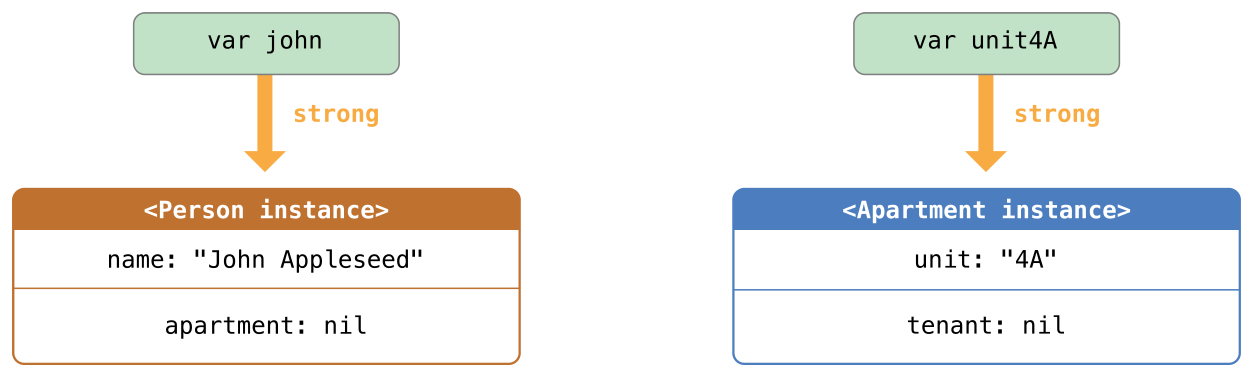
现在你能够将这两个实例关联在一起,这样人就能有公寓住了,而公寓也有了房客。注意感叹号是用来展开和访问可选变量john和unit4A中的实例,这样实例的属性才能被赋值:
john!.apartment = unit4A
unit4A!.tenant = john
在将两个实例联系在一起之后,强引用的关系如图所示:
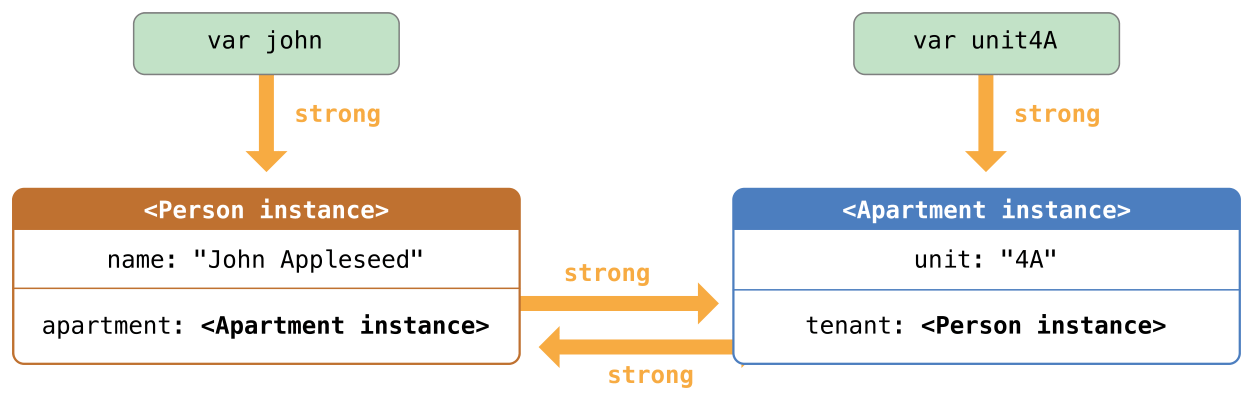
不幸的是,这两个实例关联后会产生一个循环强引用。Person实例现在有了一个指向Apartment实例的强引用,而Apartment实例也有了一个指向Person实例的强引用。因此,当你断开john和unit4A变量所持有的强引用时,引用计数并不会降为0,实例也不会被 ARC 销毁:
john = nil
unit4A = nil
注意,当你把这两个变量设为nil时,没有任何一个析构函数被调用。循环强引用会一直阻止Person和Apartment类实例的销毁,这就在你的应用程序中造成了内存泄漏。
在你将john和unit4A赋值为nil后,强引用关系如下图:
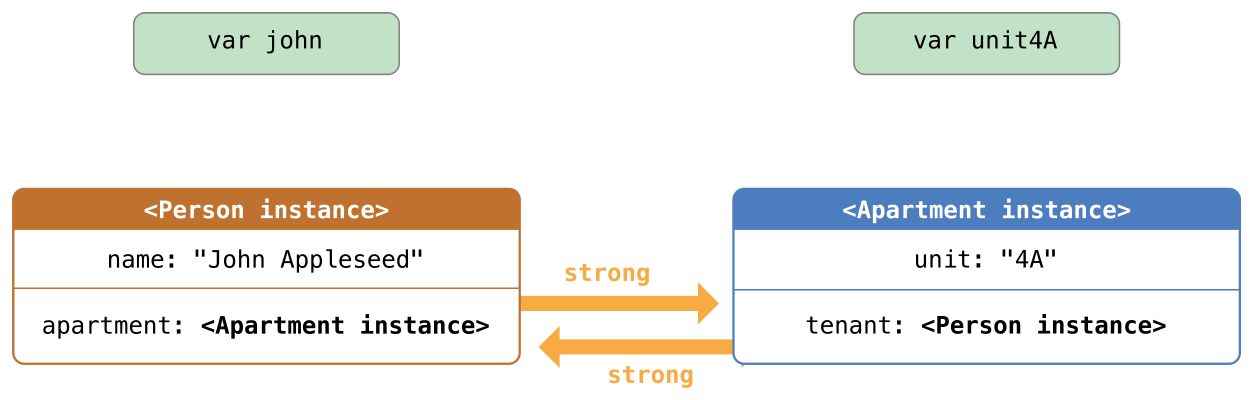
Person和Apartment实例之间的强引用关系保留了下来并且不会被断开。
4 解决实例之间的循环强引用
Swift 提供了两种办法用来解决你在使用类的属性时所遇到的循环强引用问题:弱引用(weak reference)和无主引用(unowned reference)。
弱引用和无主引用允许循环引用中的一个实例引用而另外一个实例不保持强引用。这样实例能够互相引用而不产生循环强引用。
当其他的实例有更短的生命周期时,使用弱引用,也就是说,当其他实例析构在先时。在上面公寓的例子中,很显然一个公寓在它的生命周期内会在某个时间段没有它的主人,所以一个弱引用就加在公寓类里面,避免循环引用。相比之下,当其他实例有相同的或者更长生命周期时,请使用无主引用。
4.1 弱引用
弱引用不会对其引用的实例保持强引用,因而不会阻止 ARC 销毁被引用的实例。这个特性阻止了引用变为循环强引用。声明属性或者变量时,在前面加上weak关键字表明这是一个弱引用。
因为弱引用不会保持所引用的实例,即使引用存在,实例也有可能被销毁。因此,ARC 会在引用的实例被销毁后自动将其赋值为nil。并且因为弱引用可以允许它们的值在运行时被赋值为nil,所以它们会被定义为可选类型变量,而不是常量。
你可以像其他可选值一样,检查弱引用的值是否存在,你将永远不会访问已销毁的实例的引用。
注意 当 ARC 设置弱引用为nil时,属性观察不会被触发。
下面的例子跟上面Person和Apartment的例子一致,但是有一个重要的区别。这一次,Apartment的tenant属性被声明为弱引用:
class Person {
let name: String
init(name: String) { self.name = name }
var apartment: Apartment?
deinit { print("\(name) is being deinitialized") }
}
class Apartment {
let unit: String
init(unit: String) { self.unit = unit }
weak var tenant: Person?
deinit { print("Apartment \(unit) is being deinitialized") }
}
然后跟之前一样,建立两个变量(john和unit4A)之间的强引用,并关联两个实例:
var john: Person?
var unit4A: Apartment?
john = Person(name: "John Appleseed")
unit4A = Apartment(unit: "4A")
john!.apartment = unit4A
unit4A!.tenant = john
现在,两个关联在一起的实例的引用关系如下图所示:
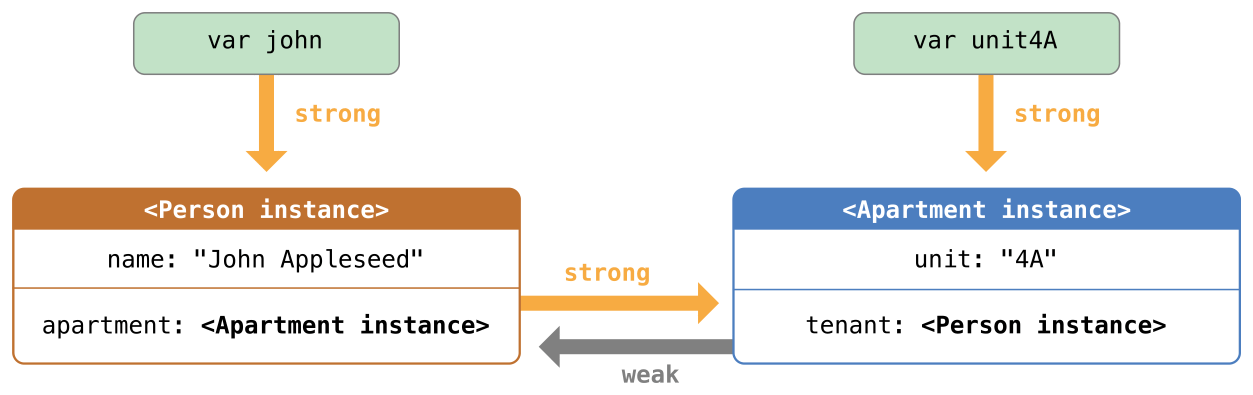
Person实例依然保持对Apartment实例的强引用,但是Apartment实例只持有对Person实例的弱引用。这意味着当你断开john变量所保持的强引用时,再也没有指向Person实例的强引用了:
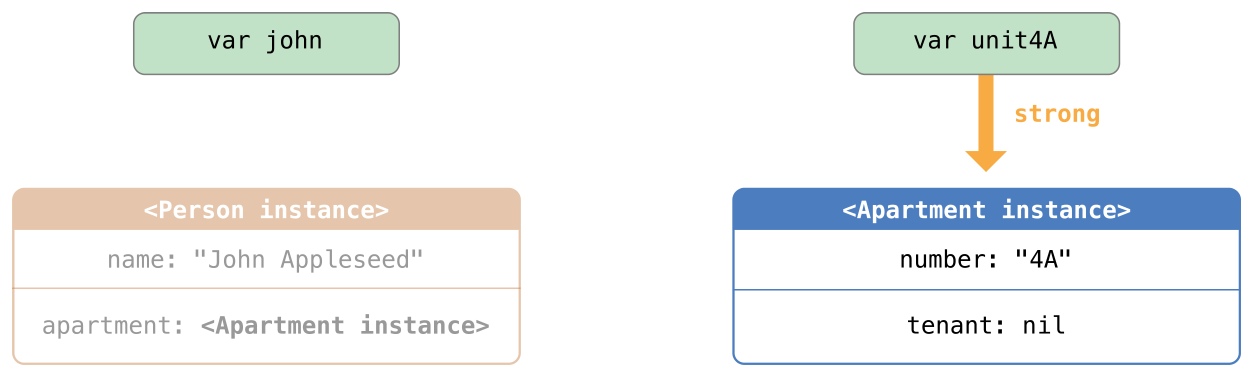
由于再也没有指向Person实例的强引用,该实例会被销毁:
john = nil
// 打印 "John Appleseed is being deinitialized"
唯一剩下的指向Apartment实例的强引用来自于变量unit4A。如果你断开这个强引用,再也没有指向Apartment实例的强引用了:
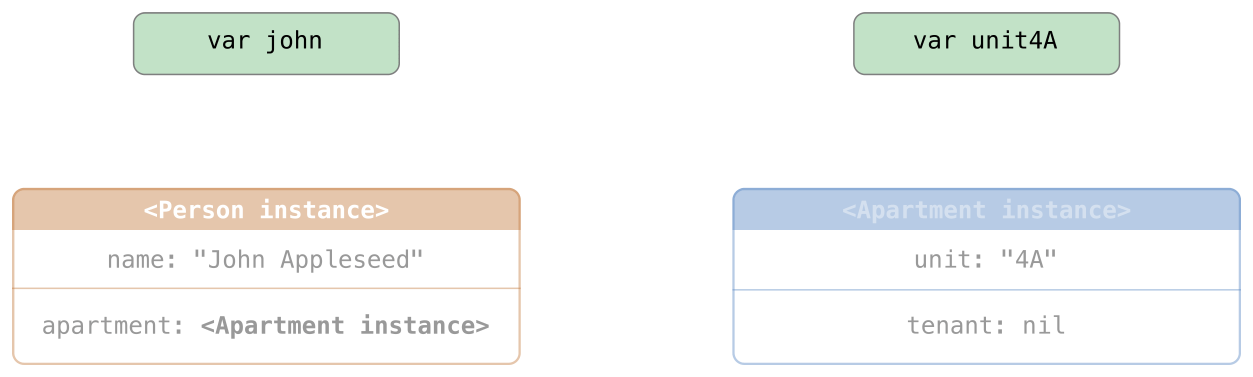
由于再也没有指向Apartment实例的强引用,该实例也会被销毁:
unit4A = nil
// 打印 "Apartment 4A is being deinitialized"
上面的两段代码展示了变量john和unit4A在被赋值为nil后,Person实例和Apartment实例的析构函数都打印出“销毁”的信息。这证明了引用循环被打破了。
注意 在使用垃圾收集的系统里,弱指针有时用来实现简单的缓冲机制,因为没有强引用的对象只会在内存压力触发垃圾收集时才被销毁。但是在 ARC 中,一旦值的最后一个强引用被移除,就会被立即销毁,这导致弱引用并不适合上面的用途。
4.2 无主引用
和弱引用类似,无主引用不会牢牢保持住引用的实例。和弱引用不同的是,无主引用在其他实例有相同或者更长的生命周期时使用。你可以在声明属性或者变量时,在前面加上关键字unowned表示这是一个无主引用。
无主引用通常都被期望拥有值。不过 ARC 无法在实例被销毁后将无主引用设为nil,因为非可选类型的变量不允许被赋值为nil。
重要 使用无主引用,你必须确保引用始终指向一个未销毁的实例。 如果你试图在实例被销毁后,访问该实例的无主引用,会触发运行时错误。
下面的例子定义了两个类,Customer和CreditCard,模拟了银行客户和客户的信用卡。这两个类中,每一个都将另外一个类的实例作为自身的属性。这种关系可能会造成循环强引用。
Customer和CreditCard之间的关系与前面弱引用例子中Apartment和Person的关系略微不同。在这个数据模型中,一个客户可能有或者没有信用卡,但是一张信用卡总是关联着一个客户。为了表示这种关系,Customer类有一个可选类型的card属性,但是CreditCard类有一个非可选类型的customer属性。
此外,只能通过将一个number值和customer实例传递给CreditCard构造函数的方式来创建CreditCard实例。这样可以确保当创建CreditCard实例时总是有一个customer实例与之关联。
由于信用卡总是关联着一个客户,因此将customer属性定义为无主引用,用以避免循环强引用:
class Customer {
let name: String
var card: CreditCard?
init(name: String) {
self.name = name
}
deinit { print("\(name) is being deinitialized") }
}
class CreditCard {
let number: UInt64
unowned let customer: Customer
init(number: UInt64, customer: Customer) {
self.number = number
self.customer = customer
}
deinit { print("Card #\(number) is being deinitialized") }
}
注意 CreditCard类的number属性被定义为UInt64类型而不是Int类型,以确保number属性的存储量在 32 位和 64 位系统上都能足够容纳 16 位的卡号。
下面的代码片段定义了一个叫john的可选类型Customer变量,用来保存某个特定客户的引用。由于是可选类型,所以变量被初始化为nil:
var john: Customer?
现在你可以创建Customer类的实例,用它初始化CreditCard实例,并将新创建的CreditCard实例赋值为客户的card属性:
john = Customer(name: "John Appleseed")
john!.card = CreditCard(number: 1234_5678_9012_3456, customer: john!)
在你关联两个实例后,它们的引用关系如下图所示:
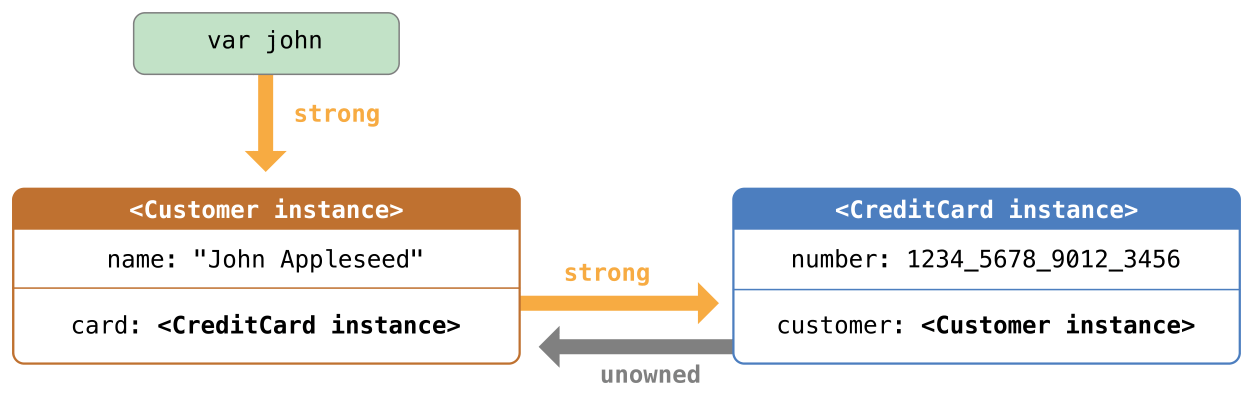
Customer实例持有对CreditCard实例的强引用,而CreditCard实例持有对Customer实例的无主引用。
由于customer的无主引用,当你断开john变量持有的强引用时,再也没有指向Customer实例的强引用了:
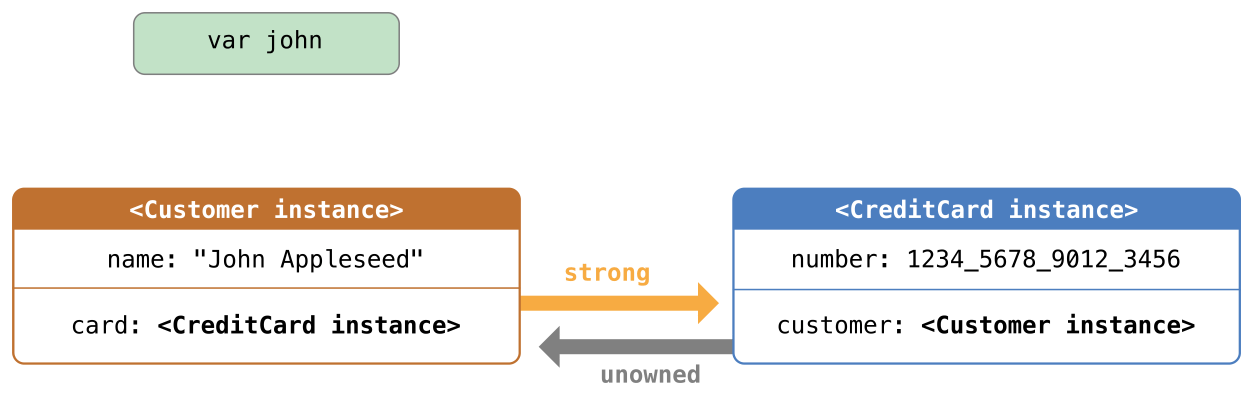
由于再也没有指向Customer实例的强引用,该实例被销毁了。其后,再也没有指向CreditCard实例的强引用,该实例也随之被销毁了:
john = nil
// 打印 "John Appleseed is being deinitialized"
// 打印 "Card #1234567890123456 is being deinitialized"
最后的代码展示了在john变量被设为nil后Customer实例和CreditCard实例的构造函数都打印出了“销毁”的信息。
注意 上面的例子展示了如何使用安全的无主引用。对于需要禁用运行时的安全检查的情况(例如,出于性能方面的原因),Swift还提供了不安全的无主引用。与所有不安全的操作一样,你需要负责检查代码以确保其安全性。 你可以通过unowned(unsafe)来声明不安全无主引用。如果你试图在实例被销毁后,访问该实例的不安全无主引用,你的程序会尝试访问该实例之前所在的内存地址,这是一个不安全的操作。
4.3 无主引用以及隐式解析可选属性
上面弱引用和无主引用的例子涵盖了两种常用的需要打破循环强引用的场景。
Person和Apartment的例子展示了两个属性的值都允许为nil,并会潜在的产生循环强引用。这种场景最适合用弱引用来解决。
Customer和CreditCard的例子展示了一个属性的值允许为nil,而另一个属性的值不允许为nil,这也可能会产生循环强引用。这种场景最适合通过无主引用来解决。
然而,存在着第三种场景,在这种场景中,两个属性都必须有值,并且初始化完成后永远不会为nil。在这种场景中,需要一个类使用无主属性,而另外一个类使用隐式解析可选属性。
这使两个属性在初始化完成后能被直接访问(不需要可选展开),同时避免了循环引用。这一节将为你展示如何建立这种关系。
下面的例子定义了两个类,Country和City,每个类将另外一个类的实例保存为属性。在这个模型中,每个国家必须有首都,每个城市必须属于一个国家。为了实现这种关系,Country类拥有一个capitalCity属性,而City类有一个country属性:
class Country {
let name: String
var capitalCity: City!
init(name: String, capitalName: String) {
self.name = name
self.capitalCity = City(name: capitalName, country: self)
}
}
class City {
let name: String
unowned let country: Country
init(name: String, country: Country) {
self.name = name
self.country = country
}
}
为了建立两个类的依赖关系,City的构造函数接受一个Country实例作为参数,并且将实例保存到country属性。
Country的构造函数调用了City的构造函数。然而,只有Country的实例完全初始化后,Country的构造函数才能把self传给City的构造函数。在两段式构造过程中有具体描述。
为了满足这种需求,通过在类型结尾处加上感叹号(City!)的方式,将Country的capitalCity属性声明为隐式解析可选类型的属性。这意味着像其他可选类型一样,capitalCity属性的默认值为nil,但是不需要展开它的值就能访问它。在隐式解析可选类型中有描述。
由于capitalCity默认值为nil,一旦Country的实例在构造函数中给name属性赋值后,整个初始化过程就完成了。这意味着一旦name属性被赋值后,Country的构造函数就能引用并传递隐式的self。Country的构造函数在赋值capitalCity时,就能将self作为参数传递给City的构造函数。
以上的意义在于你可以通过一条语句同时创建Country和City的实例,而不产生循环强引用,并且capitalCity的属性能被直接访问,而不需要通过感叹号来展开它的可选值:
var country = Country(name: "Canada", capitalName: "Ottawa")
print("\(country.name)'s capital city is called \(country.capitalCity.name)")
// 打印 "Canada's capital city is called Ottawa"
在上面的例子中,使用隐式解析可选值意味着满足了类的构造函数的两个构造阶段的要求。capitalCity属性在初始化完成后,能像非可选值一样使用和存取,同时还避免了循环强引用。
5 闭包引起的循环强引用
前面我们看到了循环强引用是在两个类实例属性互相保持对方的强引用时产生的,还知道了如何用弱引用和无主引用来打破这些循环强引用。
循环强引用还会发生在当你将一个闭包赋值给类实例的某个属性,并且这个闭包体中又使用了这个类实例时。这个闭包体中可能访问了实例的某个属性,例如self.someProperty,或者闭包中调用了实例的某个方法,例如self.someMethod()。这两种情况都导致了闭包“捕获”self,从而产生了循环强引用。
循环强引用的产生,是因为闭包和类相似,都是引用类型。当你把一个闭包赋值给某个属性时,你是将这个闭包的引用赋值给了属性。实质上,这跟之前的问题是一样的——两个强引用让彼此一直有效。但是,和两个类实例不同,这次一个是类实例,另一个是闭包。
Swift 提供了一种优雅的方法来解决这个问题,称之为闭包捕获列表(closure capture list)。同样的,在学习如何用闭包捕获列表打破循环强引用之前,先来了解一下这里的循环强引用是如何产生的,这对我们很有帮助。
下面的例子为你展示了当一个闭包引用了self后是如何产生一个循环强引用的。例子中定义了一个叫HTMLElement的类,用一种简单的模型表示 HTML 文档中的一个单独的元素:
class HTMLElement {
let name: String
let text: String?
lazy var asHTML: Void -> String = {
if let text = self.text {
return "<\(self.name)>\(text)</\(self.name)>"
} else {
return "<\(self.name) />"
}
}
init(name: String, text: String? = nil) {
self.name = name
self.text = text
}
deinit {
print("\(name) is being deinitialized")
}
}
HTMLElement类定义了一个name属性来表示这个元素的名称,例如代表头部元素的”h1”,代表段落的”p”,或者代表换行的”br”。HTMLElement还定义了一个可选属性text,用来设置 HTML 元素呈现的文本。
除了上面的两个属性,HTMLElement还定义了一个lazy属性asHTML。这个属性引用了一个将name和text组合成 HTML 字符串片段的闭包。该属性是Void -> String类型,或者可以理解为“一个没有参数,返回String的函数”。
默认情况下,闭包赋值给了asHTML属性,这个闭包返回一个代表 HTML 标签的字符串。如果text值存在,该标签就包含可选值text;如果text不存在,该标签就不包含文本。对于段落元素,根据text是”some text”还是nil,闭包会返回”<p>some text</p>“或者”<p />“。
可以像实例方法那样去命名、使用asHTML属性。然而,由于asHTML是闭包而不是实例方法,如果你想改变特定 HTML 元素的处理方式的话,可以用自定义的闭包来取代默认值。
例如,可以将一个闭包赋值给asHTML属性,这个闭包能在text属性是nil时使用默认文本,这是为了避免返回一个空的 HTML 标签:
let heading = HTMLElement(name: "h1")
let defaultText = "some default text"
heading.asHTML = {
return "<\(heading.name)>\(heading.text ?? defaultText)</\(heading.name)>"
}
print(heading.asHTML())
// 打印 "<h1>some default text</h1>"
注意 asHTML声明为lazy属性,因为只有当元素确实需要被处理为 HTML 输出的字符串时,才需要使用asHTML。也就是说,在默认的闭包中可以使用self,因为只有当初始化完成以及self确实存在后,才能访问lazy属性。
HTMLElement类只提供了一个构造函数,通过name和text(如果有的话)参数来初始化一个新元素。该类也定义了一个析构函数,当HTMLElement实例被销毁时,打印一条消息。
下面的代码展示了如何用HTMLElement类创建实例并打印消息:
var paragraph: HTMLElement? = HTMLElement(name: "p", text: "hello, world")
print(paragraph!.asHTML())
// 打印 "<p>hello, world</p>"
注意 上面的paragraph变量定义为可选类型的HTMLElement,因此我们可以赋值nil给它来演示循环强引用。
不幸的是,上面写的HTMLElement类产生了类实例和作为asHTML默认值的闭包之间的循环强引用。循环强引用如下图所示:
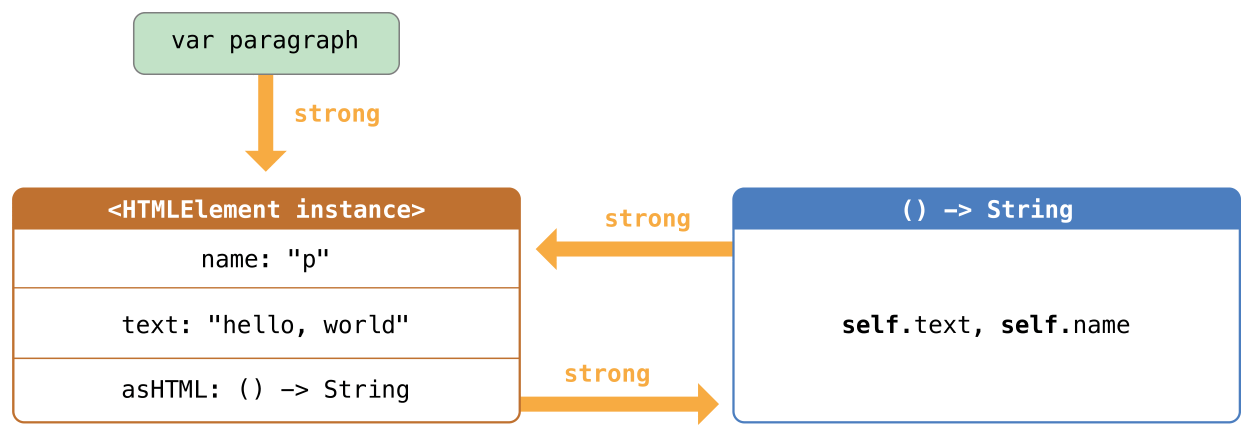
实例的asHTML属性持有闭包的强引用。但是,闭包在其闭包体内使用了self(引用了self.name和self.text),因此闭包捕获了self,这意味着闭包又反过来持有了HTMLElement实例的强引用。这样两个对象就产生了循环强引用。(更多关于闭包捕获值的信息,请参考值捕获)。
注意 虽然闭包多次使用了self,它只捕获HTMLElement实例的一个强引用。
如果设置paragraph变量为nil,打破它持有的HTMLElement实例的强引用,HTMLElement实例和它的闭包都不会被销毁,也是因为循环强引用:
paragraph = nil
注意,HTMLElement的析构函数中的消息并没有被打印,证明了HTMLElement实例并没有被销毁。
6 解决闭包引起的循环强引用
在定义闭包时同时定义捕获列表作为闭包的一部分,通过这种方式可以解决闭包和类实例之间的循环强引用。捕获列表定义了闭包体内捕获一个或者多个引用类型的规则。跟解决两个类实例间的循环强引用一样,声明每个捕获的引用为弱引用或无主引用,而不是强引用。应当根据代码关系来决定使用弱引用还是无主引用。
注意 Swift 有如下要求:只要在闭包内使用self的成员,就要用self.someProperty或者self.someMethod()(而不只是someProperty或someMethod())。这提醒你可能会一不小心就捕获了self。
6.1 定义捕获列表
捕获列表中的每一项都由一对元素组成,一个元素是weak或unowned关键字,另一个元素是类实例的引用(例如self)或初始化过的变量(如delegate = self.delegate!)。这些项在方括号中用逗号分开。
如果闭包有参数列表和返回类型,把捕获列表放在它们前面:
lazy var someClosure: (Int, String) -> String = {
[unowned self, weak delegate = self.delegate!] (index: Int, stringToProcess: String) -> String in
// 这里是闭包的函数体
}
如果闭包没有指明参数列表或者返回类型,即它们会通过上下文推断,那么可以把捕获列表和关键字in放在闭包最开始的地方:
lazy var someClosure: Void -> String = {
[unowned self, weak delegate = self.delegate!] in
// 这里是闭包的函数体
}
6.2 弱引用和无主引用
在闭包和捕获的实例总是互相引用并且总是同时销毁时,将闭包内的捕获定义为无主引用。
相反的,在被捕获的引用可能会变为nil时,将闭包内的捕获定义为弱引用。弱引用总是可选类型,并且当引用的实例被销毁后,弱引用的值会自动置为nil。这使我们可以在闭包体内检查它们是否存在。
注意 如果被捕获的引用绝对不会变为nil,应该用无主引用,而不是弱引用。
前面的HTMLElement例子中,无主引用是正确的解决循环强引用的方法。这样编写HTMLElement类来避免循环强引用:
class HTMLElement {
let name: String
let text: String?
lazy var asHTML: Void -> String = {
[unowned self] in
if let text = self.text {
return "<\(self.name)>\(text)</\(self.name)>"
} else {
return "<\(self.name) />"
}
}
init(name: String, text: String? = nil) {
self.name = name
self.text = text
}
deinit {
print("\(name) is being deinitialized")
}
}
上面的HTMLElement实现和之前的实现一致,除了在asHTML闭包中多了一个捕获列表。这里,捕获列表是[unowned self],表示“将self捕获为无主引用而不是强引用”。
和之前一样,我们可以创建并打印HTMLElement实例:
var paragraph: HTMLElement? = HTMLElement(name: "p", text: "hello, world")
print(paragraph!.asHTML())
// 打印 "<p>hello, world</p>"
使用捕获列表后引用关系如下图所示:
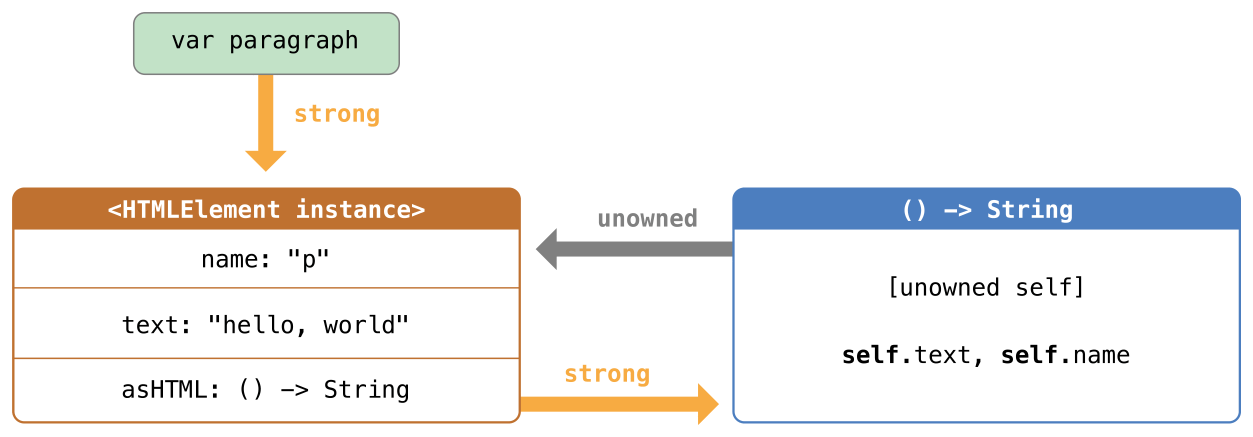
这一次,闭包以无主引用的形式捕获self,并不会持有HTMLElement实例的强引用。如果将paragraph赋值为nil,HTMLElement实例将会被销毁,并能看到它的析构函数打印出的消息:
paragraph = nil
// 打印 "p is being deinitialized"
可选链
可选链式调用是一种可以在当前值可能为nil的可选值上请求和调用属性、方法及下标的方法。如果可选值有值,那么调用就会成功;如果可选值是nil,那么调用将返回nil。多个调用可以连接在一起形成一个调用链,如果其中任何一个节点为nil,整个调用链都会失败,即返回nil。
注意 Swift 的可选链式调用和 Objective-C 中向nil发送消息有些相像,但是 Swift 的可选链式调用可以应用于任意类型,并且能检查调用是否成功。
1 使用可选链式调用代替强制展开
通过在想调用的属性、方法、或下标的可选值后面放一个问号(?),可以定义一个可选链。这一点很像在可选值后面放一个叹号(!)来强制展开它的值。它们的主要区别在于当可选值为空时可选链式调用只会调用失败,然而强制展开将会触发运行时错误。
为了反映可选链式调用可以在空值(nil)上调用的事实,不论这个调用的属性、方法及下标返回的值是不是可选值,它的返回结果都是一个可选值。你可以利用这个返回值来判断你的可选链式调用是否调用成功,如果调用有返回值则说明调用成功,返回nil则说明调用失败。
特别地,可选链式调用的返回结果与原本的返回结果具有相同的类型,但是被包装成了一个可选值。例如,使用可选链式调用访问属性,当可选链式调用成功时,如果属性原本的返回结果是Int类型,则会变为Int?类型。
下面几段代码将解释可选链式调用和强制展开的不同。
首先定义两个类Person和Residence:
class Person {
var residence: Residence?
}
class Residence {
var numberOfRooms = 1
}
Residence有一个Int类型的属性numberOfRooms,其默认值为1。Person具有一个可选的residence属性,其类型为Residence?。
假如你创建了一个新的Person实例,它的residence属性由于是是可选型而将初始化为nil,在下面的代码中,john有一个值为nil的residence属性:
let john = Person()
如果使用叹号(!)强制展开获得这个john的residence属性中的numberOfRooms值,会触发运行时错误,因为这时residence没有可以展开的值:
let roomCount = john.residence!.numberOfRooms
// 这会引发运行时错误
john.residence为非nil值的时候,上面的调用会成功,并且把roomCount设置为Int类型的房间数量。正如上面提到的,当residence为nil的时候上面这段代码会触发运行时错误。
可选链式调用提供了另一种访问numberOfRooms的方式,使用问号(?)来替代原来的叹号(!):
if let roomCount = john.residence?.numberOfRooms {
print("John's residence has \(roomCount) room(s).")
} else {
print("Unable to retrieve the number of rooms.")
}
// 打印 “Unable to retrieve the number of rooms.”
在residence后面添加问号之后,Swift 就会在residence不为nil的情况下访问numberOfRooms。
因为访问numberOfRooms有可能失败,可选链式调用会返回Int?类型,或称为“可选的 Int”。如上例所示,当residence为nil的时候,可选的Int将会为nil,表明无法访问numberOfRooms。访问成功时,可选的Int值会通过可选绑定展开,并赋值给非可选类型的roomCount常量。
要注意的是,即使numberOfRooms是非可选的Int时,这一点也成立。只要使用可选链式调用就意味着numberOfRooms会返回一个Int?而不是Int。
可以将一个Residence的实例赋给john.residence,这样它就不再是nil了:
john.residence = Residence()
john.residence现在包含一个实际的Residence实例,而不再是nil。如果你试图使用先前的可选链式调用访问numberOfRooms,它现在将返回值为1的Int?类型的值:
if let roomCount = john.residence?.numberOfRooms {
print("John's residence has \(roomCount) room(s).")
} else {
print("Unable to retrieve the number of rooms.")
}
// 打印 “John's residence has 1 room(s).”
2 为可选链式调用定义模型类
通过使用可选链式调用可以调用多层属性、方法和下标。这样可以在复杂的模型中向下访问各种子属性,并且判断能否访问子属性的属性、方法或下标。
下面这段代码定义了四个模型类,这些例子包括多层可选链式调用。为了方便说明,在Person和Residence的基础上增加了Room类和Address类,以及相关的属性、方法以及下标。
Person类的定义基本保持不变:
class Person {
var residence: Residence?
}
Residence类比之前复杂些,增加了一个名为rooms的变量属性,该属性被初始化为[Room]类型的空数组:
class Residence {
var rooms = [Room]()
var numberOfRooms: Int {
return rooms.count
}
subscript(i: Int) -> Room {
get {
return rooms[i]
}
set {
rooms[i] = newValue
}
}
func printNumberOfRooms() {
print("The number of rooms is \(numberOfRooms)")
}
var address: Address?
}
现在Residence有了一个存储Room实例的数组,numberOfRooms属性被实现为计算型属性,而不是存储型属性。numberOfRooms属性简单地返回rooms数组的count属性的值。
Residence还提供了访问rooms数组的快捷方式,即提供可读写的下标来访问rooms数组中指定位置的元素。
此外,Residence还提供了printNumberOfRooms方法,这个方法的作用是打印numberOfRooms的值。
最后,Residence还定义了一个可选属性address,其类型为Address?。Address类的定义在下面会说明。
Room类是一个简单类,其实例被存储在rooms数组中。该类只包含一个属性name,以及一个用于将该属性设置为适当的房间名的初始化函数:
class Room {
let name: String
init(name: String) { self.name = name }
}
最后一个类是Address,这个类有三个String?类型的可选属性。buildingName以及buildingNumber属性分别表示某个大厦的名称和号码,第三个属性street表示大厦所在街道的名称:
class Address {
var buildingName: String?
var buildingNumber: String?
var street: String?
func buildingIdentifier() -> String? {
if buildingName != nil {
return buildingName
} else if buildingNumber != nil && street != nil {
return "\(buildingNumber) \(street)"
} else {
return nil
}
}
}
Address类提供了buildingIdentifier()方法,返回值为String?。 如果buildingName有值则返回buildingName。或者,如果buildingNumber和street均有值则返回buildingNumber。否则,返回nil。
3 通过可选链式调用访问属性
正如使用可选链式调用代替强制展开中所述,可以通过可选链式调用在一个可选值上访问它的属性,并判断访问是否成功。
下面的代码创建了一个Person实例,然后像之前一样,尝试访问numberOfRooms属性:
let john = Person()
if let roomCount = john.residence?.numberOfRooms {
print("John's residence has \(roomCount) room(s).")
} else {
print("Unable to retrieve the number of rooms.")
}
// 打印 “Unable to retrieve the number of rooms.”
因为john.residence为nil,所以这个可选链式调用依旧会像先前一样失败。
还可以通过可选链式调用来设置属性值:
let someAddress = Address()
someAddress.buildingNumber = "29"
someAddress.street = "Acacia Road"
john.residence?.address = someAddress
在这个例子中,通过john.residence来设定address属性也会失败,因为john.residence当前为nil。
上面代码中的赋值过程是可选链式调用的一部分,这意味着可选链式调用失败时,等号右侧的代码不会被执行。对于上面的代码来说,很难验证这一点,因为像这样赋值一个常量没有任何副作用。下面的代码完成了同样的事情,但是它使用一个函数来创建Address实例,然后将该实例返回用于赋值。该函数会在返回前打印“Function was called”,这使你能验证等号右侧的代码是否被执行。
func createAddress() -> Address {
print("Function was called.")
let someAddress = Address()
someAddress.buildingNumber = "29"
someAddress.street = "Acacia Road"
return someAddress
}
john.residence?.address = createAddress()
没有任何打印消息,可以看出createAddress()函数并未被执行。
4 通过可选链式调用调用方法
可以通过可选链式调用来调用方法,并判断是否调用成功,即使这个方法没有返回值。
Residence类中的printNumberOfRooms()方法打印当前的numberOfRooms值,如下所示:
func printNumberOfRooms() {
print("The number of rooms is \(numberOfRooms)")
}
这个方法没有返回值。然而,没有返回值的方法具有隐式的返回类型Void,如无返回值函数中所述。这意味着没有返回值的方法也会返回(),或者说空的元组。
如果在可选值上通过可选链式调用来调用这个方法,该方法的返回类型会是Void?,而不是Void,因为通过可选链式调用得到的返回值都是可选的。这样我们就可以使用if语句来判断能否成功调用printNumberOfRooms()方法,即使方法本身没有定义返回值。通过判断返回值是否为nil可以判断调用是否成功:
if john.residence?.printNumberOfRooms() != nil {
print("It was possible to print the number of rooms.")
} else {
print("It was not possible to print the number of rooms.")
}
// 打印 “It was not possible to print the number of rooms.”
同样的,可以据此判断通过可选链式调用为属性赋值是否成功。在上面的通过可选链式调用访问属性的例子中,我们尝试给john.residence中的address属性赋值,即使residence为nil。通过可选链式调用给属性赋值会返回Void?,通过判断返回值是否为nil就可以知道赋值是否成功:
if (john.residence?.address = someAddress) != nil {
print("It was possible to set the address.")
} else {
print("It was not possible to set the address.")
}
// 打印 “It was not possible to set the address.”
5 通过可选链式调用访问下标
通过可选链式调用,我们可以在一个可选值上访问下标,并且判断下标调用是否成功。
注意 通过可选链式调用访问可选值的下标时,应该将问号放在下标方括号的前面而不是后面。可选链式调用的问号一般直接跟在可选表达式的后面。
下面这个例子用下标访问john.residence属性存储的Residence实例的rooms数组中的第一个房间的名称,因为john.residence为nil,所以下标调用失败了:
if let firstRoomName = john.residence?[0].name {
print("The first room name is \(firstRoomName).")
} else {
print("Unable to retrieve the first room name.")
}
// 打印 “Unable to retrieve the first room name.”
在这个例子中,问号直接放在john.residence的后面,并且在方括号的前面,因为john.residence是可选值。
类似的,可以通过下标,用可选链式调用来赋值:
john.residence?[0] = Room(name: "Bathroom")
这次赋值同样会失败,因为residence目前是nil。
如果你创建一个Residence实例,并为其rooms数组添加一些Room实例,然后将Residence实例赋值给john.residence,那就可以通过可选链和下标来访问数组中的元素:
let johnsHouse = Residence()
johnsHouse.rooms.append(Room(name: "Living Room"))
johnsHouse.rooms.append(Room(name: "Kitchen"))
john.residence = johnsHouse
if let firstRoomName = john.residence?[0].name {
print("The first room name is \(firstRoomName).")
} else {
print("Unable to retrieve the first room name.")
}
// 打印 “The first room name is Living Room.”
如果下标返回可选类型值,比如 Swift 中Dictionary类型的键的下标,可以在下标的结尾括号后面放一个问号来在其可选返回值上进行可选链式调用:
var testScores = ["Dave": [86, 82, 84], "Bev": [79, 94, 81]]
testScores["Dave"]?[0] = 91
testScores["Bev"]?[0] += 1
testScores["Brian"]?[0] = 72
// "Dave" 数组现在是 [91, 82, 84],"Bev" 数组现在是 [80, 94, 81]
上面的例子中定义了一个testScores数组,包含了两个键值对,把String类型的键映射到一个Int值的数组。这个例子用可选链式调用把”Dave”数组中第一个元素设为91,把”Bev”数组的第一个元素+1,然后尝试把”Brian”数组中的第一个元素设为72。前两个调用成功,因为testScores字典中包含”Dave”和”Bev”这两个键。但是testScores字典中没有”Brian”这个键,所以第三个调用失败。
6 连接多层可选链式调用
可以通过连接多个可选链式调用在更深的模型层级中访问属性、方法以及下标。然而,多层可选链式调用不会增加返回值的可选层级。
也就是说:
- 如果你访问的值不是可选的,可选链式调用将会返回可选值。
- 如果你访问的值就是可选的,可选链式调用不会让可选返回值变得“更可选”。
因此:
- 通过可选链式调用访问一个Int值,将会返回Int?,无论使用了多少层可选链式调用。
- 类似的,通过可选链式调用访问Int?值,依旧会返回Int?值,并不会返回Int??。
下面的例子尝试访问john中的residence属性中的address属性中的street属性。这里使用了两层可选链式调用,residence以及address都是可选值:
if let johnsStreet = john.residence?.address?.street {
print("John's street name is \(johnsStreet).")
} else {
print("Unable to retrieve the address.")
}
// 打印 “Unable to retrieve the address.”
john.residence现在包含一个有效的Residence实例。然而,john.residence.address的值当前为nil。因此,调用john.residence?.address?.street会失败。
需要注意的是,上面的例子中,street的属性为String?。john.residence?.address?.street的返回值也依然是String?,即使已经使用了两层可选链式调用。
如果为john.residence.address赋值一个Address实例,并且为address中的street属性设置一个有效值,我们就能过通过可选链式调用来访问street属性:
let johnsAddress = Address()
johnsAddress.buildingName = "The Larches"
johnsAddress.street = "Laurel Street"
john.residence?.address = johnsAddress
if let johnsStreet = john.residence?.address?.street {
print("John's street name is \(johnsStreet).")
} else {
print("Unable to retrieve the address.")
}
// 打印 “John's street name is Laurel Street.”
在上面的例子中,因为john.residence包含一个有效的Address实例,所以对john.residence的address属性赋值将会成功。
7 在方法的可选返回值上进行可选链式调用
上面的例子展示了如何在一个可选值上通过可选链式调用来获取它的属性值。我们还可以在一个可选值上通过可选链式调用来调用方法,并且可以根据需要继续在方法的可选返回值上进行可选链式调用。
在下面的例子中,通过可选链式调用来调用Address的buildingIdentifier()方法。这个方法返回String?类型的值。如上所述,通过可选链式调用来调用该方法,最终的返回值依旧会是String?类型:
if let buildingIdentifier = john.residence?.address?.buildingIdentifier() {
print("John's building identifier is \(buildingIdentifier).")
}
// 打印 “John's building identifier is The Larches.”
如果要在该方法的返回值上进行可选链式调用,在方法的圆括号后面加上问号即可:
if let beginsWithThe =
john.residence?.address?.buildingIdentifier()?.hasPrefix("The") {
if beginsWithThe {
print("John's building identifier begins with \"The\".")
} else {
print("John's building identifier does not begin with \"The\".")
}
}
// 打印 “John's building identifier begins with "The".”
注意 在上面的例子中,在方法的圆括号后面加上问号是因为你要在buildingIdentifier()方法的可选返回值上进行可选链式调用,而不是方法本身。
错误处理
错误处理(Error handling)是响应错误以及从错误中恢复的过程。Swift 提供了在运行时对可恢复错误的抛出、捕获、传递和操作的一等公民支持。
某些操作无法保证总是执行完所有代码或总是生成有用的结果。可选类型可用来表示值缺失,但是当某个操作失败时,最好能得知失败的原因,从而可以作出相应的应对。
举个例子,假如有个从磁盘上的某个文件读取数据并进行处理的任务,该任务会有多种可能失败的情况,包括指定路径下文件并不存在,文件不具有可读权限,或者文件编码格式不兼容。区分这些不同的失败情况可以让程序解决并处理某些错误,然后把它解决不了的错误报告给用户。
1 表示并抛出错误
在 Swift 中,错误用符合Error协议的类型的值来表示。这个空协议表明该类型可以用于错误处理。
Swift 的枚举类型尤为适合构建一组相关的错误状态,枚举的关联值还可以提供错误状态的额外信息。例如,你可以这样表示在一个游戏中操作自动贩卖机时可能会出现的错误状态:
enum VendingMachineError: Error {
case invalidSelection //选择无效
case insufficientFunds(coinsNeeded: Int) //金额不足
case outOfStock //缺货
}
抛出一个错误可以让你表明有意外情况发生,导致正常的执行流程无法继续执行。抛出错误使用throw关键字。例如,下面的代码抛出一个错误,提示贩卖机还需要5个硬币:
throw VendingMachineError.insufficientFunds(coinsNeeded: 5)
2 处理错误
某个错误被抛出时,附近的某部分代码必须负责处理这个错误,例如纠正这个问题、尝试另外一种方式、或是向用户报告错误。
Swift 中有4种处理错误的方式。你可以把函数抛出的错误传递给调用此函数的代码、用do-catch语句处理错误、将错误作为可选类型处理、或者断言此错误根本不会发生。每种方式在下面的小节中都有描述。
当一个函数抛出一个错误时,你的程序流程会发生改变,所以重要的是你能迅速识别代码中会抛出错误的地方。为了标识出这些地方,在调用一个能抛出错误的函数、方法或者构造器之前,加上try关键字,或者try?或try!这种变体。这些关键字在下面的小节中有具体讲解。
注意 Swift 中的错误处理和其他语言中用try,catch和throw进行异常处理很像。和其他语言中(包括 Objective-C )的异常处理不同的是,Swift 中的错误处理并不涉及解除调用栈,这是一个计算代价高昂的过程。就此而言,throw语句的性能特性是可以和return语句相媲美的。
2.1 用 throwing 函数传递错误
为了表示一个函数、方法或构造器可以抛出错误,在函数声明的参数列表之后加上throws关键字。一个标有throws关键字的函数被称作throwing 函数。如果这个函数指明了返回值类型,throws关键词需要写在箭头(->)的前面。
func canThrowErrors() throws -> String
func cannotThrowErrors() -> String
一个 throwing 函数可以在其内部抛出错误,并将错误传递到函数被调用时的作用域。
注意 只有 throwing 函数可以传递错误。任何在某个非 throwing 函数内部抛出的错误只能在函数内部处理。
下面的例子中,VendingMachine类有一个vend(itemNamed:)方法,如果请求的物品不存在、缺货或者投入金额小于物品价格,该方法就会抛出一个相应的VendingMachineError:
struct Item {
var price: Int
var count: Int
}
class VendingMachine {
var inventory = [
"Candy Bar": Item(price: 12, count: 7),
"Chips": Item(price: 10, count: 4),
"Pretzels": Item(price: 7, count: 11)
]
var coinsDeposited = 0
func dispenseSnack(snack: String) {
print("Dispensing \(snack)")
}
func vend(itemNamed name: String) throws {
guard let item = inventory[name] else {
throw VendingMachineError.invalidSelection
}
guard item.count > 0 else {
throw VendingMachineError.outOfStock
}
guard item.price <= coinsDeposited else {
throw VendingMachineError.insufficientFunds(coinsNeeded: item.price - coinsDeposited)
}
coinsDeposited -= item.price
var newItem = item
newItem.count -= 1
inventory[name] = newItem
print("Dispensing \(name)")
}
}
在vend(itemNamed:)方法的实现中使用了guard语句来提前退出方法,确保在购买某个物品所需的条件中,有任一条件不满足时,能提前退出方法并抛出相应的错误。由于throw语句会立即退出方法,所以物品只有在所有条件都满足时才会被售出。
因为vend(itemNamed:)方法会传递出它抛出的任何错误,在你的代码中调用此方法的地方,必须要么直接处理这些错误——使用do-catch语句,try?或try!;要么继续将这些错误传递下去。例如下面例子中,buyFavoriteSnack(person:vendingMachine:)同样是一个 throwing 函数,任何由vend(itemNamed:)方法抛出的错误会一直被传递到buyFavoriteSnack(person:vendingMachine:)函数被调用的地方。
let favoriteSnacks = [
"Alice": "Chips",
"Bob": "Licorice",
"Eve": "Pretzels",
]
func buyFavoriteSnack(person: String, vendingMachine: VendingMachine) throws {
let snackName = favoriteSnacks[person] ?? "Candy Bar"
try vendingMachine.vend(itemNamed: snackName)
}
上例中,buyFavoriteSnack(person:vendingMachine:)函数会查找某人最喜欢的零食,并通过调用vend(itemNamed:)方法来尝试为他们购买。因为vend(itemNamed:)方法能抛出错误,所以在调用的它时候在它前面加了try关键字。
throwing构造器能像throwing函数一样传递错误。例如下面代码中的PurchasedSnack构造器在构造过程中调用了throwing函数,并且通过传递到它的调用者来处理这些错误。
struct PurchasedSnack {
let name: String
init(name: String, vendingMachine: VendingMachine) throws {
try vendingMachine.vend(itemNamed: name)
self.name = name
}
}
2.2 用 Do-Catch 处理错误
可以使用一个do-catch语句运行一段闭包代码来处理错误。如果在do子句中的代码抛出了一个错误,这个错误会与catch子句做匹配,从而决定哪条子句能处理它。
下面是do-catch语句的一般形式:
do {
try expression
statements
} catch pattern 1 {
statements
} catch pattern 2 where condition {
statements
}
在catch后面写一个匹配模式来表明这个子句能处理什么样的错误。如果一条catch子句没有指定匹配模式,那么这条子句可以匹配任何错误,并且把错误绑定到一个名字为error的局部常量。关于模式匹配的更多信息请参考 模式。
catch子句不必将do子句中的代码所抛出的每一个可能的错误都作处理。如果所有catch子句都未处理错误,错误就会传递到周围的作用域。然而,错误还是必须要被某个周围的作用域处理的——要么是一个外围的do-catch错误处理语句,要么是一个 throwing 函数的内部。举例来说,下面的代码处理了VendingMachineError枚举类型的全部枚举值,但是所有其它的错误就必须由它周围的作用域处理:
var vendingMachine = VendingMachine()
vendingMachine.coinsDeposited = 8
do {
try buyFavoriteSnack(person: "Alice", vendingMachine: vendingMachine)
} catch VendingMachineError.invalidSelection {
print("Invalid Selection.")
} catch VendingMachineError.outOfStock {
print("Out of Stock.")
} catch VendingMachineError.insufficientFunds(let coinsNeeded) {
print("Insufficient funds. Please insert an additional \(coinsNeeded) coins.")
}
// 打印 “Insufficient funds. Please insert an additional 2 coins.”
上面的例子中,buyFavoriteSnack(person:vendingMachine:)函数在一个try表达式中调用,因为它能抛出错误。如果错误被抛出,相应的执行会马上转移到catch子句中,并判断这个错误是否要被继续传递下去。如果没有错误抛出,do子句中余下的语句就会被执行。
2.3 将错误转换成可选值
可以使用try?通过将错误转换成一个可选值来处理错误。如果在评估try?表达式时一个错误被抛出,那么表达式的值就是nil。例如,在下面的代码中,x和y有着相同的数值和等价的含义:
func someThrowingFunction() throws -> Int {
// ...
}
let x = try? someThrowingFunction()
let y: Int?
do {
y = try someThrowingFunction()
} catch {
y = nil
}
如果someThrowingFunction()抛出一个错误,x和y的值是nil。否则x和y的值就是该函数的返回值。注意,无论someThrowingFunction()的返回值类型是什么类型,x和y都是这个类型的可选类型。例子中此函数返回一个整型,所以x和y是可选整型。
如果你想对所有的错误都采用同样的方式来处理,用try?就可以让你写出简洁的错误处理代码。例如,下面的代码用几种方式来获取数据,如果所有方式都失败了则返回nil。
func fetchData() -> Data? {
if let data = try? fetchDataFromDisk() { return data }
if let data = try? fetchDataFromServer() { return data }
return nil
}
2.4 禁用错误传递
有时你知道某个throwing函数实际上在运行时是不会抛出错误的,在这种情况下,你可以在表达式前面写try!来禁用错误传递,这会把调用包装在一个不会有错误抛出的运行时断言中。如果真的抛出了错误,你会得到一个运行时错误。
例如,下面的代码使用了loadImage(atPath:)函数,该函数从给定的路径加载图片资源,如果图片无法载入则抛出一个错误。在这种情况下,因为图片是和应用绑定的,运行时不会有错误抛出,所以适合禁用错误传递。
let photo = try! loadImage(atPath: "./Resources/John Appleseed.jpg")
3 指定清理操作
可以使用defer语句在即将离开当前代码块时执行一系列语句。该语句让你能执行一些必要的清理工作,不管是以何种方式离开当前代码块的——无论是由于抛出错误而离开,或是由于诸如return、break的语句。例如,你可以用defer语句来确保文件描述符得以关闭,以及手动分配的内存得以释放。
defer语句将代码的执行延迟到当前的作用域退出之前。该语句由defer关键字和要被延迟执行的语句组成。延迟执行的语句不能包含任何控制转移语句,例如break、return语句,或是抛出一个错误。延迟执行的操作会按照它们声明的顺序从后往前执行——也就是说,第一条defer语句中的代码最后才执行,第二条defer语句中的代码倒数第二个执行,以此类推。最后一条语句会第一个执行
func processFile(filename: String) throws {
if exists(filename) {
let file = open(filename)
defer {
close(file)
}
while let line = try file.readline() {
// 处理文件。
}
// close(file) 会在这里被调用,即作用域的最后。
}
}
上面的代码使用一条defer语句来确保open(:)函数有一个相应的对close(:)函数的调用。
类型转换
类型转换 可以判断实例的类型,也可以将实例看做是其父类或者子类的实例。
类型转换在 Swift 中使用 is 和 as 操作符实现。这两个操作符提供了一种简单达意的方式去检查值的类型或者转换它的类型。
你也可以用它来检查一个类型是否实现了某个协议,就像在检验协议的一致性部分讲述的一样。
1 定义一个类层次作为例子
你可以将类型转换用在类和子类的层次结构上,检查特定类实例的类型并且转换这个类实例的类型成为这个层次结构中的其他类型。下面的三个代码段定义了一个类层次和一个包含了这些类实例的数组,作为类型转换的例子。
第一个代码片段定义了一个新的基类 MediaItem。这个类为任何出现在数字媒体库的媒体项提供基础功能。特别的,它声明了一个 String 类型的 name 属性,和一个 init(name:) 初始化器。(假定所有的媒体项都有个名称。)
class MediaItem {
var name: String
init(name: String) {
self.name = name
}
}
下一个代码段定义了 MediaItem 的两个子类。第一个子类 Movie 封装了与电影相关的额外信息,在父类(或者说基类)的基础上增加了一个 director(导演)属性,和相应的初始化器。第二个子类 Song,在父类的基础上增加了一个 artist(艺术家)属性,和相应的初始化器:
class Movie: MediaItem {
var director: String
init(name: String, director: String) {
self.director = director
super.init(name: name)
}
}
class Song: MediaItem {
var artist: String
init(name: String, artist: String) {
self.artist = artist
super.init(name: name)
}
}
最后一个代码段创建了一个数组常量 library,包含两个 Movie 实例和三个 Song 实例。library 的类型是在它被初始化时根据它数组中所包含的内容推断来的。Swift 的类型检测器能够推断出 Movie 和 Song 有共同的父类 MediaItem,所以它推断出 [MediaItem] 类作为 library 的类型:
let library = [
Movie(name: "Casablanca", director: "Michael Curtiz"),
Song(name: "Blue Suede Shoes", artist: "Elvis Presley"),
Movie(name: "Citizen Kane", director: "Orson Welles"),
Song(name: "The One And Only", artist: "Chesney Hawkes"),
Song(name: "Never Gonna Give You Up", artist: "Rick Astley")
]
// 数组 library 的类型被推断为 [MediaItem]
在幕后 library 里存储的媒体项依然是 Movie 和 Song 类型的。但是,若你迭代它,依次取出的实例会是 MediaItem 类型的,而不是 Movie 和 Song 类型。为了让它们作为原本的类型工作,你需要检查它们的类型或者向下转换它们到其它类型,就像下面描述的一样。
2 检查类型
用类型检查操作符(is)来检查一个实例是否属于特定子类型。若实例属于那个子类型,类型检查操作符返回 true,否则返回 false。
下面的例子定义了两个变量,movieCount 和 songCount,用来计算数组 library 中 Movie 和 Song 类型的实例数量:
var movieCount = 0
var songCount = 0
for item in library {
if item is Movie {
movieCount += 1
} else if item is Song {
songCount += 1
}
}
print("Media library contains \(movieCount) movies and \(songCount) songs")
// 打印 “Media library contains 2 movies and 3 songs”
示例迭代了数组 library 中的所有项。每一次,for-in 循环设置 item 为数组中的下一个 MediaItem。
若当前 MediaItem 是一个 Movie 类型的实例,item is Movie 返回 true,否则返回 false。同样的,item is Song 检查 item 是否为 Song 类型的实例。在循环结束后,movieCount 和 songCount 的值就是被找到的属于各自类型的实例的数量。
3 向下转型
某类型的一个常量或变量可能在幕后实际上属于一个子类。当确定是这种情况时,你可以尝试向下转到它的子类型,用类型转换操作符(as? 或 as!)。
因为向下转型可能会失败,类型转型操作符带有两种不同形式。条件形式as? 返回一个你试图向下转成的类型的可选值。强制形式 as! 把试图向下转型和强制解包转换结果结合为一个操作。
当你不确定向下转型可以成功时,用类型转换的条件形式(as?)。条件形式的类型转换总是返回一个可选值,并且若下转是不可能的,可选值将是 nil。这使你能够检查向下转型是否成功。
只有你可以确定向下转型一定会成功时,才使用强制形式(as!)。当你试图向下转型为一个不正确的类型时,强制形式的类型转换会触发一个运行时错误。
下面的例子,迭代了 library 里的每一个 MediaItem,并打印出适当的描述。要这样做,item 需要真正作为 Movie 或 Song 的类型来使用,而不仅仅是作为 MediaItem。为了能够在描述中使用 Movie 或 Song 的 director 或 artist 属性,这是必要的。
在这个示例中,数组中的每一个 item 可能是 Movie 或 Song。事前你不知道每个 item 的真实类型,所以这里使用条件形式的类型转换(as?)去检查循环里的每次下转:
for item in library {
if let movie = item as? Movie {
print("Movie: '\(movie.name)', dir. \(movie.director)")
} else if let song = item as? Song {
print("Song: '\(song.name)', by \(song.artist)")
}
}
// Movie: 'Casablanca', dir. Michael Curtiz
// Song: 'Blue Suede Shoes', by Elvis Presley
// Movie: 'Citizen Kane', dir. Orson Welles
// Song: 'The One And Only', by Chesney Hawkes
// Song: 'Never Gonna Give You Up', by Rick Astley
示例首先试图将 item 下转为 Movie。因为 item 是一个 MediaItem 类型的实例,它可能是一个 Movie;同样,它也可能是一个 Song,或者仅仅是基类 MediaItem。因为不确定,as? 形式在试图下转时将返回一个可选值。item as? Movie 的返回值是 Movie? 或者说“可选 Movie”。
当向下转型为 Movie 应用在两个 Song 实例时将会失败。为了处理这种情况,上面的例子使用了可选绑定(optional binding)来检查可选 Movie 真的包含一个值(这个是为了判断下转是否成功。)可选绑定是这样写的“if let movie = item as? Movie”,可以这样解读:
“尝试将 item 转为 Movie 类型。若成功,设置一个新的临时常量 movie 来存储返回的可选 Movie 中的值”
若向下转型成功,然后 movie 的属性将用于打印一个 Movie 实例的描述,包括它的导演的名字 director。相似的原理被用来检测 Song 实例,当 Song 被找到时则打印它的描述(包含 artist 的名字)。
注意 转换没有真的改变实例或它的值。根本的实例保持不变;只是简单地把它作为它被转换成的类型来使用。
4 Any 和 AnyObject 的类型转换
Swift 为不确定类型提供了两种特殊的类型别名:
- Any 可以表示任何类型,包括函数类型。
- AnyObject 可以表示任何类类型的实例。
只有当你确实需要它们的行为和功能时才使用 Any 和 AnyObject。在你的代码里使用你期望的明确类型总是更好的。
这里有个示例,使用 Any 类型来和混合的不同类型一起工作,包括函数类型和非类类型。它创建了一个可以存储 Any 类型的数组 things:
var things = [Any]()
things.append(0)
things.append(0.0)
things.append(42)
things.append(3.14159)
things.append("hello")
things.append((3.0, 5.0))
things.append(Movie(name: "Ghostbusters", director: "Ivan Reitman"))
things.append({ (name: String) -> String in "Hello, \(name)" })
things 数组包含两个 Int 值,两个 Double 值,一个 String 值,一个元组 (Double, Double),一个Movie实例“Ghostbusters”,以及一个接受 String 值并返回另一个 String 值的闭包表达式。
你可以在 switch 表达式的 case 中使用 is 和 as 操作符来找出只知道是 Any 或 AnyObject 类型的常量或变量的具体类型。下面的示例迭代 things 数组中的每一项,并用 switch 语句查找每一项的类型。有几个 switch 语句的 case 绑定它们匹配到的值到一个指定类型的常量,从而可以打印这些值:
注意 Any类型可以表示所有类型的值,包括可选类型。Swift 会在你用Any类型来表示一个可选值的时候,给你一个警告。如果你确实想使用Any类型来承载可选值,你可以使用as操作符显式转换为Any,如下所示:
let optionalNumber: Int? = 3
things.append(optionalNumber) // 警告
things.append(optionalNumber as Any) // 没有警告
嵌套类型
枚举常被用于为特定类或结构体实现某些功能。类似地,枚举可以方便的定义工具类或结构体,从而为某个复杂的类型所使用。为了实现这种功能,Swift 允许你定义嵌套类型,可以在支持的类型中定义嵌套的枚举、类和结构体。
要在一个类型中嵌套另一个类型,将嵌套类型的定义写在其外部类型的 {} 内,而且可以根据需要定义多级嵌套。
1 嵌套类型实践
下面这个例子定义了一个结构体 BlackjackCard(二十一点),用来模拟 BlackjackCard 中的扑克牌点数。BlackjackCard 结构体包含两个嵌套定义的枚举类型 Suit 和 Rank。
在 BlackjackCard 中,Ace 牌可以表示 1 或者 11 ,Ace 牌的这一特征通过一个嵌套在 Rank 枚举中的结构体 Values 来表示:
struct BlackjackCard {
// 嵌套的 Suit 枚举
enum Suit: Character {
case spades = "♠", hearts = "♡", diamonds = "♢", clubs = "♣"
}
// 嵌套的 Rank 枚举
enum Rank: Int {
case two = 2, three, four, five, six, seven, eight, nine, ten
case jack, queen, king, ace
struct Values {
let first: Int, second: Int?
}
var values: Values {
switch self {
case .ace:
return Values(first: 1, second: 11)
case .jack, .queen, .king:
return Values(first: 10, second: nil)
default:
return Values(first: self.rawValue, second: nil)
}
}
}
// BlackjackCard 的属性和方法
let rank: Rank, suit: Suit
var description: String {
var output = "suit is \(suit.rawValue),"
output += " value is \(rank.values.first)"
if let second = rank.values.second {
output += " or \(second)"
}
return output
}
}
Suit 枚举用来描述扑克牌的四种花色,并用一个 Character 类型的原始值表示花色符号。
Rank 枚举用来描述扑克牌从 Ace~10,以及 J、Q、K,这 13 种牌,并用一个 Int 类型的原始值表示牌的面值。(这个 Int 类型的原始值未用于 Ace、J、Q、K 这 4 种牌。)
如上所述,Rank 枚举在内部定义了一个嵌套结构体 Values。结构体 Values 中定义了两个属性,用于反映只有 Ace 有两个数值,其余牌都只有一个数值:
- first 的类型为 Int
- second 的类型为 Int?,或者说“可选 Int”
Rank 还定义了一个计算型属性 values,它将会返回一个 Values 结构体的实例。这个计算型属性会根据牌的面值,用适当的数值去初始化 Values 实例。对于 J、Q、K、Ace 这四种牌,会使用特殊数值。对于数字面值的牌,使用枚举实例的 Int 类型的原始值。
BlackjackCard 结构体拥有两个属性—— rank 与 suit。它也同样定义了一个计算型属性 description,description 属性用 rank 和 suit 中的内容来构建对扑克牌名字和数值的描述。该属性使用可选绑定来检查可选类型 second 是否有值,若有值,则在原有的描述中增加对 second 的描述。
因为 BlackjackCard 是一个没有自定义构造器的结构体,在结构体的逐一成员构造器中可知,结构体有默认的成员构造器,所以你可以用默认的构造器去初始化新常量 theAceOfSpades:
let theAceOfSpades = BlackjackCard(rank: .ace, suit: .spades)
print("theAceOfSpades: \(theAceOfSpades.description)")
// 打印 “theAceOfSpades: suit is ♠, value is 1 or 11”
尽管 Rank 和 Suit 嵌套在 BlackjackCard 中,但它们的类型仍可从上下文中推断出来,所以在初始化实例时能够单独通过成员名称(.ace 和 .spades)引用枚举实例。在上面的例子中,description 属性正确地反映了黑桃A牌具有 1 和 11 两个值。
2 引用嵌套类型
在外部引用嵌套类型时,在嵌套类型的类型名前加上其外部类型的类型名作为前缀:
let heartsSymbol = BlackjackCard.Suit.hearts.rawValue
// 红心符号为 “♡”
对于上面这个例子,这样可以使 Suit、Rank 和 Values 的名字尽可能的短,因为它们的名字可以由定义它们的上下文来限定。
扩展
扩展为现有的类、结构体、枚举类型、或协议添加了新功能。这也包括了为无访问权限的源代码扩展类型的能力(即所谓的逆向建模)。扩展和 Objective-C 中的分类类似。(与 Objective-C 的分类不同的是,Swift 的扩展没有名字。)
Swift 中的扩展可以:
- 添加计算实例属性和计算类型属性;
- 定义实例方法和类型方法;
- 提供新初始化器;
- 定义下标;
- 定义和使用新内嵌类型;
- 使现有的类型遵循某协议
在 Swift 中,你甚至可以扩展一个协议,以提供其要求的实现或添加符合类型的附加功能。
扩展可以向一个类型添加新的方法,但是不能重写已有的方法。
1 扩展的语法
使用 extension 关键字来声明扩展:
extension SomeType {
// new functionality to add to SomeType goes here
}
扩展可以使已有的类型遵循一个或多个协议。在这种情况下,协议名的书写方式与类或结构体完全一样:
extension SomeType: SomeProtocol, AnotherProtocol {
// implementation of protocol requirements goes here
}
用这种方式添加协议一致性详见在扩展里添加协议遵循。
如同扩展一个泛型类型中描述的那样,扩展可以用于丰富现有泛型类型。如同带有泛型 Where 分句的扩展中描述的那样,你也可以可选地给泛型添加功能。
如果你向已存在的类型添加新功能,新功能会在该类型的所有实例中可用,即使实例在该扩展定义之前就已经创建。
2 计算属性
扩展可以向已有的类型添加计算实例属性和计算类型属性。下面的例子向 Swift 内建的 Double 类型添加了五个计算实例属性,以提供对距离单位的基本支持:
extension Double {
var km: Double { return self * 1_000.0 }
var m: Double { return self }
var cm: Double { return self / 100.0 }
var mm: Double { return self / 1_000.0 }
var ft: Double { return self / 3.28084 }
}
let oneInch = 25.4.mm
print("One inch is \(oneInch) meters")
// Prints "One inch is 0.0254 meters"
let threeFeet = 3.ft
print("Three feet is \(threeFeet) meters")
// Prints "Three feet is 0.914399970739201 meters"
这些计算属性表述了 Double 值应被看作是确定的长度单位。尽管它们被实现为计算属性,这些属性的名字仍可使用点符号添加在浮点型的字面量之后,作为一种使用该字面量来执行距离转换的方法。
在这个例子中,一个 1.0 的 Double 值表示“一米”。这就是为什么 m 计算属性要返回 self ——表达式 1.m 表示计算 1.0 的 Double 值。
其他的单位则在以米作为计量值的基础上加以转换表示。一千米表示1000米,所以 km 计算属性将值乘 1_000.00 以用米来表示。类似的,一米有3.28084英尺,所以 ft 计算属性用 Double 值除以3.28084,将英尺转换为米。
上述属性为只读计算属性,为了简洁没有使用 get 关键字。他们都返回 Double 类型的值,可用于所有使用 Double 值的数学计算中:
let aMarathon = 42.km + 195.m
print("A marathon is \(aMarathon) meters long")
// Prints "A marathon is 42195.0 meters long"
扩展可以添加新的计算属性,但是不能添加存储属性,也不能向已有的属性添加属性观察者。
3 初始化器
扩展可向已有的类型添加新的初始化器。这允许你扩展其他类型以使初始化器接收你的自定义类型作为形式参数,或提供该类型的原始实现中未包含的额外初始化选项。
扩展能为类添加新的便捷初始化器,但是不能为类添加指定初始化器或反初始化器。指定初始化器和反初始化器 必须由原来类的实现提供。
如果你使用扩展为一个值类型添加初始化器,且该值类型为其所有储存的属性提供默认值,而又不定义任何自定义初始化器时,你可以在你扩展的初始化器中调用该类型默认的初始化器和成员初始化器。
下面的例子定义了一个自定义的 Rect 结构体用于描述几何矩形。这个例子也定义了两个辅助结构体 Size 和 Point ,二者的默认值都是 0.0 :
struct Size {
var width = 0.0, height = 0.0
}
struct Point {
var x = 0.0, y = 0.0
}
struct Rect {
var origin = Point()
var size = Size()
}
如同默认初始化器中描述的那样,由于 Rect 结构体为其所有属性提供了默认值,它将自动接收一个默认的初始化器和一个成员初始化器。这些初始化器能用于创建新的 Rect 实例:
let defaultRect = Rect()
let memberwiseRect = Rect(origin: Point(x: 2.0, y: 2.0),
size: Size(width: 5.0, height: 5.0))
你可以扩展 Rect 结构体以额外提供一个接收特定原点和大小的初始化器:
extension Rect {
init(center: Point, size: Size) {
let originX = center.x - (size.width / 2)
let originY = center.y - (size.height / 2)
self.init(origin: Point(x: originX, y: originY), size: size)
}
}
这个初始化器首先基于提供的 center 点和 size 值计算合适的原点。然后初始化器调用该结构体的自动成员初始化器 init(origin:size:) ,这样就将新的原点和大小值保存在了对应属性中:
let centerRect = Rect(center: Point(x: 4.0, y: 4.0),
size: Size(width: 3.0, height: 3.0))
// centerRect's origin is (2.5, 2.5) and its size is (3.0, 3.0)
如果你使用扩展提供了一个新的初始化器,你仍应确保每一个实例都在初始化完成时完全初始化。
4 方法
扩展可以为已有的类型添加新的实例方法和类型方法。下面的例子为 Int 类型添加了一个名为 repetitions 的新实例方法:
extension Int {
func repetitions(task: () -> Void) {
for _ in 0..<self {
task()
}
}
}
repetitions(task:) 方法接收一个 () -> Void 类型的单一实际参数,它表示一个没有参数且无返回值的函数。
在这个扩展定义之后,你可以在任何整型数字处调用 repetitions(task:) 方法,以执行相应次数的操作:
3.repetitions {
print("Hello!")
}
// Hello!
// Hello!
// Hello!
4.1 异变实例方法
增加了扩展的实例方法仍可以修改(或异变)实例本身。结构体和枚举类型方法在修改 self 或本身的属性时必须标记实例方法为 mutating ,和原本实现的异变方法一样。
下面的例子为 Swift 的 Int 类型添加了一个新的异变方法 square ,以表示原值的平方:
extension Int {
mutating func square() {
self = self * self
}
}
var someInt = 3
someInt.square()
// someInt is now 9
5 下标
扩展能为已有的类型添加新的下标。下面的例子为 Swift 内建的 Int 类型添加了一个整型下标。这个下标 [n] 返回了从右开始第 n 位的十进制数字:
- 123456789[0] 返回 9
- 123456789[1] 返回 8
……以此类推:
extension Int {
subscript(digitIndex: Int) -> Int {
var decimalBase = 1
for _ in 0..<digitIndex {
decimalBase *= 10
}
return (self / decimalBase) % 10
}
}
746381295[0]
// returns 5
746381295[1]
// returns 9
746381295[2]
// returns 2
746381295[8]
// returns 7
6 内嵌类型
扩展可以为已有的类、结构体和枚举类型添加新的内嵌类型:
extension Int {
enum Kind {
case negative, zero, positive
}
var kind: Kind {
switch self {
case 0:
return .zero
case let x where x > 0:
return .positive
default:
return .negative
}
}
}
这个例子为 Int 添加了新的内嵌枚举类型。这个名为 Kind 的枚举类型表示一个特定整数的类型。具体表示了这个数字是负数、零还是正数。
这个例还向 Int 中添加了新的计算实例属性 kind ,以返回该整数的合适 Kind 枚举情况。
这个内嵌的枚举类型可以和任意 Int 一起使用:
func printIntegerKinds(_ numbers: [Int]) {
for number in numbers {
switch number.kind {
case .negative:
print("- ", terminator: "")
case .zero:
print("0 ", terminator: "")
case .positive:
print("+ ", terminator: "")
}
}
print("")
}
printIntegerKinds([3, 19, -27, 0, -6, 0, 7])
// Prints "+ + - 0 - 0 + "
这里 printIntegerKinds(_:) 函数接收一个 Int 的数组并对这些值进行遍历。对数组的每一个数字,函数考虑这个整数的 kind 计算属性,并输出合适的描述。
协议
协议为方法、属性、以及其他特定的任务需求或功能定义蓝图。协议可被类、结构体、或枚举类型采纳以提供所需功能的具体实现。满足了协议中需求的任意类型都叫做遵循了该协议。
除了指定遵循类型必须实现的要求外,你可以扩展一个协议以实现其中的一些需求或实现一个符合类型的可以利用的附加功能。
1 协议的语法
定义协议的方式与类、结构体、枚举类型非常相似:
protocol SomeProtocol {
// protocol definition goes here
}
在自定义类型声明时,将协议名放在类型名的冒号之后来表示该类型采纳一个特定的协议。多个协议可以用逗号分开列出:
struct SomeStructure: FirstProtocol, AnotherProtocol {
// structure definition goes here
}
若一个类拥有父类,将这个父类名放在其采纳的协议名之前,并用逗号分隔:
class SomeClass: SomeSuperclass, FirstProtocol, AnotherProtocol {
// class definition goes here
}
2 属性要求
协议可以要求所有遵循该协议的类型提供特定名字和类型的实例属性或类型属性。协议并不会具体说明属性是储存型属性还是计算型属性——它只具体要求属性有特定的名称和类型。协议同时要求一个属性必须明确是可读的或可读的和可写的。
若协议要求一个属性为可读和可写的,那么该属性要求不能用常量存储属性或只读计算属性来满足。若协议只要求属性为可读的,那么任何种类的属性都能满足这个要求,而且如果你的代码需要的话,该属性也可以是可写的。
属性要求定义为变量属性,在名称前面使用 var 关键字。可读写的属性使用 { get set } 来写在声明后面来明确,使用 { get } 来明确可读的属性。
protocol SomeProtocol {
var mustBeSettable: Int { get set }
var doesNotNeedToBeSettable: Int { get }
}
在协议中定义类型属性时在前面添加 static 关键字。当类的实现使用 class 或 static 关键字前缀声明类型属性要求时,这个规则仍然适用:
protocol AnotherProtocol {
static var someTypeProperty: Int { get set }
}
这里是一个只有一个实例属性要求的协议:
protocol FullyNamed {
var fullName: String { get }
}
上面 FullyNamed 协议要求遵循的类型提供一个完全符合的名字。这个协议并未指定遵循类型的其他任何性质——它只要求这个属性必须为其自身提供一个全名。协议申明了所有 FullyNamed 类型必须有一个可读实例属性 fullName ,且为 String 类型。
这里是一个采纳并遵循 FullyNamed 协议的结构体的例子:
struct Person: FullyNamed {
var fullName: String
}
var john = Person(fullName: "John Appleseed")
// john.fullName is "John Appleseed"
john.fullName = "John Bye!"
// john.fullName is "John Bye!"
这个例子定义了一个名为 Person 的结构体,它表示一个有名字的人。它在其第一行定义中表明了它采纳 FullyNamed 协议作为它自身的一部分。
每一个 Person 的实例都有一个名为 fullName 的 String 类型储存属性。这符合了 FullyNamed 协议的单一要求,并且表示 Person 已经正确地遵循了该协议。(若协议的要求没有完全达标,Swift 在编译时会报错。)
这里是一个更加复杂的类,采纳并遵循了 FullyNamed 协议:
class Starship: FullyNamed {
var prefix: String?
var name: String
init(name: String, prefix: String? = nil) {
self.name = name
self.prefix = prefix
}
var fullName: String {
return (prefix != nil ? prefix! + " " : "") + name
}
}
var ncc1701 = Starship(name: "Enterprise", prefix: "USS")
// ncc1701.fullName is "USS Enterprise"
3 方法要求
协议可以要求采纳的类型实现指定的实例方法和类方法。这些方法作为协议定义的一部分,书写方式与正常实例和类方法的方式完全相同,但是不需要大括号和方法的主体。允许变量拥有参数,与正常的方法使用同样的规则。但在协议的定义中,方法参数不能定义默认值。
正如类型属性要求的那样,当协议中定义类型方法时,你总要在其之前添加 static 关键字。即使在类实现时,类型方法要求使用 class 或 static 作为关键字前缀,前面的规则仍然适用:
protocol SomeProtocol {
static func someTypeMethod()
}
下面的例子定义了一个只有一个实例方法要求的协议:
protocol RandomNumberGenerator {
func random() -> Double
}
这里 RandomNumberGenerator 协议要求所有采用该协议的类型都必须有一个实例方法 random ,而且要返回一个 Double 的值,无论这个值叫什么。尽管协议没有明确定义,这里默认这个值在 0.0 到 1.0 (不包括)之间。
RandomNumberGenerator 协议并不为随机值的生成过程做任何定义,它只要求生成器提供一个生成随机数的标准过程。
这里有一个采用并遵循 RandomNumberGenerator 协议的类的实现。这个类实现了著名的 linear congruential generator 伪随机数发生器算法:
class LinearCongruentialGenerator: RandomNumberGenerator {
var lastRandom = 42.0
let m = 139968.0
let a = 3877.0
let c = 29573.0
func random() -> Double {
lastRandom = ((lastRandom * a + c).truncatingRemainder(dividingBy:m))
return lastRandom / m
}
}
let generator = LinearCongruentialGenerator()
print("Here's a random number: \(generator.random())")
// Prints "Here's a random number: 0.37464991998171"
print("And another one: \(generator.random())")
// Prints "And another one: 0.729023776863283"
4 异变方法要求
有时一个方法需要改变(或异变)其所属的实例。例如值类型的实例方法(即结构体或枚举),在方法的 func 关键字之前使用 mutating 关键字,来表示在该方法可以改变其所属的实例,以及该实例的所有属性。这一过程写在了在实例方法中修改值类型中。
若你定义了一个协议的实例方法需求,想要异变任何采用了该协议的类型实例,只需在协议里方法的定义当中使用 mutating 关键字。这允许结构体和枚举类型能采用相应协议并满足方法要求。
如果你在协议中标记实例方法需求为
mutating,在为类实现该方法的时候不需要写mutating关键字。mutating关键字只在结构体和枚举类型中需要书写。
在Togglable协议的定义中, toggle() 方法使用 mutating 关键字标记,来表明该方法在调用时会改变遵循该协议的实例的状态:
protocol Togglable {
mutating func toggle()
}
若使用结构体或枚举实现 Togglable 协议,这个结构体或枚举可以通过使用 mutating 标记这个 toggle() 方法,来保证该实现符合协议要求。
下面的例子定义了一个名为 OnOffSwitch 的枚举。这个枚举在两种状态间改变,即枚举成员 On 和 Off 。该枚举的 toggle 实现使用了 mutating 关键字,以满足 Togglable 协议需求:
enum OnOffSwitch: Togglable {
case off, on
mutating func toggle() {
switch self {
case .off:
self = .on
case .on:
self = .off
}
}
}
var lightSwitch = OnOffSwitch.off
lightSwitch.toggle()
// lightSwitch is now equal to .on
5 初始化器要求
协议可以要求遵循协议的类型实现指定的初始化器。和一般的初始化器一样,只用将初始化器写在协议的定义当中,只是不用写大括号也就是初始化器的实体:
protocol SomeProtocol {
init(someParameter: Int)
}
5.1 协议初始化器要求的类实现
你可以通过实现指定初始化器或便捷初始化器来使遵循该协议的类满足协议的初始化器要求。在这两种情况下,你都必须使用 required 关键字修饰初始化器的实现:
class SomeClass: SomeProtocol {
required init(someParameter: Int) {
// initializer implementation goes here
}
}
在遵循协议的类的所有子类中, required 修饰的使用保证了你为协议初始化器要求提供了一个明确的继承实现。
由于
final的类不会有子类,如果协议初始化器实现的类使用了final标记,你就不需要使用required来修饰了。因为这样的类不能被继承子类。详见阻止重写了解更多 final 修饰符的信息。
如果一个子类重写了父类指定的初始化器,并且遵循协议实现了初始化器要求,那么就要为这个初始化器的实现添加 required 和 override 两个修饰符:
protocol SomeProtocol {
init()
}
class SomeSuperClass {
init() {
// initializer implementation goes here
}
}
class SomeSubClass: SomeSuperClass, SomeProtocol {
// "required" from SomeProtocol conformance; "override" from SomeSuperClass
required override init() {
// initializer implementation goes here
}
}
5.2 可失败初始化器要求
如同可失败初始化器定义的一样,协议可以为遵循该协议的类型定义可失败的初始化器。
遵循协议的类型可以使用一个可失败的或不可失败的初始化器满足一个可失败的初始化器要求。不可失败初始化器要求可以使用一个不可失败初始化器或隐式展开的可失败初始化器满足。
6 将协议作为类型
实际上协议自身并不实现功能。不过你创建的任意协议都可以变为一个功能完备的类型在代码中使用。
由于它是一个类型,你可以在很多其他类型可以使用的地方使用协议,包括:
- 在函数、方法或者初始化器里作为形式参数类型或者返回类型;
- 作为常量、变量或者属性的类型;
- 作为数组、字典或者其他存储器的元素的类型。
由于协议是类型,要开头大写(比如说 FullyNamed 和 RandomNumberGenerator )来匹配 Swift 里其他类型名称格式(比如说 Int 、 String 还有 Double )。
这里有一个把协议用作类型的例子:
class Dice {
let sides: Int
let generator: RandomNumberGenerator
init(sides: Int, generator: RandomNumberGenerator) {
self.sides = sides
self.generator = generator
}
func roll() -> Int {
return Int(generator.random() * Double(sides)) + 1
}
}
这个例子定义了一个叫做 Dice 的新类,它表示一个用于棋盘游戏的 n 面骰子。 Dice 实例有一个叫做 sides 的整数属性,它表示了骰子有多少个面,还有个叫做 generator 的属性,它提供了随机数的生成器来生成骰子的值。
generator 属性是 RandomNumberGenerator 类型。因此,你可以把它放到任何采纳了 RandomNumberGenerator 协议的类型的实例里。除了这个实例必须采纳 RandomNumberGenerator 协议以外,没有其他任何要求了。
Dice 也有一个初始化器,来设置初始状态。这个初始化器有一个形式参数叫做 generator ,它同样也是 RandomNumberGenerator 类型。你可以在初始化新的 Dice 实例的时候传入一个任意遵循这个协议的类型的值到这个形式参数里。
Dice 提供了一个形式参数方法, roll ,它返回一个介于 1 和骰子面数之间的整数值。这个方法调用生成器的 random() 方法来创建一个新的介于 0.0 和 1.0 之间的随机数,然后使用这个随机数来在正确的范围创建一个骰子的值。由于 generator 已知采纳了 RandomNumberGenerator ,它保证了会有 random() 方法以供调用。
这里是 Dice 类使用 LinearCongurentialGenerator 实例作为用于创建一个六面骰子的随机数生成器来创建一个六面骰子的过程:
var d6 = Dice(sides: 6, generator: LinearCongruentialGenerator())
for _ in 1...5 {
print("Random dice roll is \(d6.roll())")
}
// Random dice roll is 3
// Random dice roll is 5
// Random dice roll is 4
// Random dice roll is 5
// Random dice roll is 4
7 委托
委托是一个允许类或者结构体放手(或者说委托)它们自身的某些责任给另外类型实例的设计模式。这个设计模式通过定义一个封装了委托责任的协议来实现,比如遵循了协议的类型(所谓的委托)来保证提供被委托的功能。委托可以用来响应一个特定的行为,或者从外部资源取回数据而不需要了解资源具体的类型。
下面的例子定义了两个协议以用于基于骰子的棋盘游戏:
protocol DiceGame {
var dice: Dice { get }
func play()
}
protocol DiceGameDelegate {
func gameDidStart(_ game: DiceGame)
func game(_ game: DiceGame, didStartNewTurnWithDiceRoll diceRoll: Int)
func gameDidEnd(_ game: DiceGame)
}
DiceGame 协议是一个给任何与骰子有关的游戏采纳的协议。 DiceGameDelegate 协议可以被任何追踪 DiceGame 进度的类型采纳。
这里有一个原本在控制流中介绍的蛇与梯子游戏的一个版本。这个版本采纳了协议以使用 Dice 实例来让它使用骰子;采用 DiceGame 协议;然后通知一个 DiceGameDelegate 关于进度的信息:
class SnakesAndLadders: DiceGame {
let finalSquare = 25
let dice = Dice(sides: 6, generator: LinearCongruentialGenerator())
var square = 0
var board: [Int]
init() {
board = Array(repeating: 0, count: finalSquare + 1)
board[03] = +08; board[06] = +11; board[09] = +09; board[10] = +02
board[14] = -10; board[19] = -11; board[22] = -02; board[24] = -08
}
var delegate: DiceGameDelegate?
func play() {
square = 0
delegate?.gameDidStart(self)
gameLoop: while square != finalSquare {
let diceRoll = dice.roll()
delegate?.game(self, didStartNewTurnWithDiceRoll: diceRoll)
switch square + diceRoll {
case finalSquare:
break gameLoop
case let newSquare where newSquare > finalSquare:
continue gameLoop
default:
square += diceRoll
square += board[square]
}
}
delegate?.gameDidEnd(self)
}
}
这个版本的游戏使用了叫做 SnakesAndLadders 类包装,它采纳了 DiceGame 协议。它提供了可读的 dice 属性和一个 play() 方法来遵循协议。( dice 属性声明为常量属性是因为它不需要在初始化后再改变了,而且协议只需要它是可读的。)
蛇与梯子游戏棋盘设置都写在了类的 init() 初始化器中。所有的游戏逻辑都移动到了协议的 play 方法里,它使用了协议要求的 dice 属性来提供它的骰子值。
注意 delegate 属性被定义为可选的 DiceGameDelegate ,是因为玩游戏并不是必须要有委托。由于它是一个可选类型, delegate 属性自动地初始化为 nil 。此后,游戏的实例化者可以选择给属性赋值一个合适的委托。
DiceGameDelegate 提供了三个追踪游戏进度的方法。这三个方法在游戏逻辑的 play() 方法中协作,并且在游戏开始时调用,新一局开始,或者游戏结束。
由于 delegate 属性是可选的 DiceGameDelegate , play() 方法在每次调用委托的时候都使用可选链。如果 delegate 属性是空的,这些委托调用会优雅地失败并且没有错误。如果 delegate 属性非空,委托的方法就被调用了,并且把 SnakesAndLadders 实例作为形式参数传入。
接下来的例子展示了叫做 DiceGameTracker 的类,它次那了 DiceGameDelegate 协议:
class DiceGameTracker: DiceGameDelegate {
var numberOfTurns = 0
func gameDidStart(_ game: DiceGame) {
numberOfTurns = 0
if game is SnakesAndLadders {
print("Started a new game of Snakes and Ladders")
}
print("The game is using a \(game.dice.sides)-sided dice")
}
func game(_ game: DiceGame, didStartNewTurnWithDiceRoll diceRoll: Int) {
numberOfTurns += 1
print("Rolled a \(diceRoll)")
}
func gameDidEnd(_ game: DiceGame) {
print("The game lasted for \(numberOfTurns) turns")
}
}
DiceGameTracker 实现了 DiceGameDelegate 要求的所有方法。它使用这些方法来对游戏开了多少局保持追踪。它在游戏开始的时候重置 numberOfTurns 属性为零,在每次新一轮游戏开始的时候增加,并且一旦游戏结束,打印出游戏一共开了多少轮。
上边展示的 gameDidStart(_:) 的实现使用了 game 形式参数来打印某些关于游戏的信息。 game 形式参数是 DiceGame 类型,不是 SnakesAndLadders ,所以 gameDidStart(_:) 只能访问和使用 DiceGame 协议实现的那部分方法和属性。总之,转换类型之后方法还是可以使用的。在这个例子中,它检查 game 在后台是否就是 SnakesAndLadders 实例,如果是,打印合适的信息。
gameDidStart(_:) 方法同样访问传入的 game 形式参数里的 dice 属性。由于 game 已经遵循 DiceGame 协议,这就保证了dice属性的存在,并且 gameDidStart(_:)方法能够访问和打印骰子的 sides 属性,无论玩的是什么类型的游戏。
这里是 DiceGameTracker 的运行结果:
let tracker = DiceGameTracker()
let game = SnakesAndLadders()
game.delegate = tracker
game.play()
// Started a new game of Snakes and Ladders
// The game is using a 6-sided dice
// Rolled a 3
// Rolled a 5
// Rolled a 4
// Rolled a 5
// The game lasted for 4 turns
8 通过扩展添加协议一致性
即便无法修改源代码,依然可以通过扩展令已有类型遵循并符合协议。扩展可以为已有类型添加属性、方法、下标以及构造器,因此可以符合协议中的相应要求。详情请在扩展章节中查看。
注意 通过扩展令已有类型遵循并符合协议时,该类型的所有实例也会随之获得协议中定义的各项功能。
例如下面这个 TextRepresentable 协议,任何想要通过文本表示一些内容的类型都可以实现该协议。这些想要表示的内容可以是实例本身的描述,也可以是实例当前状态的文本描述:
protocol TextRepresentable {
var textualDescription: String { get }
}
可以通过扩展,令先前提到的 Dice 类遵循并符合 TextRepresentable 协议:
extension Dice: TextRepresentable {
var textualDescription: String {
return "A \(sides)-sided dice"
}
}
通过扩展遵循并符合协议,和在原始定义中遵循并符合协议的效果完全相同。协议名称写在类型名之后,以冒号隔开,然后在扩展的大括号内实现协议要求的内容。
现在所有 Dice 的实例都可以看做 TextRepresentable 类型:
let d12 = Dice(sides: 12, generator: LinearCongruentialGenerator())
print(d12.textualDescription)
// 打印 “A 12-sided dice”
同样,SnakesAndLadders 类也可以通过扩展遵循并符合 TextRepresentable 协议:
extension SnakesAndLadders: TextRepresentable {
var textualDescription: String {
return "A game of Snakes and Ladders with \(finalSquare) squares"
}
}
print(game.textualDescription)
// 打印 “A game of Snakes and Ladders with 25 squares”
9 通过扩展遵循协议
当一个类型已经符合了某个协议中的所有要求,却还没有声明遵循该协议时,可以通过空扩展体的扩展来遵循该协议:
struct Hamster {
var name: String
var textualDescription: String {
return "A hamster named \(name)"
}
}
extension Hamster: TextRepresentable {}
从现在起,Hamster 的实例可以作为 TextRepresentable 类型使用:
let simonTheHamster = Hamster(name: "Simon")
let somethingTextRepresentable: TextRepresentable = simonTheHamster
print(somethingTextRepresentable.textualDescription)
// 打印 “A hamster named Simon”
注意 即使满足了协议的所有要求,类型也不会自动遵循协议,必须显式地遵循协议。
10 协议类型的集合
协议类型可以在数组或者字典这样的集合中使用,在协议类型提到了这样的用法。下面的例子创建了一个元素类型为 TextRepresentable 的数组:
let things: [TextRepresentable] = [game, d12, simonTheHamster]
如下所示,可以遍历 things 数组,并打印每个元素的文本表示:
for thing in things {
print(thing.textualDescription)
}
// A game of Snakes and Ladders with 25 squares
// A 12-sided dice
// A hamster named Simon
thing 是 TextRepresentable 类型而不是 Dice,DiceGame,Hamster 等类型,即使实例在幕后确实是这些类型中的一种。由于 thing 是 TextRepresentable 类型,任何 TextRepresentable 的实例都有一个 textualDescription 属性,所以在每次循环中可以安全地访问 thing.textualDescription。
11 协议继承
协议能够继承一个或多个其他协议,可以在继承的协议的基础上增加新的要求。协议的继承语法与类的继承相似,多个被继承的协议间用逗号分隔:
protocol InheritingProtocol: SomeProtocol, AnotherProtocol {
// 这里是协议的定义部分
}
如下所示,PrettyTextRepresentable 协议继承了 TextRepresentable 协议:
protocol PrettyTextRepresentable: TextRepresentable { var prettyTextualDescription: String { get } }
例子中定义了一个新的协议 PrettyTextRepresentable,它继承自 TextRepresentable 协议。任何遵循 PrettyTextRepresentable 协议的类型在满足该协议的要求时,也必须满足 TextRepresentable 协议的要求。在这个例子中,PrettyTextRepresentable 协议额外要求遵循协议的类型提供一个返回值为 String 类型的 prettyTextualDescription 属性。
如下所示,扩展 SnakesAndLadders,使其遵循并符合 PrettyTextRepresentable 协议:
extension SnakesAndLadders: PrettyTextRepresentable {
var prettyTextualDescription: String {
var output = textualDescription + ":\n"
for index in 1...finalSquare {
switch board[index] {
case let ladder where ladder > 0:
output += "▲ "
case let snake where snake < 0:
output += "▼ "
default:
output += "○ "
}
}
return output
}
}
上述扩展令 SnakesAndLadders 遵循了 PrettyTextRepresentable 协议,并提供了协议要求的 prettyTextualDescription 属性。每个 PrettyTextRepresentable 类型同时也是 TextRepresentable 类型,所以在 prettyTextualDescription 的实现中,可以访问 textualDescription 属性。然后,拼接上了冒号和换行符。接着,遍历数组中的元素,拼接一个几何图形来表示每个棋盘方格的内容:
- 当从数组中取出的元素的值大于 0 时,用 ▲ 表示。
- 当从数组中取出的元素的值小于 0 时,用 ▼ 表示。
- 当从数组中取出的元素的值等于 0 时,用 ○ 表示。
任意 SankesAndLadders 的实例都可以使用 prettyTextualDescription 属性来打印一个漂亮的文本描述:
print(game.prettyTextualDescription)
// A game of Snakes and Ladders with 25 squares:
// ○ ○ ▲ ○ ○ ▲ ○ ○ ▲ ▲ ○ ○ ○ ▼ ○ ○ ○ ○ ▼ ○ ○ ▼ ○ ▼ ○
12 类类型专属协议
你可以在协议的继承列表中,通过添加 class 关键字来限制协议只能被类类型遵循,而结构体或枚举不能遵循该协议。class 关键字必须第一个出现在协议的继承列表中,在其他继承的协议之前:
protocol SomeClassOnlyProtocol: class, SomeInheritedProtocol {
// 这里是类类型专属协议的定义部分
}
在以上例子中,协议 SomeClassOnlyProtocol 只能被类类型遵循。如果尝试让结构体或枚举类型遵循该协议,则会导致编译错误。
注意 当协议定义的要求需要遵循协议的类型必须是引用语义而非值语义时,应该采用类类型专属协议。关于引用语义和值语义的更多内容,请查看结构体和枚举是值类型和类是引用类型。
13 协议合成
有时候需要同时遵循多个协议,你可以将多个协议采用 SomeProtocol & AnotherProtocol 这样的格式进行组合,称为 协议合成(protocol composition)。你可以罗列任意多个你想要遵循的协议,以与符号(&)分隔。
下面的例子中,将 Named 和 Aged 两个协议按照上述语法组合成一个协议,作为函数参数的类型:
protocol Named {
var name: String { get }
}
protocol Aged {
var age: Int { get }
}
struct Person: Named, Aged {
var name: String
var age: Int
}
func wishHappyBirthday(to celebrator: Named & Aged) {
print("Happy birthday, \(celebrator.name), you're \(celebrator.age)!")
}
let birthdayPerson = Person(name: "Malcolm", age: 21)
wishHappyBirthday(to: birthdayPerson)
// 打印 “Happy birthday Malcolm - you're 21!”
Named 协议包含 String 类型的 name 属性。Aged 协议包含 Int 类型的 age 属性。Person 结构体遵循了这两个协议。
wishHappyBirthday(to:) 函数的参数 celebrator 的类型为 Named & Aged。这意味着它不关心参数的具体类型,只要参数符合这两个协议即可。
上面的例子创建了一个名为 birthdayPerson 的 Person 的实例,作为参数传递给了 wishHappyBirthday(to:) 函数。因为 Person 同时符合这两个协议,所以这个参数合法,函数将打印生日问候语。
这里有一个例子:将Location类和前面的Named协议进行组合:
class Location {
var latitude: Double
var longitude: Double
init(latitude: Double, longitude: Double) {
self.latitude = latitude
self.longitude = longitude
}
}
class City: Location, Named {
var name: String
init(name: String, latitude: Double, longitude: Double) {
self.name = name
super.init(latitude: latitude, longitude: longitude)
}
}
func beginConcert(in location: Location & Named) {
print("Hello, \(location.name)!")
}
let seattle = City(name: "Seattle", latitude: 47.6, longitude: -122.3)
beginConcert(in: seattle)
// Prints "Hello, Seattle!"
beginConcert(in:)方法接受一个类型为 Location & Named 的参数,这意味着”任何Location的子类,并且遵循Named协议”。例如,City就满足这样的条件。
将 birthdayPerson 传入beginConcert(in:)函数是不合法的,因为 Person不是一个Location的子类。就像,如果你新建一个类继承与Location,但是没有遵循Named协议,你用这个类的实例去调用beginConcert(in:)函数也是不合法的。
14 检查协议一致性
你可以使用类型转换中描述的 is 和 as 操作符来检查协议一致性,即是否符合某协议,并且可以转换到指定的协议类型。检查和转换到某个协议类型在语法上和类型的检查和转换完全相同:
- is 用来检查实例是否符合某个协议,若符合则返回 true,否则返回 false。
- as? 返回一个可选值,当实例符合某个协议时,返回类型为协议类型的可选值,否则返回 nil。
- as! 将实例强制向下转换到某个协议类型,如果强转失败,会引发运行时错误。
下面的例子定义了一个 HasArea 协议,该协议定义了一个 Double 类型的可读属性 area:
protocol HasArea {
var area: Double { get }
}
如下所示,Circle 类和 Country 类都遵循了 HasArea 协议:
class Circle: HasArea {
let pi = 3.1415927
var radius: Double
var area: Double { return pi * radius * radius }
init(radius: Double) { self.radius = radius }
}
class Country: HasArea {
var area: Double
init(area: Double) { self.area = area }
}
Circle 类把 area 属性实现为基于存储型属性 radius 的计算型属性。Country 类则把 area 属性实现为存储型属性。这两个类都正确地符合了 HasArea 协议。
如下所示,Animal 是一个未遵循 HasArea 协议的类:
class Animal {
var legs: Int
init(legs: Int) { self.legs = legs }
}
Circle,Country,Animal 并没有一个共同的基类,尽管如此,它们都是类,它们的实例都可以作为 AnyObject 类型的值,存储在同一个数组中:
let objects: [AnyObject] = [
Circle(radius: 2.0),
Country(area: 243_610),
Animal(legs: 4)
]
objects 数组使用字面量初始化,数组包含一个 radius 为 2 的 Circle 的实例,一个保存了英国国土面积的 Country 实例和一个 legs 为 4 的 Animal 实例。
如下所示,objects 数组可以被迭代,并对迭代出的每一个元素进行检查,看它是否符合 HasArea 协议:
for object in objects {
if let objectWithArea = object as? HasArea {
print("Area is \(objectWithArea.area)")
} else {
print("Something that doesn't have an area")
}
}
// Area is 12.5663708
// Area is 243610.0
// Something that doesn't have an area
当迭代出的元素符合 HasArea 协议时,将 as? 操作符返回的可选值通过可选绑定,绑定到 objectWithArea 常量上。objectWithArea 是 HasArea 协议类型的实例,因此 area 属性可以被访问和打印。
objects 数组中的元素的类型并不会因为强转而丢失类型信息,它们仍然是 Circle,Country,Animal 类型。然而,当它们被赋值给 objectWithArea 常量时,只被视为 HasArea 类型,因此只有 area 属性能够被访问。
15 可选的协议要求
协议可以定义可选要求,遵循协议的类型可以选择是否实现这些要求。在协议中使用 optional 关键字作为前缀来定义可选要求。可选要求用在你需要和 Objective-C 打交道的代码中。协议和可选要求都必须带上@objc属性。标记 @objc 特性的协议只能被继承自 Objective-C 类的类或者 @objc 类遵循,其他类以及结构体和枚举均不能遵循这种协议。
使用可选要求时(例如,可选的方法或者属性),它们的类型会自动变成可选的。比如,一个类型为 (Int) -> String 的方法会变成 ((Int) -> String)?。需要注意的是整个函数类型是可选的,而不是函数的返回值。
协议中的可选要求可通过可选链式调用来使用,因为遵循协议的类型可能没有实现这些可选要求。类似 someOptionalMethod?(someArgument) 这样,你可以在可选方法名称后加上 ? 来调用可选方法。详细内容可在可选链式调用章节中查看。
下面的例子定义了一个名为 Counter 的用于整数计数的类,它使用外部的数据源来提供每次的增量。数据源由 CounterDataSource 协议定义,包含两个可选要求:
@objc protocol CounterDataSource {
@objc optional func incrementForCount(count: Int) -> Int
@objc optional var fixedIncrement: Int { get }
}
CounterDataSource 协议定义了一个可选方法 increment(forCount:) 和一个可选属性 fiexdIncrement,它们使用了不同的方法来从数据源中获取适当的增量值。
注意 严格来讲,CounterDataSource 协议中的方法和属性都是可选的,因此遵循协议的类可以不实现这些要求,尽管技术上允许这样做,不过最好不要这样写。
Counter 类含有 CounterDataSource? 类型的可选属性 dataSource,如下所示:
class Counter {
var count = 0
var dataSource: CounterDataSource?
func increment() {
if let amount = dataSource?.incrementForCount?(count) {
count += amount
} else if let amount = dataSource?.fixedIncrement {
count += amount
}
}
}
Counter 类使用变量属性 count 来存储当前值。该类还定义了一个 increment 方法,每次调用该方法的时候,将会增加 count 的值。
increment() 方法首先试图使用 increment(forCount:) 方法来得到每次的增量。increment() 方法使用可选链式调用来尝试调用 increment(forCount:),并将当前的 count 值作为参数传入。
这里使用了两层可选链式调用。首先,由于 dataSource 可能为 nil,因此在 dataSource 后边加上了 ?,以此表明只在 dataSource 非空时才去调用 increment(forCount:) 方法。其次,即使 dataSource 存在,也无法保证其是否实现了 increment(forCount:) 方法,因为这个方法是可选的。因此,increment(forCount:) 方法同样使用可选链式调用进行调用,只有在该方法被实现的情况下才能调用它,所以在 increment(forCount:) 方法后边也加上了 ?。
调用 increment(forCount:) 方法在上述两种情形下都有可能失败,所以返回值为 Int? 类型。虽然在 CounterDataSource 协议中,increment(forCount:) 的返回值类型是非可选 Int。另外,即使这里使用了两层可选链式调用,最后的返回结果依旧是单层的可选类型。关于这一点的更多信息,请查阅连接多层可选链式调用
在调用 increment(forCount:) 方法后,Int? 型的返回值通过可选绑定解包并赋值给常量 amount。如果可选值确实包含一个数值,也就是说,数据源和方法都存在,数据源方法返回了一个有效值。之后便将解包后的 amount 加到 count 上,增量操作完成。
如果没有从 increment(forCount:) 方法获取到值,可能由于 dataSource 为 nil,或者它并没有实现 increment(forCount:) 方法,那么 increment() 方法将试图从数据源的 fixedIncrement 属性中获取增量。fixedIncrement 是一个可选属性,因此属性值是一个 Int? 值,即使该属性在 CounterDataSource 协议中的类型是非可选的 Int。
下面的例子展示了 CounterDataSource 的简单实现。ThreeSource 类遵循了 CounterDataSource 协议,它实现了可选属性 fixedIncrement,每次会返回 3:
class ThreeSource: NSObject, CounterDataSource {
let fixedIncrement = 3
}
可以使用 ThreeSource 的实例作为 Counter 实例的数据源:
var counter = Counter()
counter.dataSource = ThreeSource()
for _ in 1...4 {
counter.increment()
print(counter.count)
}
// 3
// 6
// 9
// 12
上述代码新建了一个 Counter 实例,并将它的数据源设置为一个 ThreeSource 的实例,然后调用 increment() 方法四次。和预期一样,每次调用都会将 count 的值增加 3.
下面是一个更为复杂的数据源 TowardsZeroSource,它将使得最后的值变为 0:
@objc class TowardsZeroSource: NSObject, CounterDataSource {
func increment(forCount count: Int) -> Int {
if count == 0 {
return 0
} else if count < 0 {
return 1
} else {
return -1
}
}
}
TowardsZeroSource 实现了 CounterDataSource 协议中的 increment(forCount:) 方法,以 count 参数为依据,计算出每次的增量。如果 count 已经为 0,此方法返回 0,以此表明之后不应再有增量操作发生。
你可以使用 TowardsZeroSource 实例将 Counter 实例来从 -4 增加到 0。一旦增加到 0,数值便不会再有变动:
counter.count = -4
counter.dataSource = TowardsZeroSource()
for _ in 1...5 {
counter.increment()
print(counter.count)
}
// -3
// -2
// -1
// 0
// 0
16 协议扩展
协议可以通过扩展来为遵循协议的类型提供属性、方法以及下标的实现。通过这种方式,你可以基于协议本身来实现这些功能,而无需在每个遵循协议的类型中都重复同样的实现,也无需使用全局函数。
例如,可以扩展 RandomNumberGenerator 协议来提供 randomBool() 方法。该方法使用协议中定义的 random() 方法来返回一个随机的 Bool 值:
extension RandomNumberGenerator {
func randomBool() -> Bool {
return random() > 0.5
}
}
通过协议扩展,所有遵循协议的类型,都能自动获得这个扩展所增加的方法实现,无需任何额外修改:
let generator = LinearCongruentialGenerator()
print("Here's a random number: \(generator.random())")
// 打印 “Here's a random number: 0.37464991998171”
print("And here's a random Boolean: \(generator.randomBool())")
// 打印 “And here's a random Boolean: true”
16.1 提供默认实现
可以通过协议扩展来为协议要求的属性、方法以及下标提供默认的实现。如果遵循协议的类型为这些要求提供了自己的实现,那么这些自定义实现将会替代扩展中的默认实现被使用。
注意 通过协议扩展为协议要求提供的默认实现和可选的协议要求不同。虽然在这两种情况下,遵循协议的类型都无需自己实现这些要求,但是通过扩展提供的默认实现可以直接调用,而无需使用可选链式调用。
例如,PrettyTextRepresentable 协议继承自 TextRepresentable 协议,可以为其提供一个默认的 prettyTextualDescription 属性,只是简单地返回 textualDescription 属性的值:
extension PrettyTextRepresentable {
var prettyTextualDescription: String {
return textualDescription
}
}
16.2 给协议扩展添加限制
在扩展协议的时候,可以指定一些限制条件,只有遵循协议的类型满足这些限制条件时,才能获得协议扩展提供的默认实现。这些限制条件写在协议名之后,使用 where 子句来描述,正如Where子句中所描述的。
例如,你可以扩展 CollectionType 协议,但是只适用于集合中的元素遵循了 TextRepresentable 协议的情况:
extension Collection where Iterator.Element: TextRepresentable {
var textualDescription: String {
let itemsAsText = self.map { $0.textualDescription }
return "[" + itemsAsText.joined(separator: ", ") + "]"
}
}
textualDescription 属性返回整个集合的文本描述,它将集合中的每个元素的文本描述以逗号分隔的方式连接起来,包在一对方括号中。
现在我们来看看先前的 Hamster 结构体,它符合 TextRepresentable 协议,同时这里还有个装有 Hamster 的实例的数组:
let murrayTheHamster = Hamster(name: "Murray")
let morganTheHamster = Hamster(name: "Morgan")
let mauriceTheHamster = Hamster(name: "Maurice")
let hamsters = [murrayTheHamster, morganTheHamster, mauriceTheHamster]
因为 Array 符合 CollectionType 协议,而数组中的元素又符合 TextRepresentable 协议,所以数组可以使用 textualDescription 属性得到数组内容的文本表示:
print(hamsters.textualDescription)
// 打印 “[A hamster named Murray, A hamster named Morgan, A hamster named Maurice]”
注意 如果多个协议扩展都为同一个协议要求提供了默认实现,而遵循协议的类型又同时满足这些协议扩展的限制条件,那么将会使用限制条件最多的那个协议扩展提供的默认实现。
泛型
泛型代码让你能够根据自定义的需求,编写出适用于任意类型、灵活可重用的函数及类型。它能让你避免代码的重复,用一种清晰和抽象的方式来表达代码的意图。
泛型是 Swift 最强大的特性之一,许多 Swift 标准库是通过泛型代码构建的。事实上,泛型的使用贯穿了整本语言手册,只是你可能没有发现而已。例如,Swift 的 Array 和 Dictionary 都是泛型集合。你可以创建一个 Int 数组,也可创建一个 String 数组,甚至可以是任意其他 Swift 类型的数组。同样的,你也可以创建存储任意指定类型的字典。
1 泛型所解决的问题
下面是一个标准的非泛型函数 swapTwoInts(::),用来交换两个 Int 值:
func swapTwoInts(_ a: inout Int, _ b: inout Int) {
let temporaryA = a
a = b
b = temporaryA
}
这个函数使用输入输出参数(inout)来交换 a 和 b 的值,请参考输入输出参数。
swapTwoInts(::) 函数交换 b 的原始值到 a,并交换 a 的原始值到 b。你可以调用这个函数交换两个 Int 变量的值:
var someInt = 3
var anotherInt = 107
swapTwoInts(&someInt, &anotherInt)
print("someInt is now \(someInt), and anotherInt is now \(anotherInt)")
// 打印 “someInt is now 107, and anotherInt is now 3”
诚然,swapTwoInts(::) 函数挺有用,但是它只能交换 Int 值,如果你想要交换两个 String 值或者 Double值,就不得不写更多的函数,例如 swapTwoStrings(::) 和 swapTwoDoubles(::),如下所示:
func swapTwoStrings(_ a: inout String, _ b: inout String) {
let temporaryA = a
a = b
b = temporaryA
}
func swapTwoDoubles(_ a: inout Double, _ b: inout Double) {
let temporaryA = a
a = b
b = temporaryA
}
你可能注意到 swapTwoInts(::)、swapTwoStrings(::) 和 swapTwoDoubles(::) 的函数功能都是相同的,唯一不同之处就在于传入的变量类型不同,分别是 Int、String 和 Double。
在实际应用中,通常需要一个更实用更灵活的函数来交换两个任意类型的值,幸运的是,泛型代码帮你解决了这种问题。(这些函数的泛型版本已经在下面定义好了。)
注意 在上面三个函数中,a 和 b 类型必须相同。如果 a 和 b 类型不同,那它们俩就不能互换值。Swift 是类型安全的语言,所以它不允许一个 String 类型的变量和一个 Double 类型的变量互换值。试图这样做将导致编译错误。
2 泛型函数
泛型函数可以适用于任何类型,下面的 swapTwoValues(::) 函数是上面三个函数的泛型版本:
func swapTwoValues<T>(_ a: inout T, _ b: inout T) {
let temporaryA = a
a = b
b = temporaryA
}
swapTwoValues(::) 的函数主体和 swapTwoInts(::) 函数是一样的,它们只在第一行有点不同,如下所示:
func swapTwoInts(_ a: inout Int, _ b: inout Int)
func swapTwoValues<T>(_ a: inout T, _ b: inout T)
这个函数的泛型版本使用了占位类型名(在这里用字母 T 来表示)来代替实际类型名(例如 Int、String 或 Double)。占位类型名没有指明 T 必须是什么类型,但是它指明了 a 和 b 必须是同一类型 T,无论 T 代表什么类型。只有 swapTwoValues(::) 函数在调用时,才会根据所传入的实际类型决定 T 所代表的类型。
泛型函数和非泛型函数的另外一个不同之处,在于这个泛型函数名(swapTwoValues(::))后面跟着占位类型名(T),并用尖括号括起来(
swapTwoValues(::) 函数现在可以像 swapTwoInts(::) 那样调用,不同的是它能接受两个任意类型的值,条件是这两个值有着相同的类型。swapTwoValues(::) 函数被调用时,T 所代表的类型都会由传入的值的类型推断出来。
在下面的两个例子中,T 分别代表 Int 和 String:
var someInt = 3
var anotherInt = 107
swapTwoValues(&someInt, &anotherInt)
// someInt 现在 107, and anotherInt 现在 3
var someString = "hello"
var anotherString = "world"
swapTwoValues(&someString, &anotherString)
// someString 现在 "world", and anotherString 现在 "hello"
注意 上面定义的 swapTwoValues(::) 函数是受 swap(::) 函数启发而实现的。后者存在于 Swift 标准库,你可以在你的应用程序中使用它。如果你在代码中需要类似 swapTwoValues(::) 函数的功能,你可以使用已存在的 swap(::) 函数。
3 类型参数
在上面的 swapTwoValues(::) 例子中,占位类型 T 是类型参数的一个例子。类型参数指定并命名一个占位类型,并且紧随在函数名后面,使用一对尖括号括起来(例如
一旦一个类型参数被指定,你可以用它来定义一个函数的参数类型(例如 swapTwoValues(::) 函数中的参数 a 和 b),或者作为函数的返回类型,还可以用作函数主体中的注释类型。在这些情况下,类型参数会在函数调用时被实际类型所替换。(在上面的 swapTwoValues(::) 例子中,当函数第一次被调用时,T 被 Int 替换,第二次调用时,被 String 替换。)
你可提供多个类型参数,将它们都写在尖括号中,用逗号分开。
4 命名类型参数
在大多数情况下,类型参数具有一个描述性名字,例如 Dictionary<Key, Value> 中的 Key 和 Value,以及 Array
注意 请始终使用大写字母开头的驼峰命名法(例如 T 和 MyTypeParameter)来为类型参数命名,以表明它们是占位类型,而不是一个值。
5 泛型类型
除了泛型函数,Swift 还允许你定义泛型类型。这些自定义类、结构体和枚举可以适用于任何类型,类似于 Array 和 Dictionary。
这部分内容将向你展示如何编写一个名为 Stack (栈)的泛型集合类型。栈是一系列值的有序集合,和 Array 类似,但它相比 Swift 的 Array 类型有更多的操作限制。数组允许在数组的任意位置插入新元素或是删除其中任意位置的元素。而栈只允许在集合的末端添加新的元素(称之为入栈)。类似的,栈也只能从末端移除元素(称之为出栈)。
注意 栈的概念已被 UINavigationController 类用来构造视图控制器的导航结构。你通过调用 UINavigationController 的 pushViewController(:animated:) 方法来添加新的视图控制器到导航栈,通过 popViewControllerAnimated(:) 方法来从导航栈中移除视图控制器。每当你需要一个严格的“后进先出”方式来管理集合,栈都是最实用的模型。
下图展示了一个栈的入栈(push)和出栈(pop)的行为:
- 现在有三个值在栈中。
- 第四个值被压入到栈的顶部。
- 现在有四个值在栈中,最近入栈的那个值在顶部。
- 栈中最顶部的那个值被移除出栈。
- 一个值移除出栈后,现在栈又只有三个值了。
下面展示了如何编写一个非泛型版本的栈,以 Int 型的栈为例:
struct IntStack {
var items = [Int]()
mutating func push(_ item: Int) {
items.append(item)
}
mutating func pop() -> Int {
return items.removeLast()
}
}
这个结构体在栈中使用一个名为 items 的 Array 属性来存储值。Stack 提供了两个方法:push(_:) 和 pop(),用来向栈中压入值以及从栈中移除值。这些方法被标记为 mutating,因为它们需要修改结构体的 items 数组。
上面的 IntStack 结构体只能用于 Int 类型。不过,可以定义一个泛型 Stack 结构体,从而能够处理任意类型的值。
下面是相同代码的泛型版本:
struct Stack<Element> {
var items = [Element]()
mutating func push(_ item: Element) {
items.append(item)
}
mutating func pop() -> Element {
return items.removeLast()
}
}
注意,Stack 基本上和 IntStack 相同,只是用占位类型参数 Element 代替了实际的 Int 类型。这个类型参数包裹在紧随结构体名的一对尖括号里(
Element 为待提供的类型定义了一个占位名。这种待提供的类型可以在结构体的定义中通过 Element 来引用。在这个例子中,Element 在如下三个地方被用作占位符:
- 创建 items 属性,使用 Element 类型的空数组对其进行初始化。
- 指定 push(_:) 方法的唯一参数 item 的类型必须是 Element 类型。
- 指定 pop() 方法的返回值类型必须是 Element 类型。
由于 Stack 是泛型类型,因此可以用来创建 Swift 中任意有效类型的栈,就像 Array 和 Dictionary 那样。
你可以通过在尖括号中写出栈中需要存储的数据类型来创建并初始化一个 Stack 实例。例如,要创建一个 String 类型的栈,可以写成 Stack
var stackOfStrings = Stack<String>()
stackOfStrings.push("uno")
stackOfStrings.push("dos")
stackOfStrings.push("tres")
stackOfStrings.push("cuatro")
// 栈中现在有 4 个字符串
下图展示了 stackOfStrings 如何将这四个值入栈:
移除并返回栈顶部的值 “cuatro”,即将其出栈:
let fromTheTop = stackOfStrings.pop()
// fromTheTop 的值为 "cuatro",现在栈中还有 3 个字符串
下图展示了 stackOfStrings 如何将顶部的值出栈:
6 扩展一个泛型类型
当你扩展一个泛型类型的时候,你并不需要在扩展的定义中提供类型参数列表。原始类型定义中声明的类型参数列表在扩展中可以直接使用,并且这些来自原始类型中的参数名称会被用作原始定义中类型参数的引用。
下面的例子扩展了泛型类型 Stack,为其添加了一个名为 topItem 的只读计算型属性,它将会返回当前栈顶端的元素而不会将其从栈中移除:
extension Stack {
var topItem: Element? {
return items.isEmpty ? nil : items[items.count - 1]
}
}
topItem 属性会返回一个 Element 类型的可选值。当栈为空的时候,topItem 会返回 nil;当栈不为空的时候,topItem 会返回 items 数组中的最后一个元素。
注意,这个扩展并没有定义一个类型参数列表。相反的,Stack 类型已有的类型参数名称 Element,被用在扩展中来表示计算型属性 topItem 的可选类型。
计算型属性 topItem 现在可以用来访问任意 Stack 实例的顶端元素且不移除它:
if let topItem = stackOfStrings.topItem {
print("The top item on the stack is \(topItem).")
}
// 打印 “The top item on the stack is tres.”
7 类型约束
swapTwoValues(::) 函数和 Stack 类型可以作用于任何类型。不过,有的时候如果能将使用在泛型函数和泛型类型中的类型添加一个特定的类型约束,将会是非常有用的。类型约束可以指定一个类型参数必须继承自指定类,或者符合一个特定的协议或协议组合。
例如,Swift 的 Dictionary 类型对字典的键的类型做了些限制。在字典的描述中,字典的键的类型必须是可哈希(hashable)的。也就是说,必须有一种方法能够唯一地表示它。Dictionary 的键之所以要是可哈希的,是为了便于检查字典是否已经包含某个特定键的值。若没有这个要求,Dictionary 将无法判断是否可以插入或者替换某个指定键的值,也不能查找到已经存储在字典中的指定键的值。
为了实现这个要求,一个类型约束被强制加到 Dictionary 的键类型上,要求其键类型必须符合 Hashable 协议,这是 Swift 标准库中定义的一个特定协议。所有的 Swift 基本类型(例如 String、Int、Double 和 Bool)默认都是可哈希的。
当你创建自定义泛型类型时,你可以定义你自己的类型约束,这些约束将提供更为强大的泛型编程能力。抽象概念,例如可哈希的,描述的是类型在概念上的特征,而不是它们的显式类型。
7.1 类型约束语法
你可以在一个类型参数名后面放置一个类名或者协议名,并用冒号进行分隔,来定义类型约束,它们将成为类型参数列表的一部分。对泛型函数添加类型约束的基本语法如下所示(作用于泛型类型时的语法与之相同):
func someFunction<T: SomeClass, U: SomeProtocol>(someT: T, someU: U) {
// 这里是泛型函数的函数体部分
}
上面这个函数有两个类型参数。第一个类型参数 T,有一个要求 T 必须是 SomeClass 子类的类型约束;第二个类型参数 U,有一个要求 U 必须符合 SomeProtocol 协议的类型约束。
7.2 类型约束实践
这里有个名为 findIndex(ofString:in:) 的非泛型函数,该函数的功能是在一个 String 数组中查找给定 String 值的索引。若查找到匹配的字符串,findIndex(ofString:in:) 函数返回该字符串在数组中的索引值,否则返回 nil:
func findIndex(ofString valueToFind: String, in array: [String]) -> Int? {
for (index, value) in array.enumerated() {
if value == valueToFind {
return index
}
}
return nil
}
findIndex(ofString:in:) 函数可以用于查找字符串数组中的某个字符串:
let strings = ["cat", "dog", "llama", "parakeet", "terrapin"]
if let foundIndex = findIndex(ofString: "llama", in: strings) {
print("The index of llama is \(foundIndex)")
}
// 打印 “The index of llama is 2”
如果只能查找字符串在数组中的索引,用处不是很大。不过,你可以用占位类型 T 替换 String 类型来写出具有相同功能的泛型函数 findIndex(::)。
下面展示了 findIndex(ofString:in:) 函数的泛型版本 findIndex(ofString:in:)。请注意这个函数返回值的类型仍然是 Int?,这是因为函数返回的是一个可选的索引数,而不是从数组中得到的一个可选值。需要提醒的是,这个函数无法通过编译,原因会在例子后面说明:
func findIndex<T>(of valueToFind: T, in array:[T]) -> Int? {
for (index, value) in array.enumerated() {
if value == valueToFind {
return index
}
}
return nil
}
上面所写的函数无法通过编译。问题出在相等性检查上,即 “if value == valueToFind”。不是所有的 Swift 类型都可以用等式符(==)进行比较。比如说,如果你创建一个自定义的类或结构体来表示一个复杂的数据模型,那么 Swift 无法猜到对于这个类或结构体而言“相等”意味着什么。正因如此,这部分代码无法保证适用于每个可能的类型 T,当你试图编译这部分代码时会出现相应的错误。
不过,所有的这些并不会让我们无从下手。Swift 标准库中定义了一个 Equatable 协议,该协议要求任何遵循该协议的类型必须实现等式符(==)及不等符(!=),从而能对该类型的任意两个值进行比较。所有的 Swift 标准类型自动支持 Equatable 协议。
任何 Equatable 类型都可以安全地使用在 findIndex(of:in:) 函数中,因为其保证支持等式操作符。为了说明这个事实,当你定义一个函数时,你可以定义一个 Equatable 类型约束作为类型参数定义的一部分:
func findIndex<T: Equatable>(of valueToFind: T, in array:[T]) -> Int? {
for (index, value) in array.enumerated() {
if value == valueToFind {
return index
}
}
return nil
}
findIndex(of:in:) 唯一的类型参数写做 T: Equatable,也就意味着“任何符合 Equatable 协议的类型 T ”。
findIndex(of:in:) 函数现在可以成功编译了,并且可以作用于任何符合 Equatable 的类型,如 Double 或 String:
let doubleIndex = findIndex(of: 9.3, in: [3.14159, 0.1, 0.25])
// doubleIndex 类型为 Int?,其值为 nil,因为 9.3 不在数组中
let stringIndex = findIndex(of: "Andrea", in: ["Mike", "Malcolm", "Andrea"])
// stringIndex 类型为 Int?,其值为 2
8 关联类型
定义一个协议时,有的时候声明一个或多个关联类型作为协议定义的一部分将会非常有用。关联类型为协议中的某个类型提供了一个占位名(或者说别名),其代表的实际类型在协议被采纳时才会被指定。你可以通过 associatedtype 关键字来指定关联类型。
8.1 关联类型实践
下面例子定义了一个 Container 协议,该协议定义了一个关联类型 ItemType:
protocol Container {
associatedtype ItemType
mutating func append(_ item: ItemType)
var count: Int { get }
subscript(i: Int) -> ItemType { get }
}
Container 协议定义了三个任何采纳了该协议的类型(即容器)必须提供的功能:
- 必须可以通过 append(_:) 方法添加一个新元素到容器里。
- 必须可以通过 count 属性获取容器中元素的数量,并返回一个 Int 值。
- 必须可以通过索引值类型为 Int 的下标检索到容器中的每一个元素。
这个协议没有指定容器中元素该如何存储,以及元素必须是何种类型。这个协议只指定了三个任何遵从 Container 协议的类型必须提供的功能。遵从协议的类型在满足这三个条件的情况下也可以提供其他额外的功能。
任何遵从 Container 协议的类型必须能够指定其存储的元素的类型,必须保证只有正确类型的元素可以加进容器中,必须明确通过其下标返回的元素的类型。
为了定义这三个条件,Container 协议需要在不知道容器中元素的具体类型的情况下引用这种类型。Container 协议需要指定任何通过 append(_:) 方法添加到容器中的元素和容器中的元素是相同类型,并且通过容器下标返回的元素的类型也是这种类型。
为了达到这个目的,Container 协议声明了一个关联类型 ItemType,写作 associatedtype ItemType。这个协议无法定义 ItemType 是什么类型的别名,这个信息将留给遵从协议的类型来提供。尽管如此,ItemType 别名提供了一种方式来引用 Container 中元素的类型,并将之用于 append(_:) 方法和下标,从而保证任何 Container 的行为都能够正如预期地被执行。
下面是先前的非泛型的 IntStack 类型,这一版本采纳并符合了 Container 协议:
struct IntStack: Container {
// IntStack 的原始实现部分
var items = [Int]()
mutating func push(_ item: Int) {
items.append(item)
}
mutating func pop() -> Int {
return items.removeLast()
}
// Container 协议的实现部分
typealias ItemType = Int
mutating func append(_ item: Int) {
self.push(item)
}
var count: Int {
return items.count
}
subscript(i: Int) -> Int {
return items[i]
}
}
IntStack 结构体实现了 Container 协议的三个要求,其原有功能也不会和这些要求相冲突。
此外,IntStack 在实现 Container 的要求时,指定 ItemType 为 Int 类型,即 typealias ItemType = Int,从而将 Container 协议中抽象的 ItemType 类型转换为具体的 Int 类型。
由于 Swift 的类型推断,你实际上不用在 IntStack 的定义中声明 ItemType 为 Int。因为 IntStack 符合 Container 协议的所有要求,Swift 只需通过 append(_:) 方法的 item 参数类型和下标返回值的类型,就可以推断出 ItemType 的具体类型。事实上,如果你在上面的代码中删除了 typealias ItemType = Int 这一行,一切仍旧可以正常工作,因为 Swift 清楚地知道 ItemType 应该是哪种类型。
你也可以让泛型 Stack 结构体遵从 Container 协议:
struct Stack<Element>: Container {
// Stack<Element> 的原始实现部分
var items = [Element]()
mutating func push(_ item: Element) {
items.append(item)
}
mutating func pop() -> Element {
return items.removeLast()
}
// Container 协议的实现部分
mutating func append(_ item: Element) {
self.push(item)
}
var count: Int {
return items.count
}
subscript(i: Int) -> Element {
return items[i]
}
}
这一次,占位类型参数 Element 被用作 append(_:) 方法的 item 参数和下标的返回类型。Swift 可以据此推断出 Element 的类型即是 ItemType 的类型。
8.2 通过扩展一个存在的类型来指定关联类型
通过扩展添加协议一致性中描述了如何利用扩展让一个已存在的类型符合一个协议,这包括使用了关联类型的协议。
Swift 的 Array 类型已经提供 append(_:) 方法,一个 count 属性,以及一个接受 Int 类型索引值的下标用以检索其元素。这三个功能都符合 Container 协议的要求,也就意味着你只需简单地声明 Array 采纳该协议就可以扩展 Array,使其遵从 Container 协议。你可以通过一个空扩展来实现这点,正如通过扩展采纳协议中的描述:
extension Array: Container {}
如同上面的泛型 Stack 结构体一样,Array 的 append(_:) 方法和下标确保了 Swift 可以推断出 ItemType 的类型。定义了这个扩展后,你可以将任意 Array 当作 Container 来使用。
8.3 约束关联类型
你可以给协议里的关联类型添加类型注释,让遵守协议的类型必须遵循这个约束条件。例如,下面的代码定义了一个 Item 必须遵循 Equatable 的 Container 类型:
protocol Container {
associatedtype Item: Equatable
mutating func append(_ item: Item)
var count: Int { get }
subscript(i: Int) -> Item { get }
}
为了遵守了 Container 协议,Item 类型也必须遵守 Equatable 协议。
9 泛型 Where 语句
类型约束让你能够为泛型函数,下标,类型的类型参数定义一些强制要求。
为关联类型定义约束也是非常有用的。你可以在参数列表中通过 where 子句为关联类型定义约束。你能通过 where 子句要求一个关联类型遵从某个特定的协议,以及某个特定的类型参数和关联类型必须类型相同。你可以通过将 where 关键字紧跟在类型参数列表后面来定义 where 子句,where 子句后跟一个或者多个针对关联类型的约束,以及一个或多个类型参数和关联类型间的相等关系。你可以在函数体或者类型的大括号之前添加 where 子句。
下面的例子定义了一个名为 allItemsMatch 的泛型函数,用来检查两个 Container 实例是否包含相同顺序的相同元素。如果所有的元素能够匹配,那么返回 true,否则返回 false。
被检查的两个 Container 可以不是相同类型的容器(虽然它们可以相同),但它们必须拥有相同类型的元素。这个要求通过一个类型约束以及一个 where 子句来表示:
func allItemsMatch<C1: Container, C2: Container>
(_ someContainer: C1, _ anotherContainer: C2) -> Bool
where C1.ItemType == C2.ItemType, C1.ItemType: Equatable {
// 检查两个容器含有相同数量的元素
if someContainer.count != anotherContainer.count {
return false
}
// 检查每一对元素是否相等
for i in 0..<someContainer.count {
if someContainer[i] != anotherContainer[i] {
return false
}
}
// 所有元素都匹配,返回 true
return true
}
这个函数接受 someContainer 和 anotherContainer 两个参数。参数 someContainer 的类型为 C1,参数 anotherContainer 的类型为 C2。C1 和 C2 是容器的两个占位类型参数,函数被调用时才能确定它们的具体类型。
这个函数的类型参数列表还定义了对两个类型参数的要求:
- C1 必须符合 Container 协议(写作 C1: Container)。
- C2 必须符合 Container 协议(写作 C2: Container)。
- C1 的 ItemType 必须和 C2 的 ItemType类型相同(写作 C1.ItemType == C2.ItemType)。
- C1 的 ItemType 必须符合 Equatable 协议(写作 C1.ItemType: Equatable)。
第三个和第四个要求被定义为一个 where 子句,写在关键字 where 后面,它们也是泛型函数类型参数列表的一部分。
这些要求意味着:
- someContainer 是一个 C1 类型的容器。
- anotherContainer 是一个 C2 类型的容器。
- someContainer 和 anotherContainer 包含相同类型的元素。
- someContainer 中的元素可以通过不等于操作符(!=)来检查它们是否彼此不同。
第三个和第四个要求结合起来意味着 anotherContainer 中的元素也可以通过 != 操作符来比较,因为它们和 someContainer 中的元素类型相同。
这些要求让 allItemsMatch(::) 函数能够比较两个容器,即使它们的容器类型不同。
allItemsMatch(::) 函数首先检查两个容器是否拥有相同数量的元素,如果它们的元素数量不同,那么一定不匹配,函数就会返回 false。
进行这项检查之后,通过 for-in 循环和半闭区间操作符(..<)来迭代每个元素,检查 someContainer 中的元素是否不等于 anotherContainer 中的对应元素。如果两个元素不相等,那么两个容器不匹配,函数返回 false。
如果循环体结束后未发现任何不匹配的情况,表明两个容器匹配,函数返回 true。
下面演示了 allItemsMatch(::) 函数的使用:
var stackOfStrings = Stack<String>()
stackOfStrings.push("uno")
stackOfStrings.push("dos")
stackOfStrings.push("tres")
var arrayOfStrings = ["uno", "dos", "tres"]
if allItemsMatch(stackOfStrings, arrayOfStrings) {
print("All items match.")
} else {
print("Not all items match.")
}
// 打印 “All items match.”
上面的例子创建了一个 Stack 实例来存储一些 String 值,然后将三个字符串压入栈中。这个例子还通过数组字面量创建了一个 Array 实例,数组中包含同栈中一样的三个字符串。即使栈和数组是不同的类型,但它们都遵从 Container 协议,而且它们都包含相同类型的值。因此你可以用这两个容器作为参数来调用 allItemsMatch(::) 函数。在上面的例子中,allItemsMatch(::) 函数正确地显示了这两个容器中的所有元素都是相互匹配的。
10 具有泛型 where 子句的扩展
你也可以使用泛型 where 子句作为扩展的一部分。基于以前的例子,下面的示例扩展了泛型 Stack 结构体,添加一个 isTop(_:) 方法。
extension Stack where Element: Equatable {
func isTop(_ item: Element) -> Bool {
guard let topItem = items.last else {
return false
}
return topItem == item
}
}
这个新的 isTop(:) 方法首先检查这个栈是不是空的,然后比较给定的元素与栈顶部的元素。如果你尝试不用泛型 where 子句,会有一个问题:在 isTop(:) 里面使用了 == 运算符,但是 Stack 的定义没有要求它的元素是符合 Equatable 协议的,所以使用 == 运算符导致编译时错误。使用泛型 where 子句可以为扩展添加新的条件,因此只有当栈中的元素符合 Equatable 协议时,扩展才会添加 isTop(_:) 方法。
以下是 isTop(_:) 方法的调用方式:
if stackOfStrings.isTop("tres") {
print("Top element is tres.")
} else {
print("Top element is something else.")
}
// 打印 "Top element is tres."
如果尝试在其元素不符合 Equatable 协议的栈上调用 isTop(_:) 方法,则会收到编译时错误。
struct NotEquatable { }
var notEquatableStack = Stack<NotEquatable>()
let notEquatableValue = NotEquatable()
notEquatableStack.push(notEquatableValue)
notEquatableStack.isTop(notEquatableValue) // 报错
你可以使用泛型 where 子句去扩展一个协议。基于以前的示例,下面的示例扩展了 Container 协议,添加一个 startsWith(_:) 方法。
extension Container where Item: Equatable {
func startsWith(_ item: Item) -> Bool {
return count >= 1 && self[0] == item
}
}
这个 startsWith(:) 方法首先确保容器至少有一个元素,然后检查容器中的第一个元素是否与给定的元素相等。任何符合 Container 协议的类型都可以使用这个新的 startsWith(:) 方法,包括上面使用的栈和数组,只要容器的元素是符合 Equatable 协议的。
if [9, 9, 9].startsWith(42) {
print("Starts with 42.")
} else {
print("Starts with something else.")
}
// 打印 "Starts with something else."
上述示例中的泛型 where 子句要求 Item 符合协议,但也可以编写一个泛型 where 子句去要求 Item 为特定类型。例如:
extension Container where Item == Double {
func average() -> Double {
var sum = 0.0
for index in 0..<count {
sum += self[index]
}
return sum / Double(count)
}
}
print([1260.0, 1200.0, 98.6, 37.0].average())
// 打印 "648.9"
此示例将一个 average() 方法添加到 Item 类型为 Double 的容器中。此方法遍历容器中的元素将其累加,并除以容器的数量计算平均值。它将数量从 Int 转换为 Double 确保能够进行浮点除法。
就像可以在其他地方写泛型 where 子句一样,你可以在一个泛型 where 子句中包含多个条件作为扩展的一部分。用逗号分隔列表中的每个条件。
11 具有泛型 Where 子句的关联类型
你可以在关联类型后面加上具有泛型 where 的字句。例如,建立一个包含迭代器(Iterator)的容器,就像是标准库中使用的 Sequence 协议那样。你应该这么写:
protocol Container {
associatedtype Item
mutating func append(_ item: Item)
var count: Int { get }
subscript(i: Int) -> Item { get }
associatedtype Iterator: IteratorProtocol where Iterator.Element == Item
func makeIterator() -> Iterator
}
迭代器(Iterator)的泛型 where 子句要求:无论迭代器是什么类型,迭代器中的元素类型,必须和容器项目的类型保持一致。makeIterator() 则提供了容器的迭代器的访问接口。
一个协议继承了另一个协议,你通过在协议声明的时候,包含泛型 where 子句,来添加了一个约束到被继承协议的关联类型。例如,下面的代码声明了一个 ComparableContainer 协议,它要求所有的 Item 必须是 Comparable 的。
protocol ComparableContainer: Container where Item: Comparable { }
12 泛型下标
下标能够是泛型的,他们能够包含泛型 where 子句。你可以把占位符类型的名称写在 subscript 后面的尖括号里,在下标代码体开始的标志的花括号之前写下泛型 where 子句。例如:
extension Container {
subscript<Indices: Sequence>(indices: Indices) -> [Item]
where Indices.Iterator.Element == Int {
var result = [Item]()
for index in indices {
result.append(self[index])
}
return result
}
}
这个 Container 协议的扩展添加了一个下标方法,接收一个索引的集合,返回每一个索引所在的值的数组。这个泛型下标的约束如下:
这个 Container 协议的扩展添加了一个下标:下标是一个序列的索引,返回的则是索引所在的项目的值所构成的数组。这个泛型下标的约束如下:
- 在尖括号中的泛型参数 Indices,必须是符合标准库中的 Sequence 协议的类型。
- 下标使用的单一的参数,indices,必须是 Indices 的实例。
- 泛型 where 子句要求 Sequence(Indices)的迭代器,其所有的元素都是 Int 类型。这样就能确保在序列(Sequence)中的索引和容器(Container)里面的索引类型是一致的。
综合一下,这些约束意味着,传入到 indices 下标,是一个整型的序列。 (译者:原来的 Container 协议,subscript 必须是 Int 型的,扩展中新的 subscript,允许下标是一个的序列,而非单一的值。)
内存安全性
默认情况下,Swift 会阻止你代码中发生的不安全行为。比如说,Swift 会保证在使用前就初始化,内存在变量释放后这块内存就不能再访问了,以及数组会检查越界错误。
Swift 还通过要求标记内存位置来确保代码对内存有独占访问权,以确保了同一内存多访问时不会冲突。由于 Swift 自动管理内存,大部份情况下你根本不需要考虑访问内存的事情。总之,了解一下什么情况下会潜在导致冲突是一件很重要的事情,这样你就可以避免写出对内存访问冲突的代码了。如果你的代码确实包含冲突,你就会得到编译时或运行时错误。
1 了解内存访问冲突
内存访问会在你做一些比如设置变量的值或者传递一个实际参数给函数的时候发生。比如说,下面的代码同时包含了读取访问和写入访问:
// A write access to the memory where one is stored.
var one = 1
// A read access from the memory where one is stored.
print("We're number \(one)!")
内存访问冲突会在你的代码不同地方同一时间尝试访问同一块内存时发生。在同一时间多处访问同一块内存会产生不可预料或者说不一致的行为。在 Swift 中,有好几种方式来修改跨越多行代码的值,从而可以在访问值的中间进行它自身的修改。
你可以想象一个类似的问题比如你是如何更新一张写在纸上的预算。更新预算是一个两步过程:首先你添加项目的名字和价格,然后你改变总价来显示当前列表中的变化。在更新的前后,你可以读取任何预算信息并且得到正确的结果,图例如下:
当你添加项目到预算时,它处在一个临时的状态,这是一个不可用的状态因为总价还没有更新来显示最新的价格。在添加新项目的过程中读取总价就会得到错误的信息。
这个例子也展示了你在修复内存访问冲突时可能会遭遇的挑战:有时多种修复冲突的方式会产生不同的结果,并且通常也不会明显哪个结果就是正确的。在这个例子中,基于你想要原本的总价还是更新后的总价,要么是 $5 要么是 $320 都可能是正确的。在你修复内存访问冲突之前,你必须决定想要哪一种。
1.1 典型的内存访问
在访问冲突上下文中有三种典型的内存访问需要考虑:不论访问是读取还是写入,在访问过程中,以及内存地址被访问。具体来说,冲突会在你用两个访问并满足下列条件时发生:
- 至少一个是写入访问;
- 它们访问的是同一块内存;
- 它们的访问时间重叠。
读和写的区别通常显而易见:写入访问改变了内存,但读取访问不会。内存地址则指向被访问的东西——比如说,变量、常量或者属性。访问内存的时间要么是即时的,要么是长时间的。
如果一个访问在启动后其他代码不能执行直到它结束后才能,那么这个访问就是即时的。基于它们的特性,两个即时访问不能同时发生。大多数内存访问都是即时的。比如,下面列出的所有读写访问都是即时的:
func oneMore(than number: Int) -> Int {
return number + 1
}
var myNumber = 1
myNumber = oneMore(than: myNumber)
print(myNumber)
// Prints "2"
总之,还有有很多访问内存的方法,比如被称作长时访问的,跨越其他代码执行过程。长时访问和即时访问的不同之处在于长时访开始后在它结束之前其他代码依旧可以运行,这就是所谓的重叠。长时访问可以与其他长时访问以及即时访问重叠。
重叠访问主要是出现在使用了输入输出形式参数的函数以及方法或者结构体中的异变方法。特定种类的使用长时访问的 Swift 代码在下文详述。
2 输入输出形式参数的访问冲突
拥有长时写入访问到所有自身输入输出形式参数的函数。对输入输出形式参数的写入访问会在所有非输入输出形式参数计算之后开始,并持续到整个函数调用结束。如果有多个输入输出形式参数,那么写入访问会以形式参数出现的顺序开始。
这种长时写入访问的一个后果就是你不能访问作为输入输出传递的原本变量,就算生效范围和访问控制可能会允许你这么做——任何对原变量的访问都会造成冲突,比如说:
var stepSize = 1
func increment(_ number: inout Int) {
number += stepSize
}
increment(&stepSize)
// Error: conflicting accesses to stepSize
在上面的代码中, stepSize 是一个全局变量,它通常可以在 increment(_:) 中可以访问。总之, stepSize 的读取访问与 number 的写入访问重叠了。入下图所示, number 和 stepSize 引用的是同一内存地址。读取和写入访问引用同一内存并且重叠,产生了冲突。
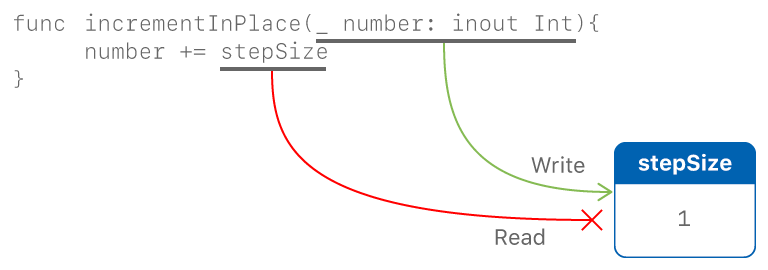
一种解决这个冲突的办法是显式地做一个 stepSize 的拷贝:
// Make an explicit copy.
var copyOfStepSize = stepSize
increment(©OfStepSize)
// Update the original.
stepSize = copyOfStepSize
// stepSize is now 2
// stepSize is now 2
当你在调用 increment(_:) 之前给 stepSize 了一份之后,显然 copyOfStepSizeis 基于当前的步长增加了。读取访问在写入访问开始前结束,所以不会再有冲突。
输入输出形式参数的长时写入访问的另一个后果是传入一个单独的变量作为实际形式参数给同一个函数的多个输入输出形式参数产生冲突。比如:
func balance(_ x: inout Int, _ y: inout Int) {
let sum = x + y
x = sum / 2
y = sum - x
}
var playerOneScore = 42
var playerTwoScore = 30
balance(&playerOneScore, &playerTwoScore) // OK
balance(&playerOneScore, &playerOneScore)
// Error: Conflicting accesses to playerOneScore
上边 balance(::) 修改它的两个形式参数将它们的总数进行平均分配。用 playerOneScore 和 playerTwoScore 作为实际参数不会产生冲突——一共有两个写入访问在同一时间重叠,但它们访问的是不同的内存地址。相反,传入 playerOneScore 作为两个形式参数的值则产生冲突,因为它尝试执行两个写入访问到同一个内存地址且是在同一时间执行。
3 在方法中对 self 的访问冲突
结构体中的异变方法可以在方法调用时对 self 进行写入访问。比如说想象一个每个玩家都有生命值的游戏,当玩家受伤时降低生命值,以及一个能量值,它在使用技能时降低。
struct Player {
var name: String
var health: Int
var energy: Int
static let maxHealth = 10
mutating func restoreHealth() {
health = Player.maxHealth
}
}
在上面 restoreHealth() 方法中,对 self 的写入访问在方法一开始就启动然后结束于方法返回。在这种情况下,在 restoreHealth() 中没有其他代码可能会重叠访问 Player 实例中的属性。下面的 shareHealth(with:) 方法则接收另一个 Player 实例作为输入输出形式参数,为重叠访问创建了可能性:
extension Player {
mutating func shareHealth(with teammate: inout Player) {
balance(&teammate.health, &health)
}
}
var oscar = Player(name: "Oscar", health: 10, energy: 10)
var maria = Player(name: "Maria", health: 5, energy: 10)
oscar.shareHealth(with: &maria) // OK
在上面的例子中,调用 Oscar 玩家的 shareHealth(with:) 方法分享血条给 Maria 玩家不会造成冲突。在方法调用的过程中只有一个写入访问到 oscar 因为 oscar 是异变方法中 self 值,并且在同一时间内只有一个写入访问到 maria 因为 maria 是以输入输出形式参数传递的。如下面的图例所示,他们访问了内存中不同的地址。就算他们的写入访问是同时发生的,但不会冲突。
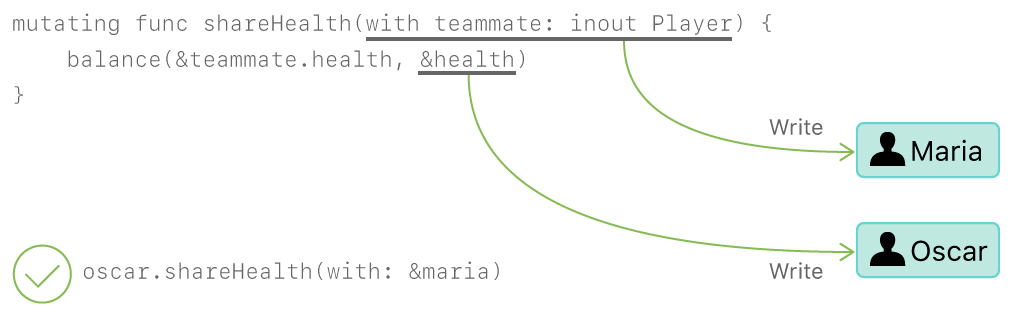
总之,如果你把 oscar 作为实际参数传递给 shareHealth(with:) ,就出现了冲突:
oscar.shareHealth(with: &oscar)
// Error: conflicting accesses to oscar
异变方法在方法的自行过程中需要写入访问到 self ,并且输入输出形式参数同时也需要写入访问到 teammate 。在方法中, self 和 teammate 实际上引用自同一内存地址——如图所示。这两个写入访问引用到了同一个地址并重叠,产生冲突。
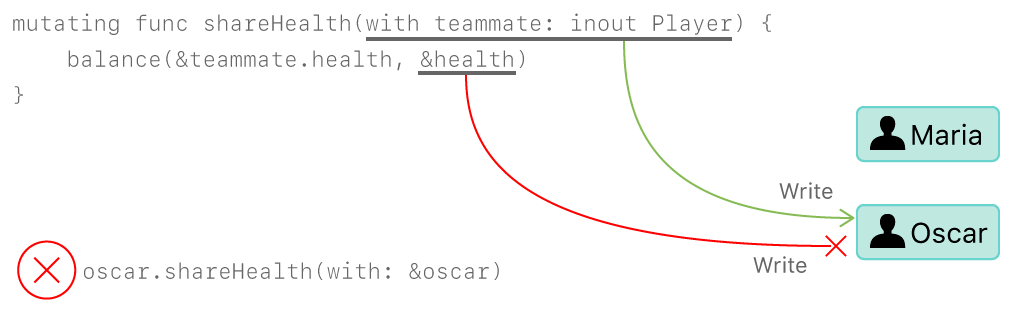
4 属性的访问冲突
像是结构体、元组以及枚举这些类型都是由独立值构成,比如结构体的属性或者元组的元素。由于这些都是值类型,改变任何一个值都会改变整个类型,意味着读或者写访问到这些属性就需要对整个值进行读写访问。比如说,对元组的元素进行重叠写入访问就会产生冲突:
var playerInformation = (health: 10, energy: 20)
balance(&playerInformation.health, &playerInformation.energy)
// Error: conflicting access to properties of playerInformation
在上边例子中,在同一元组的元素上调用 balance(::) 产生冲突是因为对 playerInformation 产生了重叠写入访问。 playerInformation.health 和 playerInformation.energy 作为输入输出形式参数传入,这就意味着 balance(::) 在函数调用的过程中对他们产生写入访问。在这两种情况下,对元组元素的写入访问需要整个元组的写入访问。也就是说 playerInformation 在调用过程中有两个写入访问重叠,导致冲突。
下面的代码显示了对全局变量结构体属性的重叠写入访问,导致同样的错误。
var holly = Player(name: "Holly", health: 10, energy: 10)
balance(&holly.health, &holly.energy) // Error
实际上,大多数对结构体属性的访问可以安全的重叠。比如果,如果上边变量 holly 变成局部变量而不是全局变量,那么编译器就可以保证重叠访问结构体的存储属性是安全的:
func someFunction() {
var oscar = Player(name: "Oscar", health: 10, energy: 10)
balance(&oscar.health, &oscar.energy) // OK
}
在上边的例子中,Oscar 的血条和能量作为两个输入输出形式参数传递给了 balance(::) 。编译器可以证明内存安全得以保证是因为两个存储属性不会以任何形式交互。
对重叠访问结构体的属性进行限制并不总是必要才能保证内存安全性。内存安全性是一个需要的保证,但独占访问是比内存安全更严格的要求——也就是说某些代码保证了内存安全性,尽管它违反了内存的独占访问。如果编译器可以保证非独占访问内存仍然是安全的 Swift 就允许这些内存安全的代码。具体来说,如果下面的条件可以满足就说明重叠访问结构体的属性是安全的:
- 你只访问实例的存储属性,不是计算属性或者类属性;
- 结构体是局部变量而非全局变量;
- 结构体要么没有被闭包捕获要么只被非逃逸闭包捕获。
访问控制
访问控制限制其他源文件和模块对你的代码的访问。这个特性允许你隐藏代码的实现细节,并指定一个偏好的接口让其他代码可以访问和使用。
你可以给特定的单个类型 (类,结构体和枚举)设置访问级别,比如说属性、方法、初始化器以及属于那些类型的下标。协议可以限制在一定的范围内使用,就像全局常量,变量,函数那样。
除了提供各种级别的访问控制,Swift 为典型场景提供默认的访问级别,减少了显式指定访问控制级别的需求。 事实上,如果你编写单目标应用程序,你可能根本不需要显式指定访问控制级别。
1. 模块和源文件
Swift 的访问控制模型基于模块和源文件的概念。
模块是单一的代码分配单元——一个框架或应用程序会作为的独立的单元构建和发布并且可以使用 Swift 的 import 关键字导入到另一个模块。
Xcode 中的每个构建目标(例如应用程序包或框架)在 Swift 中被视为一个独立的模块。 如果你将应用程序的代码作为独立的框架组合在一起——或许可以在多个应用程序中封装和重用该代码——那么当在一个应用程序中导入和使用时,在该框架中定义的所有内容都将作为独立模块的一部分 ,或是当它在另一个框架中使用时。
源文件是一个模块中的单个 Swift 源代码文件(实际上,是一个应用程序或是框架中的单个文件)。虽然通常在单独源文件中定义单个类型,但是一个源文件可以包含多个类型。函数等的定义。
2. 访问级别
Swift 为代码的实体提供个五个不同的访问级别。这些访问级别和定义实体的源文件相关,并且也和源文件所属的模块相关。
Open 访问 和 public 访问 允许实体被定义模块中的任意源文件访问,同样可以被另一模块的源文件通过导入该定义模块来访问。在指定框架的公共接口时,通常使用 open 或 public 访问。 open 访问仅适用于类和类成员,它与 public 访问区别如下:
public 访问,或任何更严格的访问级别的类,只能在其定义模块中被继承。
public 访问,或任何更严格访问级别的类成员,只能被其定义模块的子类重写。
open 类可以在其定义模块中被继承,也可在任何导入定义模块的其他模块中被继承。
open 类成员可以被其定义模块的子类重写,也可以被导入其定义模块的任何模块重写。
Internal 访问 允许实体被定义模块中的任意源文件访问,但不能被该模块之外的任何源文件访问。通常在定义应用程序或是框架的内部结构时使用。
File-private 访问 将实体的使用限制于当前定义源文件中。当一些细节在整个文件中使用时,使用 file-private 访问隐藏特定功能的实现细节。
private 访问 将实体的使用限制于封闭声明中。当一些细节仅在单独的声明中使用时,使用 private 访问隐藏特定功能的实现细节。
open 访问是最高的(限制最少)访问级别,private 是最低的(限制最多)访问级别。
显式地标记类为 open 意味着你考虑过其他模块使用该类作为父类对代码的影响,并且相应地设计了类的代码。
2.1 访问级别的指导准则
Swift 中的访问级别遵循一个总体指导准则:实体不可以被更低(限制更多)访问级别的实体定义。
例如:
- 一个 public 的变量其类型的访问级别不能是 internal, file-private 或是 private,因为在使用 public 变量的地方可能没有这些类型的访问权限。
- 一个函数不能比它的参数类型和返回类型访问级别高,因为函数可以使用的环境而其参数和返回类型却不能使用。
如果你不指明访问级别的话,你的代码中的所有实体(以及本章后续提及的少数例外)都会默认为 internal 级别。因此,大多数情况下你不需要明确指定访问级别。
当你编写一个简单的单目标应用时,你的应用中的代码都是在本应用中使用的并且不会在应用模块之外使用。默认的 internal 访问级别已经匹配了这种需求。因此,你不需要明确自定访问级别。但你可能会将代码的一些部分标注为 file private 或private 以对模块中的其他代码隐藏它们的实现细节。
2.2 框架的访问级别
当你开发一个框架时,将该框架的面向公众的接口标注为 open 或 public,这样它就能被其他的模块看到或访问,比如导入该框架的应用。这个面相公众的接口就是该框架的应用编程接口(API)。
2.3 单元测试目标的访问级别
当你编写一个简单的单目标应用时,你的应用中的代码都是在本应用中使用的并且不会在应用模块之外使用。默认的 internal 访问级别已经匹配了这种需求。因此,你不需要明确自定访问级别。但你可能会将代码的一些部分标注为 file private 或private 以对模块中的其他代码隐藏它们的实现细节。
3 访问控制语法
通过在实体的引入之前添加 open , public , internal , fileprivate ,或 private 修饰符来定义访问级别。
public class SomePublicClass {}
internal class SomeInternalClass {}
fileprivate class SomeFilePrivateClass {}
private class SomePrivateClass {}
public var somePublicVariable = 0
internal let someInternalConstant = 0
fileprivate func someFilePrivateFunction() {}
private func somePrivateFunction() {}
除非已经标注,否则都会使用默认的 internal 访问级别,这一点在默认访问级别一节已经说明。这意味着 SomeInternalClass 和 someInternalConstant 不需要指明访问级别也会是 internal 级别。
4 自定类型
如果你想给自定类型指明访问级别,那就在定义时指明。只要访问级别允许,新类型就可以被使用。例如,你定义了一个 file-private 的类,它就只能在定义文件中被当作属性类型、函数参数或返回类型使用。
类型的访问控制级别也会影响它的成员的默认访问级别(它的属性,方法,初始化方法,下标)。如果你将类型定义为 private 或 file private 级别,那么它的成员的默认访问级别也会是 private 或file private。如果你将类型定义为 internal 或 public级别(或直接使用默认级别而不显式指出),那么它的成员的默认访问级别会是 internal 。
public 的类型默认拥有 internal 级别的成员,而不是 public。如果你想让其中的一个类型成员是 public 的,你必须按实示例代码指明。这个要求确保类型的面向公众的 API 是你选择的,并且可以避免将类型的内部工作细节公开成 API 的失误。
public class SomePublicClass { // explicitly public class
public var somePublicProperty = 0 // explicitly public class member
var someInternalProperty = 0 // implicitly internal class member
fileprivate func someFilePrivateMethod() {} // explicitly file-private class member
private func somePrivateMethod() {} // explicitly private class member
}
class SomeInternalClass { // implicitly internal class
var someInternalProperty = 0 // implicitly internal class member
fileprivate func someFilePrivateMethod() {} // explicitly file-private class member
private func somePrivateMethod() {} // explicitly private class member
}
fileprivate class SomeFilePrivateClass { // explicitly file-private class
func someFilePrivateMethod() {} // implicitly file-private class member
private func somePrivateMethod() {} // explicitly private class member
}
private class SomePrivateClass { // explicitly private class
func somePrivateMethod() {} // implicitly private class member
}
4.1 元组类型
元组类型的访问级别是所有类型里最严格的。例如,如果你将两个不同类型的元素组成一个元组,一个元素的访问级别是 internal,另一个是 private,那么这个元组类型是 private 级别的。
元组类型不像类、结构体、枚举和函数那样有一个单独的定义。元组类型的访问级别会在使用的时候被自动推断出来,不需要显式指明。
4.2 函数类型
函数类型的访问级别由函数成员类型和返回类型中的最严格访问级别决定。如果函数的计算访问级别与上下文环境默认级别不匹配,你必须在函数定义时显式指出。
下面的例子定义了一个称为 someFunction() 的全局函数,而没有指明它的访问级别。你或许以为它会是默认的 “internal” 级别,但事实不是这样。这样的 someFuniction()是无法通过编译的:
func someFunction() -> (SomeInternalClass, SomePrivateClass) {
// function implementation goes here
}
这个函数的返回类型是一个由两个在自定义类型里定义的类组成的元组。其中一个类是 “internal” 级别的,另一个是 “private”。因此,这个元组的访问级别是“private”(元组成员的最严级别)。
由于返回类型是 private 级别的,你必须使用 private 修饰符使其合法:
private func someFunction() -> (SomeInternalClass, SomePrivateClass) {
// function implementation goes here
}
使用 public 或 internal 标注 someFunction() 的定义是无效的,使用默认的 internal 也是无效的,7的函数可能无法访问到 private 的函数返回值。
4.3 枚举类型
枚举中的独立成员自动使用该枚举类型的访问级别。你不能给独立的成员指明一个不同的访问级别。
在下面的例子中 CompassPoint 有一个指明的“public”级别。里面的成员 north , south , east , 和 west因此是“public”:
public enum CompassPoint {
case north
case south
case east
case west
}
4.3.1 原始值和关联值
枚举定义中的原始值和关联值使用的类型必须有一个不低于枚举的访问级别。例如,你不能使用一个 private 类型作为一个 internal 级别的枚举类型中的原始值类型。
4.4 嵌套类型
private 级别的类型中定义的嵌套类型自动为 private 级别。fileprivate 级别的类型中定义的嵌套类型自动为 fileprivate 级别。public 或 internal 级别的类型中定义的嵌套类型自动为 internal 级别。如果你想让嵌套类型是 public 级别的,你必须将其显式指明为 public。
4.5 子类
你可以继承任何类只要是在当前可以访问的上下文环境中。但子类不能高于父类的访问级别,例如,你不能写一个 internal 父类的 public 子类。
而且,你可以重写任何类成员(方法,属性,初始化器或下标),只要是在确定的访问域中是可见的。
重写可以让一个继承类成员比它的父类中的更容易访问。在下例中,public 级别的类 A 有一个 fileprivate 级别的 someMethod() 函数。 B 是 A 的子类,有一个降低的“internal”级别。但是,类 B 对 someMethod() 函数进行了重写即改为“internal”级别,这比 someMethod() 的原本实现级别更高:
public class A {
fileprivate func someMethod() {}
}
internal class B: A {
override internal func someMethod() {}
}
子类成员调用父类中比子类更低访问级别的成员,只要这个调用发生在一个允许的访问级别上下文中(即对 fileprivate 成员的调用要求父类在同一个源文件中,对 internal 成员的调用要求父类在同一个模块中):
public class A {
fileprivate func someMethod() {}
}
internal class B: A {
override internal func someMethod() {
super.someMethod()
}
}
因为父类 A 和子类 B 定义在同一个源文件中,那么 B 类可以在 someMethod() 中调用父类的 someMethod() 。
5 常量,变量,属性和下标
常量、变量、属性不能拥有比它们类型更高的访问级别。例如,你不能写一个public 的属性而它的类型是 private 的。类似的,下标也不能拥有比它的索引类型和返回类型更高的访问级别。
如果常量、变量、属性或下标由private类型组成,那么常量、变量、属性或下标也要被标注为 private
private var privateInstance = SomePrivateClass()
6 Getters 和 Setters
常量、变量、属性和下标的 getter 和 setter 自动接收它们所属常量、变量、属性和下标的访问级别。
你可以给 setter 函数一个比相对应 getter 函数更低的访问级别以限制变量、属性、下标的读写权限。你可以通过在 var 和 subscript 的置入器之前书写 fileprivate(set) , private(set) , 或 internal(set) 来声明更低的访问级别。
这个规则应用于存储属性和计算属性。即使你没有给一个存储属性书写一个明确的 getter 和 setter,Swift 会为你合成一个 getter 和 setter 以访问到存储属性的隐式存储。使用 fileprivate(set) , private(set) 和 internal(set) 可以改变这个合成的 setter 的访问级别,同样也可以改变计算属性的访问级别。
下面的例子定义了一个称为 TrackedString 的结构体,它保持追踪一个字符串属性的修改次数:
struct TrackedString {
private(set) var numberOfEdits = 0
var value: String = "" {
didSet {
numberOfEdits += 1
}
}
}
TrackedString 结构体定义了一个可存储字符串的属性 value ,它又一个初始值 “” (空字符串)。这个结构图同样定义了一个可存储整数的属性 numberOfEdits ,它被用于记录 value 的修改次数。这个记录由 value 属性中的didset属性实现,它会增加 numberOfEdits 的值一旦 value 被设为一个新值。
TrackedString 结构体和 value 属性都没有显式指出访问级别修饰符,因此它们都遵循默认的 internal 级别。 numberOfEdits 属性的访问级别已经标注为 private(set) 以说明这个属性的 getter 是默认的 internal 级别,但是这个属性只能被 TrackedString 内的代码设置。这允许 TrackedString 在内部修改 numberOfEdits 属性,而且可以展示这个属性作为一个只读属性当在结构体定义之外使用时——包括 TrackedString 的扩展。
如果你创建了一个 TrackedString 的实例并修改了几次字符串的值,你可以看到 numberOfEdits 属性的值更新到匹配修改的次数:
var stringToEdit = TrackedString()
stringToEdit.value = "This string will be tracked."
stringToEdit.value += " This edit will increment numberOfEdits."
stringToEdit.value += " So will this one."
print("The number of edits is \(stringToEdit.numberOfEdits)")
// Prints "The number of edits is 3"
尽管你可以从别的源文件中询问到 numberOfEdits 属性的当前值,但你不能从别的源文件中修改该属性的值。这个限制保护了 TrackedString 编辑追踪功能的实现细节,并同时为该功能的一个方面提供方便的访问。
你若有必要也可以显式指明 getter 和 setter方法。下面的例子提供了一个定义为 public 级别的 TrackedString 结构体。结构体成员(包括 numberOfEdits 属性)因此有一个默认的 internal 级别。你可以设置 numberOfEdits 属性的getter方法为 public,setter 方法为 private 级别,通过结合 public 和 private(set) 访问级别修饰符:
public struct TrackedString {
public private(set) var numberOfEdits = 0
public var value: String = "" {
didSet {
numberOfEdits += 1
}
}
public init() {}
}
7 初始化器
我们可以给自定义初始化方法设置一个低于或等于它的所属的类的访问级别。唯一的例外是必要初始化器(定义在必要初始化器)。必要初始化器必须和它所属类的访问级别一致。
就像函数和方法的参数一样,初始化器的参数类型不能比初始化方法的访问级别还低。
7.1 默认初始化器
正如默认初始化器中描述的那样,Swift 自动为任何结构体和类提供一个无参数的默认初始化方法,以给它的属性提供默认值但不会提供给初始化器自身。
默认初始化方法与所属类的访问级别一致,除非该类型定义为 public 。如果一个类定义为 public ,那么默认初始化方法为 internal 级别。如果你想一个 public 类可以被一个无参初始化器初始化当在另一个模块中使用时,你必须显式提供一个 public 的无参初始化方法。
7.2 结构体的默认成员初始化器
如果结构体的存储属性时 private 的,那么它的默认成员初始化方法就是 private 级别。如果结构体的存储属性时 file private 的,那么它的默认成员初始化方法就是 file private 级别。否则就是默认的 internal 级别。正如以上默认初始化的描述,如果你想在另一个模块中使用结构体的成员初始化方法,你必须提供在定义中提供一个 public 的成员初始化方法。
8 协议
如果你想给一个协议类型分配一个显式的访问级别,那就在定义时指明。这让你创建的协议可以在一个明确的访问上下文中被接受。
协议定义中的每一个要求的访问级别都自动设为与该协议相同。你不能将一个协议要求的访问级别设为与协议不同。这保证协议的所有要求都能被接受该协议的类型所见。
注意如果你定义了一个 public 的协议,该协议的规定要求在被实现时拥有一个 public 的访问级别。这个行为不同于其他类型,一个 public 的类型的成员时 internal 访问级别。
8.1 协议继承
如果你定义了一个继承已有协议的协议,这个新协议最高与它继承的协议访问级别一致。例如你不能写一个 public 的协议继承一个 internal 的协议。
8.2 协议遵循
类型可以遵循更低访问级别的协议。例如,你可以定义一个可在其他模块使用的 public 类型,但它就只能在定义模块中使用如果遵循一个 internal 的协议。
遵循了协议的类的访问级别取这个协议和该类的访问级别的最小者。如果这个类型是 public 级别的,它所遵循的协议是 internal 级别,这个类型就是 internal 级别的。
当你写或是扩张一个类型以遵循协议时,你必须确保该类按协议要求的实现方法与该协议的访问级别一致。例如,一个 public 的类遵循一个 internal 协议,该类的方法实现至少是 “internal” 的。
9 扩展
你可以在任何可访问的上下文环境中对类、结构体、或枚举进行扩展。在扩展中添加的任何类型成员都有着被扩展类型相同的访问权限。如果你扩展一个公开或者内部类型,你添加的任何新类型成员都拥有默认的内部访问权限。如果你扩展一个文件内私有的类型,你添加的任何新类型成员都拥有默认的私有访问权限。如果你扩展一个私有类型,你添加的任何新类型成员都拥有默认的私有访问权限。
或者,你可以显式标注扩展的访问级别(例如, private extension )已给扩展中的成员设置新的默认访问级别。这个默认同样可以在扩展中为单个类型成员重写。
你不能给用于协议遵循的扩展显式标注访问权限修饰符。相反,在扩展中使用协议自身的访问权限作为协议实现的默认访问权限。
9.1 扩展中的私有成员
在同一文件中的扩展比如类、结构体或者枚举,可以写成类似多个部分的类型声明。你可以:
- 在原本的声明中声明一个私有成员,然后在同一文件的扩展中访问它;
- 在扩展中声明一个私有成员,然后在同一文件的其他扩展中访问它;
- 在扩展中声明一个私有成员,然后在同一文件的原本声明中访问它。
这样的行为意味着你可以和组织代码一样使用扩展,无论你的类型是否拥有私有成员。比如说,假设下面这样的简单协议:
protocol SomeProtocol {
func doSomething()
}
你可以使用扩展来添加协议遵循,比如这样:
struct SomeStruct {
private var privateVariable = 12
}
extension SomeStruct: SomeProtocol {
func doSomething() {
print(privateVariable)
}
}
10 泛型
泛指类型和泛指函数的访问级别取泛指类型或函数以及泛型类型参数的访问级别的最小值。
11 类型别名
任何你定义的类型同义名都被视为不同的类型以进行访问控制。一个类型同义名的访问级别不高于原类型。例如,一个 private 的类型同义名可联系到 private ,file-private ,internal ,public 或open 的类型,但 public 的类型同义名不可联系到 internal ,file-private 或 private 类型。
高级运算符
作为基本运算符的补充,Swift 提供了一些对值进行更加复杂操作的高级运算符。这些运算包括你在 C 或 Objective-C 所熟悉的所有按位和移位运算符。
与 C 的算术运算符不同,Swift 中算术运算符默认不会溢出。溢出行为都会作为错误被捕获。要允许溢出行为,可以使用 Swift 中另一套默认支持的溢出运算符,比如溢出加法运算符( &+ )。所有这些溢出运算符都是以( & )符号开始的。
当你定义了自己的结构体、类以及枚举的时候,那么为这些自定义类型也提供 Swift 标准的运算符就很有必要。Swift 简化了这些运算符的定制实现并且精确地确定了你创建的每个类型的运算符所具有的行为。
你不会被限制在预定义的运算符里。Swift 允许你自由地定义你自己的中缀、前缀、后缀和赋值运算符,以及相对应的优先级和结合性。这些运算符可以像预先定义的运算符一样在你的代码里使用和采纳,甚至你可以扩展已存在的类型来支持你自己定义的运算符。
1 位运算符
位运算符可以操作数据结构中每一个独立的位。它们通常被用在底层开发中,比如图形编程和创建设备驱动。位运算符在处理外部资源的原始数据时也非常有用,比如为自定义的通信协议的数据进行编码和解码。
Swift 支持 C 里面所有的位运算符,具体如下:
1.1 位取反运算符
位取反运算符( ~ )是对所有位的数字进行取反操作
位取反运算符是一个前缀运算符,需要直接放在运算符的前面,并且不能有空格:
let initialBits: UInt8 = 0b00001111
let invertedBits = ~initialBits // equals 11110000
UInt8 类型的整数有八位,可以存储 0 到 255 之间的任意值。这个例子使用二进制值 00001111 初始化了一个 UInt8 类型的整数,前四位全是 0 ,后四位都是 1 。这和十进制的 15 是相等的。
然后使用位取反运算符创建一个新的常量名为 invertedBits ,它和 initialBits 相等,但是所有位都被取反了。 0 变为了 1 , 1 变为了 。 invertedBits 的值是 11110000 ,和无符号十进制整数 240 相等。
1.2 位与运算符
位与运算符( & )可以对两个数的比特位进行合并。它会返回一个新的数,只有当这两个数都是 1 的时候才能返回 1 。
在下面的例子中, firstSixBits 和 lastSixBits 的中间四个位都为 1 。按位与可以把它们合并为一个新值 00111100 ,对应十进制的值为 60 。
let firstSixBits: UInt8 = 0b11111100
let lastSixBits: UInt8 = 0b00111111
let middleFourBits = firstSixBits & lastSixBits // equals 00111100
1.3 位或运算符
| 位或运算符( | )可以对两个比特位进行比较,然后返回一个新的数,只要两个操作位任意一个为 1 时,那么对应的位数就为 1 : |
在下面的例子中, someBits 和 moreBits 在不同的位设置了 1 。位或运算符把它们合并为 11111110 ,等于十进制无符号整数 154 。
let someBits: UInt8 = 0b10110010
let moreBits: UInt8 = 0b01011110
let combinedbits = someBits | moreBits // equals 11111110
1.4 位异或运算符
位异或运算符,或者说“互斥或”( ^ )可以对两个数的比特位进行比较。它返回一个新的数,当两个操作数的对应位不相同时,该数的对应位就为 1 :
在下面的例子中, firstBits 和 otherBits 的值有一位设置为 1 ,而对方设置为 。位异或运算符会将这两个位上的值设置为 1 , firstBits 和 otherBits 其他位都设置为了 。
let firstBits: UInt8 = 0b00010100
let otherBits: UInt8 = 0b00000101
let outputBits = firstBits ^ otherBits // equals 00010001
2 位左移和右移运算符
位左移运算符( « )和位右移运算符( » )可以把所有位数的数字向左或向右移动一个确定的位数,但是需要遵守下面定义的规则。
位左和右移具有给整数乘以或除以二的效果。将一个数左移一位相当于把这个数翻倍,将一个数右移一位相当于把这个数减半。
2.1 无符号整数的移位操作
对无符号整数的移位规则如下:
- 已经存在的比特位按指定的位数进行左移和右移。
- 任何移动超出整型存储边界的位都会被丢弃。
- 用 0 来填充向左或向右移动后产生的空白位。
这种方法称就是所谓的逻辑移位。
下图展示了 11111111 « 1 (即把 11111111 向左移 1 位), 11111111 » 1 (即把 11111111 向右移 1 位),蓝色的数字是被移位的,灰色的数字被舍弃,橙色的数字 0 是新插入的:
下面的代码展示了 Swift 的移位操作:
let shiftBits: UInt8 = 4 // 00000100 in binary
shiftBits << 1 // 00001000
shiftBits << 2 // 00010000
shiftBits << 5 // 10000000
shiftBits << 6 // 00000000
shiftBits >> 2 // 00000001
可以使用移位操作对其他的数据类型进行编码和解码:
let pink: UInt32 = 0xCC6699 let redComponent = (pink & 0xFF0000) >> 16 // redComponent is 0xCC, or 204 let greenComponent = (pink & 0x00FF00) >> 8 // greenComponent is 0x66, or 102 let blueComponent = pink & 0x0000FF // blueComponent is 0x99, or 153
这个示例使用了一个命名为 pink 的 UInt32 常量来存储层叠样式表[1]中粉色的颜色值。该 CSS 的颜色值 #CC6699 , 在 Swift 中表示为十六进制 0xCC6699 。然后利用位与运算符( & )和位右移运算符( » )从这个颜色值中分解出红( CC )、绿( 66 )以及蓝( 99 )三个部分。
红色部分是通过对 0xCC6699 和 0xFF0000 进行按位与运算后得到的。 0xFF0000 中的 0 部分作为掩码,掩盖了 OxCC6699 中的第二和第三个字节,使得数值中的 6699 被忽略,只留下 0xCC0000 。
然后,再将这个数按向右移动 16 位( » 16 )。十六进制中每两个字符表示 8 个比特位,所以移动 16 位后 0xCC0000 就变为 0x0000CC 。这个数和 0xCC 是等同的,也就是十进制数值的 204 。
同样的,绿色部分通过对 0xCC6699 和 0x00FF00 进行按位与运算得到 0x006600 。然后将这个数向右移动 8 位,得到 0x66 ,也就是十进制数值的 102 。
最后,蓝色部分通过对 0xCC6699 和 0x0000FF 进行按位与运算得到 0x000099 。并且不需要进行向右移位,所以结果为 0x99 ,也就是十进制数值的 153 。
2.2 有符号整型的位移操作
对比无符号整型来说有符整型的移位操作相对复杂得多,这种复杂性源于有符号整数的二进制表现形式。(为了简单起见,以下的示例都是基于 8 位有符号整数的,但是其中的原理对大小的有符号整数都是一样的。)
有符号整型使用它的第一位(所谓的符号位)来表示这个整数是正数还是负数。符号位为 表示为正数, 1 表示为负数。
其余的位数(所谓的数值位)存储了实际的值。有符号正整数和无符号数的存储方式是一样的,都是从 0 开始算起。这是值为 4 的 Int8 型整数的二进制位表现形式:
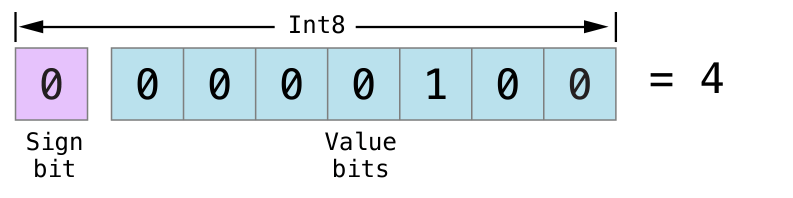
符号位是 0 (意味着是一个正数),另外七位则代表了十进制数值 4 的二进制表示。
但是负数的存储方式略有不同。它存储的是 2 的 n 次方减去它的绝对值,这里的 n 为数值位的位数。一个 8 位的数有七个数值位,所以是 2 的 7 次方,或者说 128 。
这是值为 -4 的 Int8 型整数的二进制位表现形式:
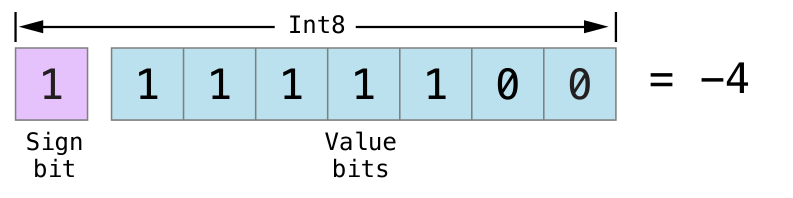
这次,符号位为 1 (说明是负数),另外七个位则代表了数值 124 (即 128 - 4 ) 的二进制表示:
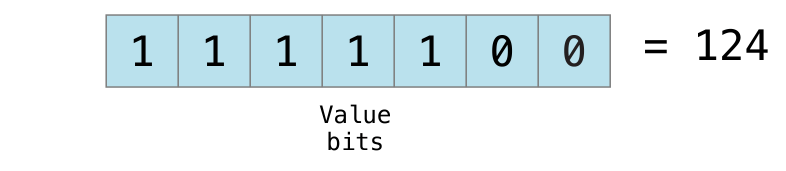
负数的编码就是所谓的二进制补码表示。用这种方法来表示负数乍看起来有点奇怪,但它有几个优点。
首先,如果想给 -4 加个 -1 ,只需要将这两个数的全部八个比特位相加(包括符号位),并且将计算结果中超出的部分丢弃:
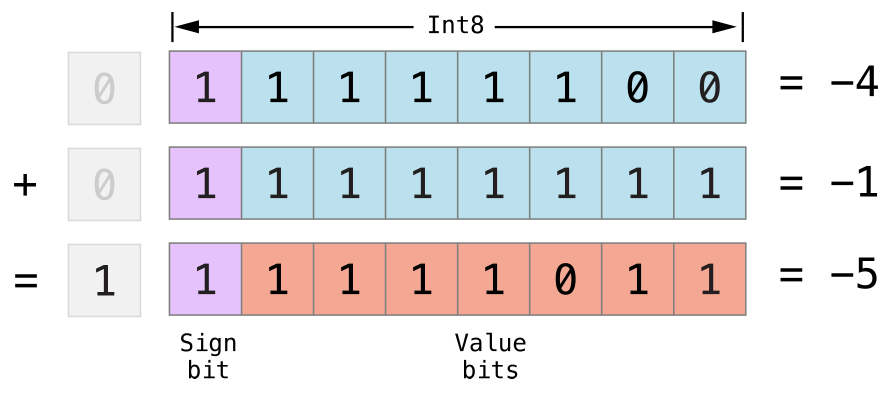
其次,使用二进制补码可以使负数的位左移和右移操作得到跟正数同样的效果,即每向左移一位就将自身的数值乘以 2 ,每向右一位就将自身的数值除以 2 。要达到此目的,对有符号整数的右移有一个额外的规则:当对正整数进行位右移操作时,遵循与无符号整数相同的规则,但是对于移位产生的空白位使用符号位进行填充,而不是 0 。
这个行为可以确保有符号整数的符号位不会因为右移操作而改变,这就是所谓的算术移位。
由于正数和负数的特殊存储方式,在对它们进行右移的时候,会使它们越来越接近零。在移位的过程中保持符号位不变,意味着负整数在接近零的过程中会一直保持为负。
3 溢出运算符
在默认情况下,当向一个整数赋超过它容量的值时,Swift 会报错而不是生成一个无效的数。这个行为给我们操作过大或着过小的数的时候提供了额外的安全性。
例如, Int16 整数能容纳的有符号整数范围是 -32768 到 32767 ,当为一个 Int16 型变量赋的值超过这个范围时,系统就会报错:
var potentialOverflow = Int16.max
// potentialOverflow equals 32767, which is the maximum value an Int16 can hold
potentialOverflow += 1
// this causes an error
为过大或者过小的数值提供错误处理,能让我们在处理边界值时更加灵活。
总之,当你故意想要溢出来截断可用位的数字时,也可以选择这么做而非报错。Swift 提供三个算数溢出运算符来让系统支持整数溢出运算。这些运算符都是以 & 开头的:
- 溢出加法 ( &+ )
- 溢出减法 ( &- )
- 溢出乘法 ( &* )
3.1 值溢出
数值可能出现向上溢出或向下溢出。
这个示例演示了当对一个无符号整数使用溢出加法( &+ )进行上溢运算时会发生什么:
var unsignedOverflow = UInt8.max
// unsignedOverflow equals 255, which is the maximum value a UInt8 can hold
unsignedOverflow = unsignedOverflow &+ 1
// unsignedOverflow is now equal to 0
unsignedOverflow 初始化为 UInt8 所能容纳的最大整数( 255 ,二进制为 11111111 )。溢出加法运算符( &+ )对其进行加 1 操作。这使得它的二进制表示正好超出 UInt8 所能容纳的位数,也就导致它溢出了边界,如下图所示。溢出后,留在 UInt8 边界内的值是 00000000 ,也就是十进制数值的 0 。
同样地,当我们对一个无符号整数使用溢出减法( &- )进行下溢运算时也会产生类似的现象:
var unsignedOverflow = UInt8.min
// unsignedOverflow equals 0, which is the minimum value a UInt8 can hold
unsignedOverflow = unsignedOverflow &- 1
// unsignedOverflow is now equal to 255
UInt8 型整数能容纳的最小值是 ,以二进制表示即 00000000 。当使用溢出减法运算符( &- )对其进行减 1 操作时,数值会产生下溢并被截断为 11111111 , 也就是十进制数值的 255 。
溢出也会发生在有符号整型数值上。正如按位左移/右移运算符所描述的,在对有符号整型数值进行溢出加法或溢出减法运算时,符号位也需要参与计算。
var signedOverflow = Int8.min
// signedOverflow equals -128, which is the minimum value an Int8 can hold
signedOverflow = signedOverflow &- 1
// signedOverflow is now equal to 127
Int8 整数能容纳的最小值是 -128 ,以二进制表示即 10000000 。当使用溢出减法运算符对其进行减 1 操作时,符号位翻转,得到二进制数值 01111111 ,也就是十进制数值的 127 ,这个值也是 Int8 型整数所能容纳的最大值。
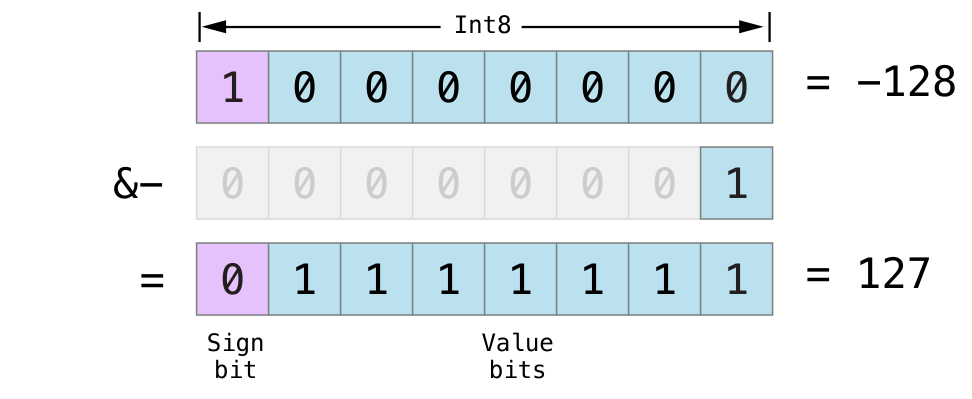
对于无符号与有符号整型数值来说,当出现上溢时,它们会从数值所能容纳的最大数变成最小的数。同样地,当发生下溢时,它们会从所能容纳的最小数变成最大的数。
4 优先级和结合性
运算符的优先级使得一些运算符优先于其他运算符,高优先级的运算符会先被计算。
结合性定义了具有相同优先级的运算符是如何结合(或关联)的 —— 是与左边结合为一组,还是与右边结合为一组。可以这样理解:“它们是与左边的表达式结合的”或者“它们是与右边的表达式结合的”。
在复合表达式的运算顺序中,运算符的优先级和结合性是非常重要的。举例来说,为什么下面这个表达式的运算结果是 17 ?
2 + 3 % 4 * 5
// this equals 17
如果严格地从左到右进行运算,则运算的过程是这样的:
- 2 + 3 = 5
- 5 % 4 = 1
- 1 * 5 = 5
然而正确的答案是 17 ,而不是 5 。优先级高的运算符要先于优先级低的运算符进行计算。与 C 语言类似,在 Swift 中,取余运算符( % )和乘法运算符( * )的优先级高于加法运算符( + )。因此,它们的计算顺序要先于加法运算。
但是,取余和乘法具有相同的优先级。这时为了得到正确的运算顺序,还需要考虑结合性,乘法与取余运算都是左结合的。可以将这考虑成为这两部分表达式都隐式地加上了括号:
2 + ((3 % 4) * 5)
2 + (3 * 5)
2 + 15
此时可以容易地看出计算的结果为 17 。
如果想查看完整的 Swift 运算符优先级和结合性规则,请参考表达式。以及 Swift 标准库中的运算符。
5 运算符函数
类和结构体可以为现有的运算符提供自定义的实现,这通常被称为运算符重载。
下面的例子展示了如何为自定义的结构实现加法运算符( + )。算术加法运算符是一个二元运算符,因为它可以对两个目标进行操作,同时它还是中缀运算符,因为它出现在两个目标中间。
例子中定义了一个名为 Vector2D 的结构体用来表示二维坐标向量 (x, y) ,紧接着定义了一个可以对两个 Vector2D 结构体进行相加的运算符方法:
struct Vector2D {
var x = 0.0, y = 0.0
}
extension Vector2D {
static func + (left: Vector2D, right: Vector2D) -> Vector2D {
return Vector2D(x: left.x + right.x, y: left.y + right.y)
}
}
该运算符函数被定义为一个全局函数,并且函数的名字与它要进行重载的 + 名字一致。因为算术加法运算符是双目运算符,所以这个运算符函数接收两个类型为 Vector2D 的输入参数,同时有一个 Vector2D 类型的返回值。
在这个实现中,输入参数分别被命名为 left 和 right ,代表在 + 运算符左边和右边的两个 Vector2D 对象。函数返回了一个新的 Vector2D 的对象,这个对象的 x 和 y 分别等于两个参数对象的 x 和 y 的值之和。
这个函数被定义成全局的,而不是 Vector2D 结构的成员方法,所以任意两个 Vector2D 对象都可以使用这个中缀运算符:
let vector = Vector2D(x: 3.0, y: 1.0)
let anotherVector = Vector2D(x: 2.0, y: 4.0)
let combinedVector = vector + anotherVector
// combinedVector is a Vector2D instance with values of (5.0, 5.0)
5.1 前缀和后缀运算符
上个例子演示了一个二元中缀运算符的自定义实现。类与结构体也能提供标准一元运算符的实现。单目运算符只有一个操作目标。当运算符出现在目标之前,它就是前缀(比如 -a ),当它出现在操作目标之后时,它就是后缀运算符(比如 b! )。
要实现前缀或者后缀运算符,需要在声明运算符函数的时候在 func 关键字之前指定 prefix 或者 postfix 限定符:
extension Vector2D {
static prefix func - (vector: Vector2D) -> Vector2D {
return Vector2D(x: -vector.x, y: -vector.y)
}
}
这段代码为 Vector2D 类型实现了单目减运算符( -a )。由于单目减运算符是前缀运算符,所以这个函数需要加上 prefix 限定符。
对于简单数值,单目减运算符可以对它们的正负性进行改变。对于 Vector2D 来说,单目减运算将其 x 和 y 属性的正负性都进行了改变。
let positive = Vector2D(x: 3.0, y: 4.0)
let negative = -positive
// negative is a Vector2D instance with values of (-3.0, -4.0)
let alsoPositive = -negative
// alsoPositive is a Vector2D instance with values of (3.0, 4.0)
5.2 组合赋值运算符
组合赋值运算符将赋值运算符( = )与其它运算符进行结合。比如,将加法与赋值结合成加法赋值运算符( += )。在实现的时候,需要把运算符的左参数设置成 inout 类型,因为这个参数的值会在运算符函数内直接被修改。
下面的例子实现了一个 Vector2D 的加赋值运算符:
extension Vector2D {
static func += (left: inout Vector2D, right: Vector2D) {
left = left + right
}
}
因为加法运算在之前已经定义过了,所以在这里无需重新定义。在这里可以直接利用现有的加法运算符函数,用它来对左值和右值进行相加,并再次赋值给左值:
var original = Vector2D(x: 1.0, y: 2.0)
let vectorToAdd = Vector2D(x: 3.0, y: 4.0)
original += vectorToAdd
// original now has values of (4.0, 6.0)
5.3 等价运算符
自定义类和结构体不接收等价运算符的默认实现,也就是所谓的“等于”运算符( == )和“不等于”运算符( != )。
要使用等价运算符来检查你自己类型的等价,需要和其他中缀运算符一样提供一个“等于”运算符,并且遵循标准库的 Equatable 协议:
extension Vector2D: Equatable {
static func == (left: Vector2D, right: Vector2D) -> Bool {
return (left.x == right.x) && (left.y == right.y)
}
}
上面的例子实现了一个“等于”运算符( == )来检查两个 Vector2D 实例是否拥有相同的值。在 Vector2D 上下文中,“等于”作为“两个实例都具有相同的 x 值和 y 值”是有意义的,因此这个逻辑用作运算符的实现。标准库提供了一个关于“不等于”运算符( != )的默认实现,它仅仅返回“等于”运算符的相反值。
现在你就可以用这些运算符来检查 Vector2D 实例是否等价了:
let twoThree = Vector2D(x: 2.0, y: 3.0)
let anotherTwoThree = Vector2D(x: 2.0, y: 3.0)
if twoThree == anotherTwoThree {
print("These two vectors are equivalent.")
}
// Prints "These two vectors are equivalent."
Swift 为以下自定义类型提等价运算符供合成实现:
- 只拥有遵循 Equatable 协议存储属性的结构体;
- 只拥有遵循 Equatable 协议关联类型的枚举;
- 没有关联类型的枚举。
在类型原本的声明中声明遵循 Equatable 来接收这些默认实现。
下面为三维位置向量 (x, y, z) 定义的 Vector3D 结构体,与 Vector2D 类似,由于 x , y 和 z 属性都是 Equatable 类型, Vector3D 就收到默认的等价运算符实现了。
struct Vector3D: Equatable {
var x = 0.0, y = 0.0, z = 0.0
}
let twoThreeFour = Vector3D(x: 2.0, y: 3.0, z: 4.0)
let anotherTwoThreeFour = Vector3D(x: 2.0, y: 3.0, z: 4.0)
if twoThreeFour == anotherTwoThreeFour {
print("These two vectors are also equivalent.")
}
// Prints "These two vectors are also equivalent."
6 自定义运算符
除了实现标准运算符,在 Swift 当中还可以声明和实现自定义运算符(custom operators)。可以用来自定义运算符的字符列表请参考运算符
新的运算符要在全局作用域内,使用 operator 关键字进行声明,同时还要指定 prefix 、 infix 或者 postfix 限定符:
prefix operator +++ {}
上面的代码定义了一个新的名为 +++ 的前缀运算符。这个运算符在 Swift 中并没有意义,我们针对 Vector2D 的实例来赋予它意义。对这个例子来讲, +++ 作为“前缀翻倍”运算符。它让 Vector2D 实例的 x 属性和 y 属性的值翻倍,使用前面定义的复合加法运算符来让向量对自身进行相加。要实现+++运算符,添加一个叫做 +++ 的类型方法到 Vector2D :
extension Vector2D {
static prefix func +++ (vector: inout Vector2D) -> Vector2D {
vector += vector
return vector
}
}
var toBeDoubled = Vector2D(x: 1.0, y: 4.0)
let afterDoubling = +++toBeDoubled
// toBeDoubled now has values of (2.0, 8.0)
// afterDoubling also has values of (2.0, 8.0)
6.1 自定义中缀运算符的优先级和结合性
自定义的中缀( infix )运算符也可以指定优先级和结合性。优先级和结合性中详细阐述了这两个特性是如何对中缀运算符的运算产生影响的。
结合性( associativity )可取的值有 left , right 和 none 。当左结合运算符跟其他相同优先级的左结合运算符写在一起时,会跟左边的操作数进行结合。同理,当右结合运算符跟其他相同优先级的右结合运算符写在一起时,会跟右边的操作数进行结合。而非结合运算符不能跟其他相同优先级的运算符写在一起。
associativity 的默认值是 none , precedence 默认为 100 。
下面例子定义了一个新的自定义中缀运算符 +- ,此运算符是 left 结合的,优先级为 140 :
infix operator +- { associativity left precedence 140 }
extension Vector2D {
static func +- (left: Vector2D, right: Vector2D) -> Vector2D {
return Vector2D(x: left.x + right.x, y: left.y - right.y)
}
}
let firstVector = Vector2D(x: 1.0, y: 2.0)
let secondVector = Vector2D(x: 3.0, y: 4.0)
let plusMinusVector = firstVector +- secondVector
// plusMinusVector is a Vector2D instance with values of (4.0, -2.0)
这个运算符把两个向量的 x 值相加,同时用第一个向量的 y 值减去第二个向量的 y 值。因为它本质上是属于“加”运算符,所以将它的结合性和优先级被设置与 + 和 - 等默认的中缀加型运算符是相同的( left 和 140 )。完整的 Swift 运算符默认结合性与优先级请参考Swift 标准库运算符引用。